本文已翻译成中文。
我将根据收到的建设性反馈(并注明出处)更新这篇文章——尽管我已努力主要坚持我的专业领域(数据科学),但我不得不触及一些我并非专家的领域,所以如果你发现任何问题,请务必告诉我。你可以在 Twitter 上联系我:@jeremyphoward.
引言
除非你这几天去了外星球,否则你可能已经读过了斯坦福大学的论文 深度神经网络可以从面部检测性取向。这篇预印本论文引起了许多反响,例如欧柏林学院社会学教授 Greggor Mattson,他将自己的回应总结为 AI 无法判断你是否是同性恋……但能判断你是否是一个行走的刻板印象。
当我第一次读到这项研究时,我产生了强烈的负面情绪反应。这个话题对我个人来说非常重要——Rachel Thomas 和我明确创建 fast.ai 的目的就是为了增加深度学习领域(包括本研究所使用的深度神经网络)的多样性,我们甚至亲自 为多元背景的学生提供奖学金,包括 LGBTQ 学生。此外,我们希望支持深度学习在更广泛领域的应用,因为我们相信它既能积极也能消极地影响许多人的生活,所以我们希望展示如何恰当正确地使用这项技术。
像许多评论员一样,我对这项研究有许多基本的担忧。它是否根本就不应该进行?数据收集是否侵犯了隐私?参与这项工作的都是合适的人吗?结果的沟通是否周到且敏感?这些都是重要的问题,并非任何个人都能回答。因为深度学习使计算机能够做到以前不可能做到的事情,我们将看到越来越多的领域会出现这些问题。因此,我们需要更多跨学科团队进行更多跨学科研究。在本例中,研究人员是数据科学家和心理学家,但这篇论文涵盖的主题(并声称得出的结论)涉及从社会学到生物学等领域。
那么,这篇论文到底展示了什么——神经网络能像声称的那样做到吗?我们将以数据科学家的视角——通过查看数据——来分析这个问题。
总结
这篇论文(“深度神经网络可以从面部检测性取向”)和回应(“AI 无法判断你是否是同性恋”)的关键结论并未得到研究所展示的支持。得到支持的是一个较弱的主张:在某些情况下,深度神经网络可以从某些异性恋约会网站用户的照片中识别出某些同性恋约会网站用户的照片。我们绝对不能说“AI 无法判断你是否是同性恋”,事实上,做出这种主张是不负责任的:这篇论文至少显示出一些迹象表明其反面很可能是真实的,并且这项技术很容易被任何政府或组织获取和使用。
这篇论文的资深研究员 Michael Kosinski 过去曾成功地警告过我们类似的问题:他的论文 从人类行为的数字记录中可预测个人特质和属性 是有史以来引用次数最多的论文之一,并且至少在一定程度上促使 Facebook 改变了将“赞”默认公开的政策。如果这项新研究中的关键结果确实是正确的,那么我们当然应该讨论它具有哪些政策影响。如果你生活在一个同性恋可能被判处死刑的国家,那么你需要意识到基于你的社交媒体照片,你可能会被标记进行额外的监控。如果你无法公开你的性偏好,你应该意识到机器学习推荐系统可能会(甚至可能是无意中)向你推送针对同性恋群体的商品。
然而,这篇论文得出了许多其他结论,这些结论与这个关键问题没有直接关联,没有得到研究的明确支持,并且被夸大且沟通不当。特别是,论文声称研究支持“广泛接受的”产前激素理论(PHT),即“同性性取向源于男性胎儿对负责性分化的雄激素暴露不足或女性胎儿暴露过度”。论文中对此的支持远非严谨,应被视为不确定的。此外,社会学家 Greggor Mattson 表示,该理论不仅没有被广泛接受,而且“该领域一篇已有十年历史的综述的字面第一句话就是‘公众对睾酮对“男性化”行为影响的看法是不准确的’”。
这项研究是如何进行的?
论文中提出了一些研究,但关键的是“研究 1a”。在这项研究中,研究人员从一个约会网站下载了平均每人 5 张图片,共计 70,000 人的图片。这项研究收集的数据没有公开,尽管几乎任何程序员都可以轻松复制(事实上许多程序员过去已经创建了类似的数据集)。因为这项研究的重点是检测面部性取向,他们将照片裁剪到面部区域。他们还删除了包含多人、面部不清晰或没有正对镜头的照片。这里的技术方法非常标准和可靠,使用了广泛使用的开源软件 Face++。
然后,他们删除了由一群非专业工作者(使用亚马逊的 Mechanical Turk 系统)判断为非成人或非高加索人的任何图片。不完全清楚他们为什么这样做;最有可能的是他们认为处理更多类型的面部会使训练模型变得更困难。
重要的是要认识到,像这样用于“清洗”数据集的步骤对于几乎所有数据科学项目都是必需的,但它们很少是完美的——而且这些不完美通常在理解研究的准确性方面并不重要。对于评估来说重要的是确信报告的最终指标得到了恰当的评估。稍后会有更多介绍……
他们根据每个约会资料列出的性偏好将每个人标记为同性恋或非同性恋。
研究人员随后使用一个深度神经网络(VGG-Face)来创建特征。具体来说,每张图像都被转化为 4096 个数字,这些数字都经过牛津大学研究人员的训练,以便尽可能好地从面部识别人类。他们使用一种称为 SVD 的简单统计技术将这 4096 个数字压缩到 500 个,然后使用一个简单的回归模型将这 500 个数字映射到标签(同性恋或非同性恋)。
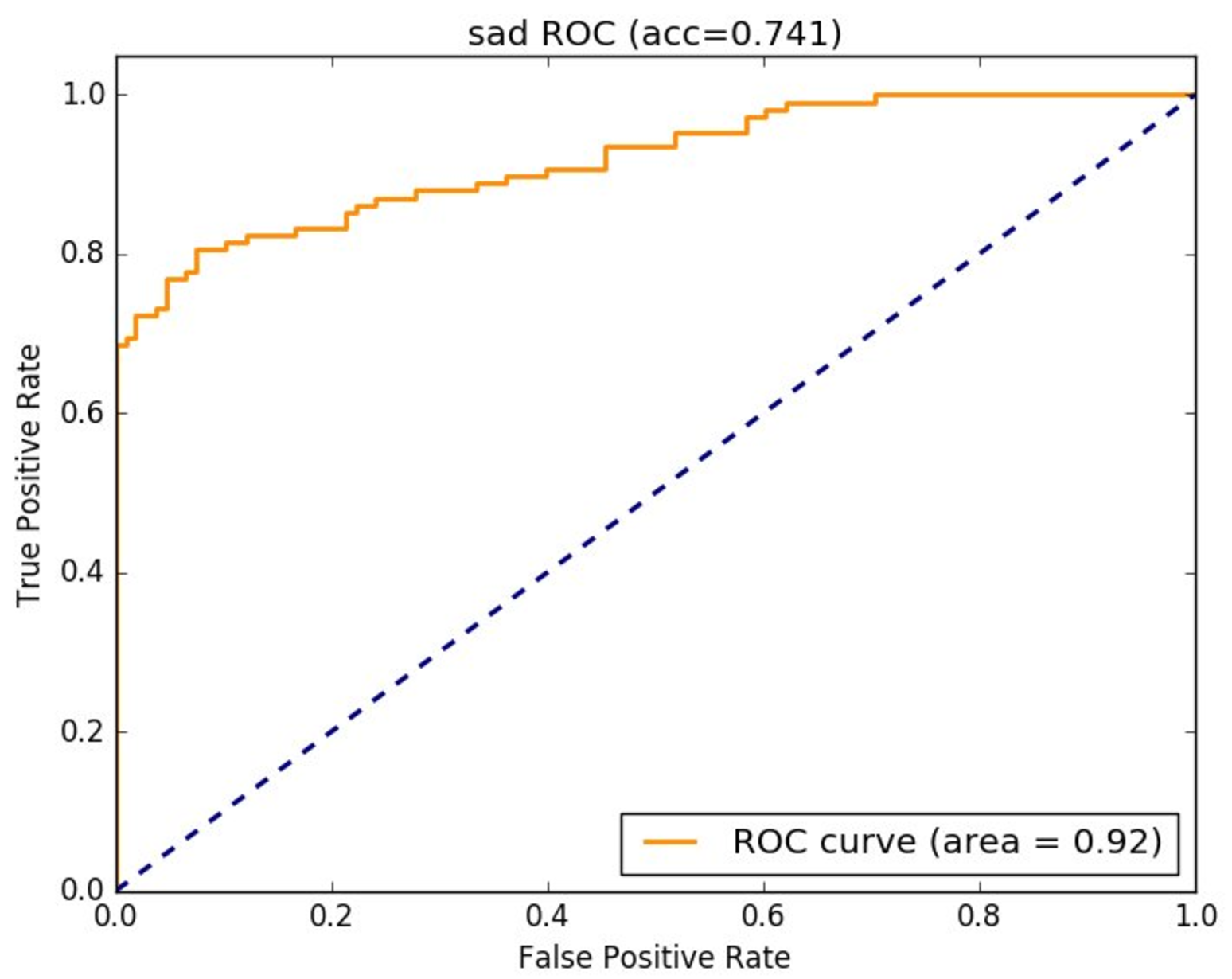
他们重复了回归过程 10 次。每次都使用不同的 90% 数据子集,并使用剩余的 10% 数据测试模型(这称为交叉验证)。这十个模型使用一种称为 AUC 的指标进行评分,这是评估此类分类模型的标准方法。数据集中被标记为男性的 AUC 为 0.91。
这个模型有多准确?
研究人员将他们的模型描述为“91% 准确”。这是基于 AUC 分数 0.91。然而,使用“准确性”一词来描述 AUC 非常不寻常且相当误导。研究人员已经澄清,模型的实际准确性可以这样理解:如果你在该研究中选取模型得分最高的 10% 的人,根据收集到的标签,大约一半实际上是同性恋。如果同性恋男性的实际比例是 7%,那么这表明模型比随机预测好得多。然而,如果大多数人听说某个东西“91% 准确”,它可能不如他们想象的那么准确。
同样重要的是要注意,基于这项研究(研究 1a),我们只能说该模型可以识别某个网站上被非专业人士标记为成人高加索人的同性恋约会资料照片,而不能说它能识别一般的同性恋照片。该模型很可能能够泛化到其他类似群体,但从这项研究中我们不知道这些群体需要有多相似,以及它的准确性会如何。
研究人员是否在这里创造了新技术?
本研究所使用的方法正是我们在深度学习入门课程中教授的第一种技术。我们的课程不需要高深的数学背景——只需要高中数学水平。因此,这里使用的方法字面上是任何具备高中数学水平、一小时免费在线学习和基本编程知识的人都能做到的。
以这种方式训练的模型在商品服务器上运行不到 20 秒,这种服务器每小时租金仅为 0.90 美元。因此,它不需要任何特殊或昂贵的资源。任何具备基本编程技能的人都可以轻松地从约会网站下载数据。
研究人员表示,他们的研究揭示了一个潜在的隐私问题。考虑到他们使用的技术非常易于获取,如果你认为研究所展示的能力令人担忧,那么这个主张似乎是合理的。
很可能可以合理地假设许多组织已经完成了类似的项目,只是没有在学术文献中发表。这篇论文展示了已经可以轻松完成的事情——它并未创造新技术。营销人员利用社交媒体数据来推广产品正变得越来越普遍;在这种情况下,模型只是简单地寻找产品销售与可用的社交媒体数据之间的相关性。在这种情况下,模型很容易隐含地发现某些照片与针对同性恋市场的产品之间的关系,而开发者甚至没有意识到建立了这种联系。事实上,我们以前也见过一些类似的问题,例如文章 Target 如何在她父亲之前发现一个十几岁女孩怀孕了 中描述的情况。
模型是否显示同性恋者的面部在物理上有所不同?
在研究 1b 中,研究人员遮盖了每张图像的不同部分,以查看遮盖哪些部分会导致预测发生变化。这是理解输入的不同部分对神经网络的相对重要性的常用技术。
这项分析的结果显示在论文的这张图片中

红色区域对模型来说相对比蓝色区域更重要。然而,这项分析并未显示重要程度有多大,也未说明红色区域为何或以何种方式更重要。
在研究 1c 中,他们试图为男性和女性以及同性恋和异性恋群体分别创建“平均面孔”。研究的这一部分缺乏严谨的分析,完全依赖于对所示图片的直观观察。从数据科学的角度来看,这一部分无法获得额外的信息。
研究人员声称这些研究支持产前激素理论。然而,没有提供任何数据来显示该理论是如何得到支持的,或提供了何种程度的支持,也没有探究对观察结果可能存在的替代理论。
这个模型比人类更准确吗?
研究人员在摘要的第一句话中声称,“面部包含关于性取向的信息比人类大脑能够感知和解释的要多得多”。他们将此主张基于研究 4,在该研究中,他们要求人类对与研究 1a 相同数据集中的图像进行分类。然而,这项研究完全未能提供足够的方法来支持该主张。斯坦福大学研究员 Andrej Karpathy(现任职于 Tesla)展示了一种相当严谨的方法来 比较人类图像分类与神经网络。关键在于给予人类与计算机相同的机会来研究训练数据。在这种情况下,这意味着在要求人类自己对面部进行分类之前,让他们研究数据集中收集到的面部和标签的许多示例。
由于未能提供这个“人类训练”步骤,人类和计算机用于完成任务的信息非常不同。即使方法更好,除了他们决定作为论文开篇的那个非常强烈且未经支持的主张之外,仍然会有许多可能的解释。
通常来说,学术主张应该谨慎、严谨地提出,并经过深思熟虑地传达。尤其是在论文开头时。特别是在如此敏感的领域时。特别特别是在涵盖研究人员专业领域之外的领域时。关于这篇论文的这个问题,在一篇 Calling Bullshit 案例研究 中有周到的讨论。
这个分类器对除一个网站上的约会照片之外的其他图像有效吗?
简而言之:我们不知道。论文中的研究 5 声称是,但它没有为这个主张提供强有力的支持,并且设置方式异常复杂。研究 5 使用的方法是寻找一些“超级同性恋”Facebook 用户的照片:这些人列出了同性伴侣,并且至少喜欢两个页面,例如“Manhunt”和“我爱做同性恋”。然后他们试图训练一个分类器,来区分这些照片与异性恋约会网站用户的照片。这个分类器声称的准确率为 74%,尽管这个 74% 的具体含义没有列出。如果它指的是 AUC 为 0.74(这是研究人员在论文前面提到 AUC 的方式),那这不是一个强有力的结果。它还在跨数据集(Facebook vs 约会网站)进行比较,并且使用了一种非常特殊的 Facebook 个人资料进行测试。
研究人员表示,他们没有与异性恋资料照片进行比较,因为他们不知道如何找到。
他们的结论是否得到了研究的支持?
在“一般讨论”部分,研究人员得出了一些结论。所有声称的结论都比从所示研究结果中能得出的结论更强。然而,我们至少可以说(假设他们的数据分析是正确完成的,考虑到我们无法访问他们的数据或代码,我们无法确认这一点),在某些情况下,某些照片中人物的性偏好可以比随机猜测更好地被识别。
他们总结说,他们的模型不仅仅是找出两组之间在表现上的差异,而是确实显示出潜在面部结构的差异。这一主张部分基于他们使用的 VGG-Face 模型经过训练以识别非瞬时面部特征的断言。然而,一些简单的数据分析很容易表明这一断言是不正确的。维多利亚大学的研究员 Tom White 分享了一项分析,显示完全相同的模型,例如,可以以高于这篇论文所示模型(AUC 0.91)的 AUC (0.92) 从中性面部识别出快乐面部(并且能以更高的 AUC 0.96 从悲伤面部识别出快乐面部)。
这篇论文是否混淆了相关性和因果关系?
每当社会科学家的论文引起程序员群体的注意(例如在编程论坛上分享时),我们不可避免地会听到“相关性不是因果关系”的呼声。这篇论文也发生了这种情况。这意味着什么,这里有问题吗?当然,XKCD 已经涵盖了这一点

相关性是指观察到两件事同时发生。例如,你可能会注意到,在人们购买更多冰淇淋的日子里,他们也购买更多防晒霜。有时人们错误地认为这种观察暗示着因果关系——在这种情况下,认为吃冰淇淋导致人们想要防晒霜。当事件 x(购买冰淇淋)和事件 y(购买防晒霜)之间观察到相关性时,主要有三种可能性:
x 导致 y
y 导致 x
其他事物同时导致 x 和 y(可能间接)
纯粹偶然(我们可以衡量发生的概率——在本研究中概率极低)
在这个例子中,当然是温暖晴朗的天气既引发了想吃冰淇淋的欲望,也引发了对防晒霜的需求。
许多社会科学领域都涉及这个问题。这些领域的研究人员常常需要在存在许多混杂因素的情况下,从观察性研究中得出结论。这是一项复杂且具有挑战性的任务,结果往往不完美。对于数学家和计算机科学家来说,社会科学领域的结果有时显得基础薄弱,令人恼火。在数学中,如果你想声称,例如,对于任何大于 2 的整数 n,没有三个正整数 a、b 和 c 满足方程 an + bn = cn,那么即使你尝试了数百万对 a、b 和 c 的值并表明它们都不满足这个关系,这也不重要——你必须证明它对所有可能的整数都成立。但在社会科学中,通常无法得到这种类型的结果。因此,我们必须努力权衡证据的平衡与我们对结果的先验预期。
斯坦福大学的论文试图通过使用各种研究(如上文讨论)来区分相关性和因果关系。最终,他们做得并不出色。但简单地说“相关性不是因果关系”是一种敷衍的回应。相反,需要提供替代理论,最好有证据支持:也就是说,你能否提出 y 导致 x,或者有其他因素同时导致 x 和 y 的主张,并证明你的替代理论得到了论文中所示研究的支持?
此外,我们需要考虑一个简单的问题:这真的重要吗?例如,如果政府(或过于热心的营销人员)可以根据面部照片对面部进行性取向分类,那么无论识别出的差异是由仪容、面部表情还是面部结构造成的,这难道不是一个重要的结果吗?
我们应该担心隐私问题吗?
论文最后警告说,政府已经在利用精密的技术来推断公民的私密特征,只有通过这样的研究,我们才能猜测他们拥有何种能力。他们声明:
推迟或放弃发表这些发现可能会剥夺个人采取预防措施的机会,以及决策者制定法律保护人们的能力。此外,这项工作除了强调其工作的伦理影响外,并未为可能正在开发或部署分类算法的人提供任何优势。我们使用了广泛可用的现成工具、公开数据以及计算机视觉从业者熟知的方法。我们没有创造一个侵犯隐私的工具,而是表明基本且广泛使用的方法构成了严重的隐私威胁。
这些是真实的担忧,我们都应该了解可能被用于减少隐私的工具类型,这显然是一件好事。令人遗憾的是,夸大的主张、薄弱的跨学科研究和方法论问题模糊了这个重要问题。