有一种强大的技术,它赢得了Kaggle比赛,并被广泛应用于Google(据Jeff Dean所说)、Pinterest和Instacart,然而许多人甚至没有意识到这是可能的:将深度学习用于表格数据,特别是创建分类变量的嵌入。
尽管你可能听说过,你确实可以将深度学习用于你可能保存在SQL数据库、Pandas DataFrame或Excel电子表格中的数据类型(包括时间序列数据)。我将其称为表格数据,尽管它也可以称为关系型数据、结构化数据或其他术语(更多讨论请参阅我的twitter投票和评论)。
表格数据是行业中最常用的数据类型,但针对表格数据的深度学习受到的关注远少于计算机视觉和自然语言处理的深度学习。本文涵盖了将神经网络应用于表格数据的一些关键概念,特别是为分类变量创建嵌入的思想,并重点介绍了fastai库中的两个相关模块。
fastai.structured:这个模块与Pandas DataFrame一起工作,不依赖于PyTorch,可以独立于fastai库的其他部分使用,用于处理和操作表格数据。fastai.column_data:这个模块也与Pandas DataFrame一起工作,并提供方法将DataFrame(包含连续和分类变量)转换为ModelData对象,以便在训练神经网络时轻松使用。它还包含了创建分类变量嵌入的实现,这是一个我将在下面解释的强大技术。
本文中的材料在我们的免费在线课程面向程序员的实用深度学习的课程3视频约1:59:45处开始,并在课程4中继续有更详细的介绍。要查看此方法在实践中如何使用的示例代码,请查看我们的课程3 jupyter notebook。
分类变量的嵌入
充分利用深度学习处理表格数据的一个关键技术是使用分类变量的嵌入。这种方法可以捕捉类别之间的关系。例如,周六和周日可能有相似的行为,而周五可能表现得像周末和工作日的平均值。类似地,对于邮政编码,地理位置相邻的邮政编码之间可能存在模式,经济社会地位相似的邮政编码之间也可能存在模式。
从词嵌入中获取灵感
捕捉这些类别之间多维关系的一种方法是使用嵌入。这与词嵌入(如Word2Vec)中使用的思想相同。例如,一个3维版本的词嵌入可能看起来像这样:
|——–|—————–|
| puppy | [0.9, 1.0, 0.0] |
| dog | [1.0, 0.2, 0.0] |
| kitten | [0.0, 1.0, 0.9] |
| cat | [0.0, 0.2, 1.0] |
请注意,第一个维度捕捉了与狗相关的信息,第二个维度捕捉了幼小的特征。这个例子是手工编造的,但在实践中,你会使用机器学习来找到最佳表示(虽然像“狗性”和“幼小”这样的语义值会被捕捉到,但它们可能不会如此清晰地与单一维度对齐)。有关词嵌入工作原理的更多细节,你可以查看我的词嵌入研讨会。
应用分类变量的嵌入
类似地,在使用分类变量时,我们将每个类别表示为一个浮点数向量(这些表示的值在网络训练时学习)。
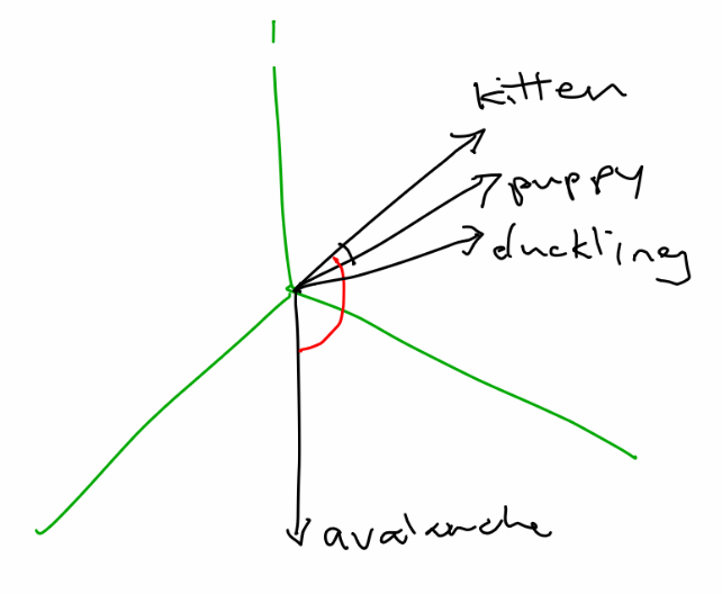
例如,表示星期几的4维嵌入可能看起来像这样:
|———|———————-|
| Sunday | [.8, .2, .1, .1] |
| Monday | [.1, .2, .9, .9] |
| Tuesday | [.2, .1, .9, .8] |
这里,周一和周二非常相似,但它们都与周日完全不同。同样,这只是一个玩具示例。在实践中,我们的神经网络会在训练时学习每个类别的最佳表示,并且每个维度(或方向,它不一定与有序维度对齐)可以具有多种含义。这些分布式表示可以捕捉丰富的关系。
重用预训练的分类嵌入
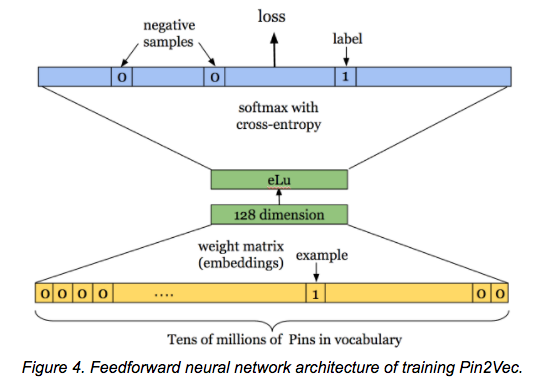
嵌入比原始类别能捕捉更丰富的关系和复杂性。一旦你学到了在业务中常用的类别(例如产品、商店ID或邮政编码)的嵌入,你就可以将这些预训练的嵌入用于其他模型。例如,Pinterest在一个名为Pin2Vec的库中为其图钉创建了128维的嵌入,而Instacart则为其杂货商品、商店和客户创建了嵌入。
fastai库包含了分类变量的实现,它与PyTorch的nn.Embedding模块一起工作,因此你每次使用时无需手动编写代码。
将一些连续变量视为分类变量
我们通常建议将月份、年份、星期几以及其他一些变量视为分类变量,即使它们可以被视为连续变量。通常对于类别数量相对较少的变量,这样做会带来更好的性能。这是数据科学家做出的建模决策。一般来说,我们希望将由浮点数表示的连续变量保留为连续。
虽然我们可以选择将连续变量视为分类变量,但反之则不然:任何本身就是分类的变量必须被视为分类变量。
时间序列数据
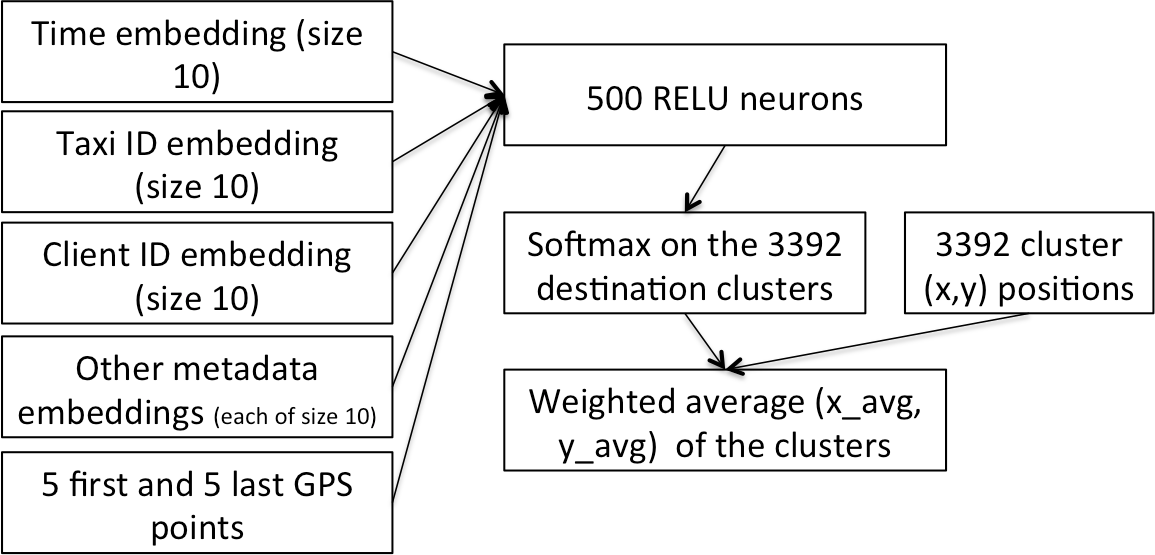
将神经网络与分类嵌入结合使用的方法也适用于时间序列数据。事实上,Yoshua Bengio的学生正是使用了这种模型,通过GPS点轨迹和时间戳来预测出租车行程时长,从而赢得了Kaggle出租车比赛的第一名(论文在此)。Kaggle Rossmann比赛的第三名获奖者也使用了这种方法,他们利用连锁店的时间序列数据来预测未来销售额。该比赛的第一名和第二名获奖者使用了依赖于专业知识的复杂集成模型,而第三名则是一个没有领域特定特征工程的单一模型。
在我们的课程3 jupyter notebook中,我们逐步讲解了Kaggle Rossmann比赛的一个解决方案。该数据集(像许多数据集一样)包含分类数据(如商店所在的州,或属于3种不同商店类型之一)和连续数据(如到最近竞争对手的距离或当地天气的温度)。fastai库允许你将分类变量和连续变量都作为神经网络的输入。
将机器学习应用于时间序列数据时,你几乎总是希望选择一个验证集,该验证集是包含你拥有数据的最新可用日期的连续片段。正如我在之前的一篇文章中写道:“如果你的数据是时间序列,选择数据的随机子集会太容易(你可以查看你要预测日期之前和之后的数据),并且不代表大多数业务用例(在这些用例中,你使用历史数据来构建用于未来的模型)。”
成功将深度学习应用于时间序列数据的一个关键是将日期拆分为多个分类变量(年、月、周、星期几、月中的日期,以及指示是否是月/季度/年开始/结束的布尔值)。fastai库已经实现了为你处理此问题的方法,如下所述。
fastai库中需要了解的模块
我们将在接下来的几个月内发布更多关于fastai库的文档,但它已经在pip和github上可用,并且已用于面向程序员的实用深度学习课程。fastai库构建在PyTorch之上,并封装了使用神经网络的最佳实践和有用的高级抽象。fastai库取得了最先进的结果,最近被用于赢得斯坦福大学DAWNBench竞赛(最快的CIFAR10训练)。
fastai.column_data
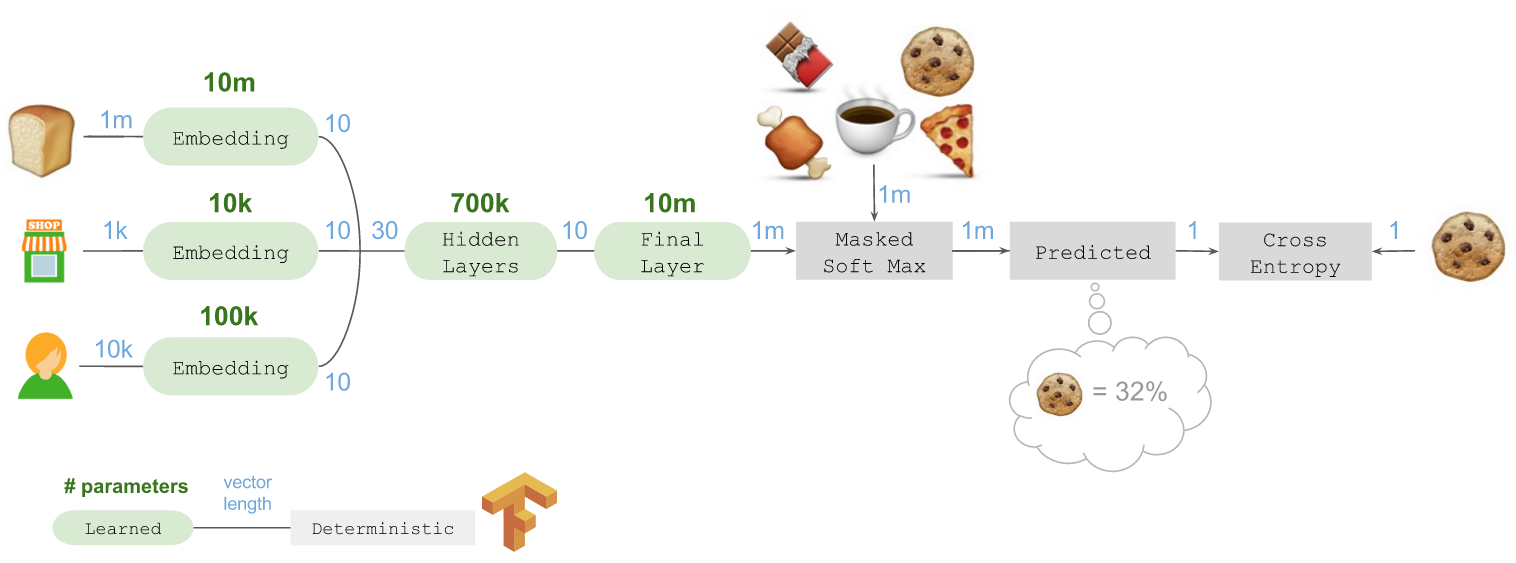
fastai.column_data.ColumnarModelData接受Pandas DataFrame作为输入,并创建一个ModelData对象类型(该对象包含用于训练集、验证集和测试集的数据加载器,是训练模型时跟踪数据的基础方式)。
fastai.structured
fastai库的fastai.structured模块构建在Pandas之上,包含多种转换DataFrame的方法,通过适当预处理数据和创建正确的变量类型来提高机器学习模型的性能。
例如,fastai.structured.add_datepart将日期(例如 2000-03-11)转换为多个变量(年、月、周、星期几、月中的日期,以及指示是否是月/季度/年开始/结束的布尔值)。
该模块中的其他有用方法允许你:
- 用中位数填充缺失值,同时添加一个布尔指示变量(
fix_missing) - 将Pandas DataFrame中的任何字符串列转换为分类值列(
train_cats)