发布于:2018年5月2日
基准测试结果
DAWNBench 是斯坦福大学的一个项目,旨在通过举办一系列竞赛来比较不同的深度学习方法。DAWNBench 竞赛中有两个部分引起了我们的注意:CIFAR 10 竞赛和 Imagenet 竞赛。它们的目标是简单地提供最快以及最便宜的图像分类器,以达到一定的准确率(Imagenet为93%,CIFAR 10为94%)。
在CIFAR 10竞赛中,我们的参赛作品赢得了两个训练部分的冠军:最快和最便宜。另一位独立工作的fast.ai学生Ben Johnson,他参与了DARPA D3M项目,在这两个部分都获得了亚军。
在Imagenet竞赛中,我们的结果是
- 在公开可用基础设施上最快,在GPU上最快,在单台机器上最快(比英特尔使用128台机器集群的参赛作品还要快!)
- 最低的实际成本(尽管DAWNBench的官方结果没有使用我们的实际成本,如下文所述)。
总的来说,我们的发现是
- 算法创造力比裸机性能更重要
- 由Facebook人工智能研究院和合作团队开发的Pytorch,可以实现快速迭代和调试,从而支持这种创造力
- AWS竞价型实例是快速且经济高效地运行大量实验的绝佳平台。
在这篇文章中,我们将讨论我们在每个竞赛中的方法。这里讨论的所有方法要么已经集成到fastai库中,要么正在合并到库中。
超级收敛
fast.ai 是一个致力于通过教育和开发简化当前最佳实践访问的软件来使深度学习更易获得的研究所。我们不相信拥有最新的计算机或最大的集群是成功的关键,而是利用现代技术和最新研究,并对我们试图解决的问题有清晰的理解。作为这项研究的一部分,我们最近开发了一个新的用于训练深度学习模型的库,基于Pytorch,名为fastai。
随着时间的推移,我们一直在将一些我们认为被深度学习社区很大程度上忽视的研究论文中的算法整合到fastai中。特别是,我们注意到社区有一种倾向,过分强调来自斯坦福、DeepMind和OpenAI等知名机构的结果,而忽视了来自不太知名的机构的结果。一个特别的例子是来自海军研究实验室的Leslie Smith,以及他最近发现的一种他称之为超级收敛的非凡现象。他表明,与以前已知的方法相比,训练深度神经网络的速度可以提高5-10倍,这有可能彻底改变该领域。然而,他的论文没有被学术出版机构接受,也没有在任何主要软件中实现。
在课堂上讨论这篇论文后的24小时内,fast.ai的学生Sylvain Gugger就完成了该方法的实现,并将其整合到fastai中,他还开发了一个交互式笔记本,展示了如何实验其他相关方法。实质上,Smith表明,如果在训练过程中非常缓慢地增加学习率,同时减小动量,我们就可以在极高的学习率下进行训练,从而避免过拟合,并在更少的epochs中完成训练。
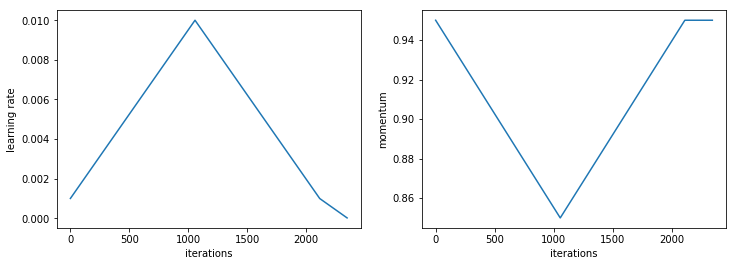
新算法思想的如此快速的周转正是Pytorch和fastai的闪光之处。Pytorch允许交互式调试和使用标准的Python编码方法,而fastai提供了许多构建块和钩子(例如,在这种情况下,允许自定义训练的回调,以及用于构建新学习率退火方法的fastai.sgdr)。Pytorch的张量库和CUDA允许快速实现新算法以进行探索。
我们有一个非正式的深度学习学习小组(任何人都可以免费加入),在课程期间每天一起开会研究项目,我们认为看看这个新贡献的代码是否像Smith声称的那样有效会很有趣。我们听说斯坦福大学正在举办一个名为DAWNBench的竞赛,我们觉得这是一个有趣的测试机会。从我们决定参加到竞赛结束只有10天,时间非常紧!

CIFAR 10
CIFAR 10和Imagenet都是图像识别任务。例如,想象一下我们有一组猫和狗的照片,我们想构建一个工具来自动区分它们。我们构建一个模型,然后在许多图片上进行训练,以便之后可以对我们以前没见过的猫和狗图片进行分类。接下来,我们可以将模型应用于更大的数据集,如CIFAR,这是一个包含十种不同对象的图片集合,例如猫和狗,以及其他动物/车辆,例如青蛙和飞机。这些图片很小(32像素x 32像素),因此这个数据集也很小(160MB),易于处理。如今,它是一个相当被低估的数据集,仅仅因为它比当今流行的数据集更老、更小。然而,它非常具有代表性,反映了大多数组织在现实世界中所拥有的数据量,并且小的图像尺寸使其既具有挑战性又易于获取。
当我们决定参加竞赛时,当时的领先者在一个多小时内就取得了94%的准确率。我们很快发现,我们能够在15分钟左右使用超级收敛训练一个Resnet 50模型,这是一个令人兴奋的时刻!然后我们尝试了一些不同的架构,发现Resnet 18(在其预激活变体中)在10分钟内达到了相同的结果。我们在课堂上讨论了这个问题,Ben Johnson独立地进一步开发了这一点,他添加了一种fast.ai开发的方法,称为“concat pooling”(在网络的倒数第二层连接最大池化和平均池化),并在单个NVIDIA GPU上达到了惊人的6分钟。
在学习小组中,我们决定专注于多GPU训练,以期在单台机器上获得最快的结果。总的来说,我们认为在多台机器上训练模型会增加工程和系统管理复杂性,应尽量避免,因此我们专注于在单台机器上效果良好的方法。我们使用了NVIDIA的一个库,名为NCCL,它与Pytorch配合良好,可以在最小开销的情况下利用多个GPU。
大多数关于多GPU训练的论文和讨论都侧重于每秒完成的操作数量,而不是实际报告训练网络需要多长时间。然而,我们发现当在多个GPU上训练时,我们的架构显示出非常不同的结果。研究界显然还有很多工作要做,才能真正理解如何在实践中利用多个GPU获得更好的端到端训练结果。例如,我们发现,在单个GPU上效果良好的训练设置在多个GPU上往往会导致梯度爆炸。我们结合了之前学术论文中的所有建议(将在未来的一篇论文中讨论),并获得了一些合理的结果,但我们仍然未能真正发挥机器的全部力量。
最后,我们发现要真正利用机器中的8个GPU,我们实际上需要在每个批次中为其提供更多的工作——也就是说,我们增加了每一层中的激活数量。我们利用了另一篇来自不太知名机构的被低估的论文:来自Université Paris-Est, École des Ponts的Wide Residual Networks。这篇论文对构建残差网络的许多不同方法进行了广泛的分析,并提供了对这些架构必要构建块的丰富理解。
我们的另一位学习小组成员Brett Koonce开始用大量不同的参数设置进行实验,试图找到一个真正效果好的方案。我们最终创建了一个“略宽”版本的resnet-34架构,使用Brett精心选择的超参数,能够在多GPU训练下在不到3分钟的时间内达到94%的准确率!
AWS和竞价型实例
我们很幸运能够获得一些AWS信用额度用于这个项目(感谢亚马逊!)。我们希望能够并行运行许多实验,而无需花费超出必要的信用额度,因此学习小组成员Andrew Shaw构建了一个Python库,该库允许我们自动启动竞价型实例,进行设置,训练模型,保存结果,然后自动关闭实例。Andrew甚至设置了所有训练都在tmux会话中自动进行,以便我们可以随时登录任何实例并查看训练进度。
基于我们在本次竞赛中的经验,我们建议对于大多数数据科学家来说,AWS竞价型实例是训练大量模型或训练非常大模型的最佳方法。它们的成本通常约为按需实例的三分之一。不幸的是,DAWNBench的官方结果没有报告实际的训练成本,而是基于按需定价的假设来报告成本。我们不认为这是最实用的方法,因为实际上竞价型实例的定价相当稳定,并且是训练此类模型的推荐方法。
Google的TPU实例(目前处于测试阶段)可能也是一个不错的选择,正如本次竞赛的结果所示,但请注意,使用TPU的唯一方法是接受锁定到以下所有服务:
- Google的硬件(TPU)
- Google的软件(Tensorflow)
- Google的云平台(GCP)。
更成问题的是,无法直接为TPU编写代码,这严重限制了算法创造力(正如我们所见,这是性能最重要的部分)。考虑到TPU对神经网络和算法的支持有限(例如,不支持循环神经网络,这对许多应用至关重要,包括Google自己的语言翻译系统),这既限制了你可以解决的问题,也限制了你如何解决它们。
另一方面,AWS允许你运行任何软件、架构和算法,然后你可以将代码的结果在自己的计算机上运行,或使用不同的云平台。使用竞价型实例的能力也意味着我们可以比Google平台节省相当多的钱(Google有一个类似的测试版产品,称为“可抢占实例”,但它们似乎不支持TPU,并且会在24小时后自动终止你的任务)。
对于单GPU训练,另一个不错的选择是Paperspace,这是我们新课程使用的平台。它们比AWS实例设置起来简单得多,并且预装了整个fastai基础设施。另一方面,它们没有AWS的功能和灵活性。它们比AWS竞价型实例贵,但比AWS按需实例便宜。我们使用Paperspace实例赢得了本次竞赛的成本类别冠军,成本仅为0.26美元。
半精度计算
快速训练的另一个关键是使用半精度浮点数。NVIDIA最新的Volta架构包含张量核心,这些核心只能处理半精度浮点数据。然而,用这种数据成功进行训练一直都很复杂,很少有人展示过使用这种数据训练模型的成功实现。
NVIDIA慷慨地提供了一个使用半精度浮点数训练Imagenet的开源示例,Andrew Shaw致力于将这些想法直接集成到fastai中。我们现在已经把它做到了这样一个程度:你只需在代码中写上learn.half(),从那时起,所有使用半精度浮点数进行快速、正确训练的必要步骤都会自动为你完成。
Imagenet
Imagenet是与CIFAR 10相同问题的不同版本,但图片更大(224像素,160GB),类别更多(1000个)。Smith在他的论文中展示了在Imagenet上的超级收敛,但他没有达到其他研究人员在该数据集上达到的准确率水平。我们也遇到了同样的问题,发现当使用非常高的学习率进行训练时,我们无法达到所需的93%准确率。
取而代之的是,我们转向了我们在fast.ai开发的一种方法,并在我们的深度学习课程的第1课和第2课中教授:渐进式图像缩放(progressive resizing)。这种技术的变体之前已经在学术文献中出现过(Progressive Growing of GANs和Enhanced Deep Residual Networks),但据我们所知,从未应用于图像分类。这项技术非常简单:在训练开始时使用较小的图像进行训练,随着训练的深入逐渐增加图像尺寸。从直观上讲,不需要大图像就能学习猫和狗的一般外观(例如),但稍后当你试图学习每种狗之间的区别时,你通常需要更大的图像。
许多人错误地认为,在一个尺寸的图像上训练的网络不能用于其他尺寸。这在2013年VGG架构绑定到特定图像尺寸时是正确的,但从那时起,总的来说就不再如此了。一个问题是,许多实现错误地在网络的末尾使用了固定尺寸的池化层,而不是全局/自适应池化层。例如,官方的pytorch torchvision模型中没有一个使用了正确的自适应池化层。这类问题正是fastai和keras等库重要的原因——这些库是由致力于确保所有功能开箱即用并集成所有相关最佳实践的人员构建的。像pytorch和tensorflow这样的库的工程师(非常正确地)专注于基础底层,而不是最终用户体验。
通过使用渐进式图像缩放,我们既能使初始epochs比平时快得多(使用128x128图像而不是通常的224x224),又能使最终epochs更准确(使用288x288图像获得更高的准确率)。但性能只是成功原因的一半;另一个影响是更好的泛化性能。通过向网络展示更广泛的图像尺寸,有助于避免过拟合。
关于创新和创造力
我从事机器学习工作已经25年了,在这段时间里,我注意到工程师们就像扑火的飞蛾一样,被吸引去使用他们能获得的最大的数据集,在他们能接触到的最大的机器上。媒体确实喜欢报道任何“最大”的事情。然而,事实是,在这段时间里,真正的进步始终来自于做事情的方式不同,而不是做事情更大。例如,dropout使我们能够在较小的数据集上训练而不过拟合,batch normalization让我们训练得更快,rectified linear units避免了训练期间的梯度爆炸;这些都是有思想的研究人员思考如何以不同方式做事,并让我们其他人能够训练出更好、更快的网络的例子。
当我和我在Google、OpenAI以及其他资金充足机构的朋友交谈时,我担心他们轻易获得大量资源会扼杀他们的创造力。当你可以投入更多资源时,为什么要巧妙地做事呢?但世界是一个资源受限的地方,忽略这个事实意味着你将无法构建真正更广泛地帮助社会的事物。指出贯穿历史,限制一直是创新和创造力的驱动力,这并不是一个新观点。但这似乎是今天很少有研究人员能领会的一课。
更糟糕的是我遇到的那些没有机会接触如此巨大资源的人,他们告诉我他们没费心尝试做前沿研究,因为他们认为没有满屋子的GPU,他们永远也做不出任何有价值的事情。对我来说,他们完全想错了问题:一个用慢电脑的优秀实验者总应该能够超过一个用快电脑的糟糕实验者。
我们很幸运,有像Pytorch团队这样的人正在构建富有创造力的实践者快速迭代和实验所需的工具。我希望看到一个小型的非营利性自筹资金研究实验室和一些兼职学生能够取得这样的顶尖成果,有助于终结这个有害的神话。
请阅读现在任何人都能在18分钟内训练Imagenet以了解更多突破。