这是系列文章的第二部分。请在此查看第一部分,并在此处查看第三部分。
CMU 和 DeepMind 的研究人员最近发布了一篇有趣的新论文,名为可微分架构搜索 (DARTS),为当前机器学习领域一个非常热门的方向——神经架构搜索——提供了一种替代方法。神经架构搜索在过去一年里被大肆宣传,Google 的 CEO Sundar Pichai 和 Google 的 AI 主管 Jeff Dean 推崇这样一种观点:神经架构搜索及其所需的大量计算能力对于向大众普及机器学习至关重要。Google 在神经架构搜索方面的工作得到了科技媒体广泛而赞赏的报道(例如,见此处、此处、此处和此处)。

在2018年3月的 TensorFlow DevSummit 大会上的主题演讲(约从22:20开始)中,Jeff Dean 提出,未来或许Google 可以用100倍的计算能力取代机器学习专业知识。他将计算成本高昂的神经架构搜索作为一个主要例子(也是他给出的唯一例子),来说明为什么我们需要100倍的计算能力才能让更多人接触到机器学习。
什么是神经架构搜索?它是让非机器学习专家也能使用机器学习的关键吗?在这篇文章中,我将深入探讨这些问题;在我的下一篇文章中,我将专门研究 Google 的 AutoML。神经架构搜索是更广泛的AutoML领域的一部分,该领域也受到了很多炒作,我们将首先考虑它。
第二部分目录
什么是 AutoML?
AutoML 一词传统上用于描述模型选择和/或超参数优化的自动化方法。这些方法适用于许多类型的算法,例如随机森林、梯度提升机、神经网络等。AutoML 领域包括开源 AutoML 库、研讨会、研究和竞赛。初学者在测试模型的不同超参数时,常常感觉像是在猜测,而自动化这个过程可以使机器学习管道中的这一部分更容易,同时也能为经验丰富的机器学习从业者加快速度。
有许多 AutoML 库,其中最古老的是AutoWEKA,它于2013年首次发布,可以自动选择模型和超参数。其他著名的 AutoML 库包括auto-sklearn(将 AutoWEKA 扩展到 python)、H2O AutoML 和TPOT。AutoML.org(以前称为 ML4AAD,自动化算法设计的机器学习)自2014年以来每年都在学术机器学习会议ICML上组织AutoML 研讨会。
AutoML 有多大用处?
AutoML 提供了一种选择模型和优化超参数的方法。它对于获得基线以了解问题可能达到的性能水平也很有用。那么,这是否意味着数据科学家可以被取代呢?目前还不行,因为我们需要了解机器学习从业者还在做什么。
对于许多机器学习项目而言,选择模型只是构建机器学习产品复杂过程中的一小部分。正如我在上一篇文章中提到的,如果参与者看不到管道各个部分之间的相互关联,项目可能会失败。我想到了该过程中可能涉及的30多个不同步骤。我强调了机器学习(尤其是深度学习)中最耗时的两个方面:数据清洗(并且是的,这是机器学习不可分割的一部分)和模型训练。尽管 AutoML 可以帮助选择模型和选择超参数,但重要的是要认清仍然需要哪些其他数据专业知识以及仍然存在的难题。
在最后一部分,我将提出一些与 AutoML 不同的方法,以提高机器学习从业者的效率。
什么是神经架构搜索?
既然我们已经介绍了 AutoML 的一些内容,接下来看看该领域一个特别活跃的子集:神经架构搜索。Google CEO Sundar Pichai 写道:“设计神经网络非常耗时,并且需要只有一小部分科学家和工程师才具备的专业知识,这限制了它的应用。这就是我们创建 AutoML 方法的原因,它表明神经网络设计神经网络是可能的。”
Pichai 所说的使用“神经网络设计神经网络”被称为神经架构搜索;通常使用强化学习或进化算法来设计新的神经网络架构。这很有用,因为它允许我们发现比人类可能尝试的复杂得多的架构,并且这些架构可以针对特定目标进行优化。神经架构搜索通常计算成本非常高。
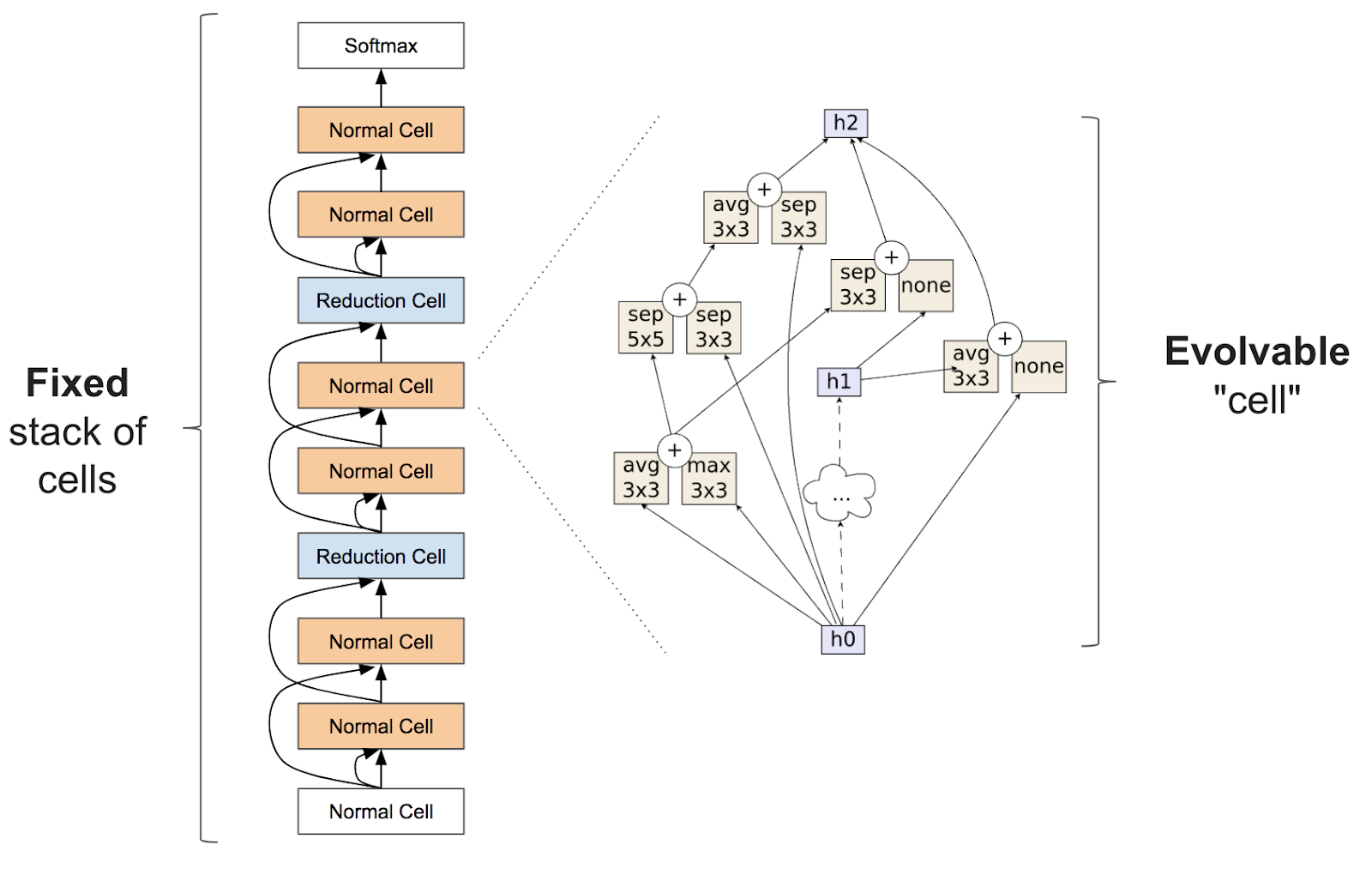
确切地说,神经架构搜索通常涉及学习像层(通常称为“单元格”)这样的东西,这些单元格可以堆叠重复组装起来创建一个神经网络
关于神经架构搜索的学术论文文献浩如烟海,因此我在这里只重点介绍几篇最近的论文
- AutoML 一词因Google AI 研究人员(论文在此)Quoc Le 和 Barret Zoph 的工作而跃升至“主流”地位,该工作于2017年5月在 Google I/O 大会上被重点介绍。这项工作使用强化学习为计算机视觉问题 Cifar10 和自然语言处理问题 Penn Tree Bank 寻找新的架构,并取得了与现有架构相似的结果。
NASNet 源自面向可伸缩图像识别的可迁移架构学习(博客文章在此)。这项工作在小型数据集 (Cifar10) 上搜索架构构建块,然后在大型数据集 (ImageNet) 上构建架构。这项研究计算量非常大,需要1800个 GPU 天(相当于1个 GPU 工作近5年)来学习架构(Google 团队使用了500个 GPU 工作了4天!)。
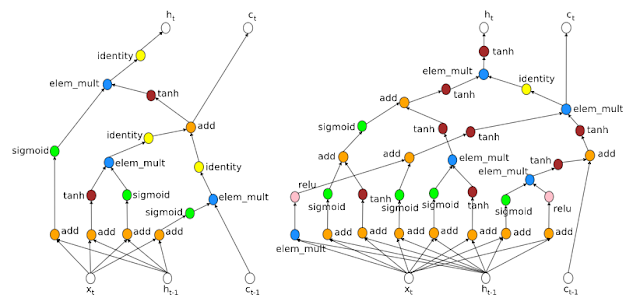
AmoebaNet 源自用于图像分类器架构搜索的正则化进化 这项研究计算量甚至比 NASNet 更大,需要相当于3150个 GPU 天(相当于1个 GPU 工作近9年)来学习架构(Google 团队使用了450个 K40 GPU 工作了7天!)。AmoebaNet 由通过进化算法学习到的“单元格”组成,表明人工进化的架构可以与人类设计和强化学习设计的图像分类器相媲美或超越。在结合了来自 fast.ai 的进展,例如激进的学习计划和随着训练进度改变图像尺寸后,AmoebaNet 现在是在单台机器上训练 ImageNet 最便宜的方式。
高效神经架构搜索 (ENAS):比现有自动模型设计方法使用了少得多的 GPU 小时,特别是比标准神经架构搜索便宜1000倍。这项研究仅使用单个 GPU 花费了16小时。
DARTS 又如何?
可微分架构搜索 (DARTS)。这项研究最近由卡内基梅隆大学和 DeepMind 的一个团队发布,我对这个想法感到兴奋。DARTS 假定候选架构空间是连续的,而不是离散的,这使得它可以使用基于梯度的逼近方法,这比大多数神经架构搜索算法使用的低效黑盒搜索效率高得多。
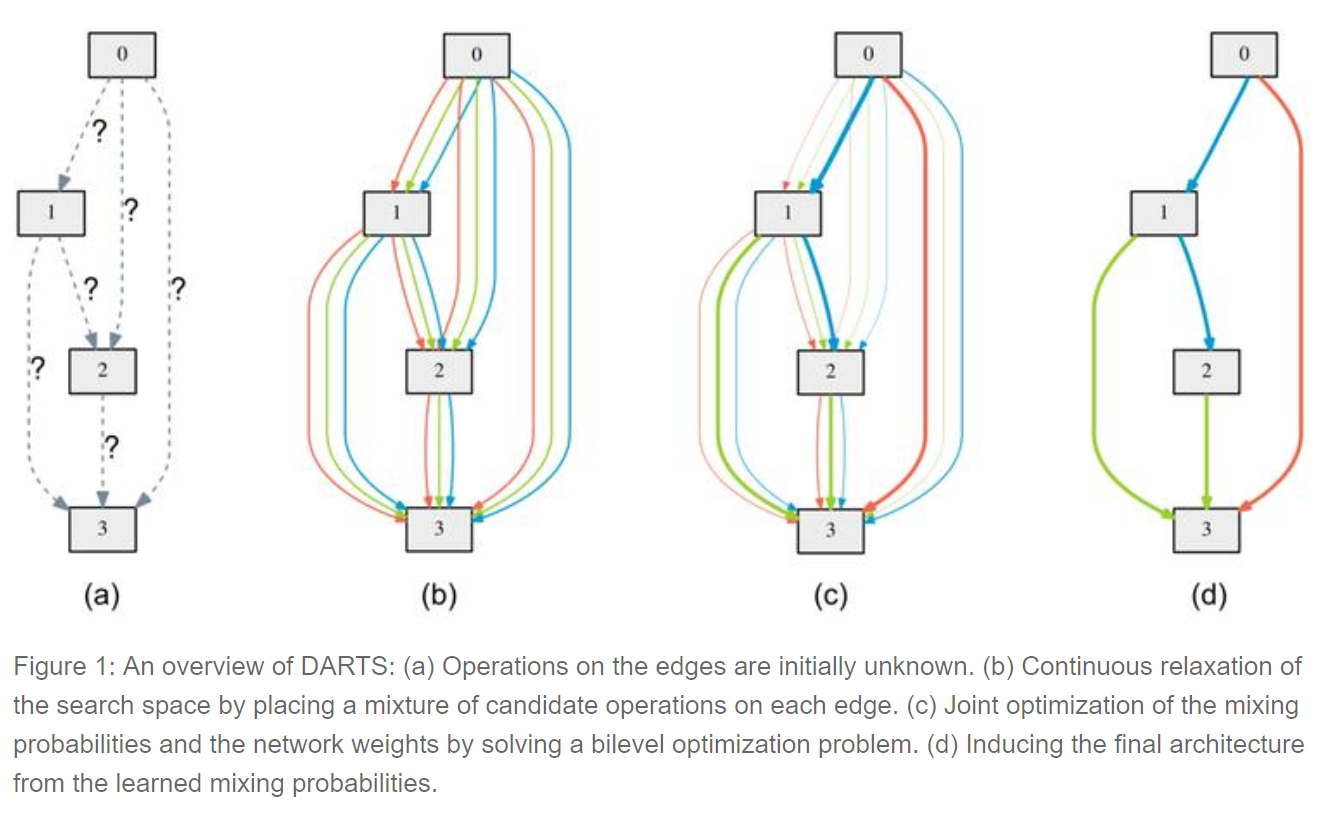
为了学习用于 Cifar-10 的网络,DARTS 仅需4个 GPU 天,而NASNet 需要1800个 GPU 天,AmoebaNet 需要3150个 GPU 天(所有方法都达到了相同的准确度)。这在效率上是一个巨大的提升!尽管还需要进一步探索,但这方向很有前景。考虑到 Google 经常将神经架构搜索等同于巨大的计算开销,高效的架构搜索方法很可能尚未得到充分探索。
神经架构搜索有多大用处?
在他的TensorFlow DevSummit 主题演讲(约从22:20开始)中,Jeff Dean 提出深度学习工作的一个重要部分是尝试不同的架构。这是 Dean 在他的简短演讲中唯一强调的机器学习步骤,我对其强调感到惊讶。Sundar Pichai 的博客文章中也包含了类似的论断。

然而,选择模型只是构建机器学习产品复杂过程中的一小部分。在大多数情况下,架构选择远非问题中最困难、最耗时或最重要的部分。目前,没有证据表明每个新问题最适合用其独特的架构来建模,而且大多数从业者认为这种情况不太可能发生。
像 Google 这样致力于架构设计并与我们其他人分享他们发现的架构的组织,正在提供重要且有益的服务。然而,底层的架构搜索方法仅适用于那一小部分从事基础神经架构设计的研究人员。我们其他人可以通过迁移学习直接使用他们找到的架构。
我们还能如何提高机器学习从业者的效率?AutoML vs. 增强型机器学习
AutoML领域,包括神经架构搜索,主要关注的问题是:我们如何才能自动化模型选择和超参数优化?然而,自动化忽视了人类输入的重要作用。我想提出一个替代问题:人类和计算机如何协同工作以使机器学习更有效?增强型机器学习的重点在于弄清楚人类和机器如何最好地协作以利用它们各自不同的优势。
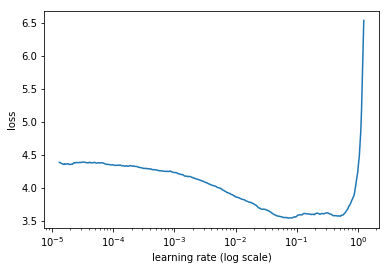
增强型机器学习的一个例子是 Leslie Smith 的学习率查找器(论文在此),它已在fastai 库中实现(这是一个位于 PyTorch 之上的高级 API),并在我们的免费深度学习课程中作为一项关键技术进行教授。学习率是一个超参数,可以决定你的模型训练速度,甚至是否能成功训练。学习率查找器允许人类通过查看生成的图表,在一个步骤中找到一个好的学习率。它比解决同一问题的 AutoML 方法更快,提高了数据科学家对训练过程的理解,并鼓励采用更强大的多步方法来训练模型。
专注于自动化超参数选择还有另一个问题:它忽视了某些类型的模型更广泛有用、需要调整的超参数更少、并且对超参数选择不太敏感的可能性。例如,随机森林相对于梯度提升机(GBMs)的一个主要优点是随机森林更鲁棒,而 GBMs 对超参数的微小变化往往相当敏感。因此,随机森林在工业界被广泛使用。研究如何有效去除超参数(通过更智能的默认设置或通过新模型)可以产生巨大影响。当我在2013年第一次对深度学习产生兴趣时,感到超参数如此之多,令人不知所措;我很高兴新的研究和工具帮助消除了其中许多(特别是对初学者而言)。例如,在 fast.ai 课程中,初学者开始时只需要选择一个超参数——学习率,我们甚至提供了一个工具来帮助你完成!
敬请期待…
现在我们已经大致了解了 AutoML 和神经架构搜索领域是什么,在下一篇文章中,我们将更深入地探讨 Google 的 AutoML。
如果你还没有看过,请查看本系列的第一部分:机器学习从业者都在做什么?以及第三部分:Google 的 AutoML:揭穿炒作。
请务必下周查看本文的第三部分!