本文是之前一篇博文的延伸,用25美元在3小时内训练Imagenet;以及用0.26美元训练CIFAR10。
一个由fast.ai校友Andrew Shaw、DIU研究员Yaroslav Bulatov和我组成的团队,成功地使用16个公共AWS云实例(每个实例配备8块NVIDIA V100 GPU),运行fastai和PyTorch库,在短短18分钟内将Imagenet训练到93%的准确率。这是在公开可用基础设施上将Imagenet训练到此准确率的新速度记录,比Google在其专有的TPU Pod集群上的DAWNBench记录快了40%。我们的方法使用了与Google基准测试相同数量的处理单元(128个),运行成本约为40美元。
DIU和fast.ai将发布软件,允许任何人在AWS上轻松训练和监控他们自己的分布式模型,利用本项目开发出的最佳实践。我们使用的主要训练方法(详情见下文)包括:fast.ai的分类渐进式尺寸调整和矩形图像验证;NVIDIA的NCCL配合PyTorch的all-reduce;腾讯的权重衰减调整;Google Brain动态批量大小的变种、学习率的渐进式预热(Goyal等,2018;Leslie Smith,2018)。我们使用了经典的ResNet-50架构以及带动量的SGD。
背景
四个月前,fast.ai(与我们的MOOC和我们在USF数据研究所的线下课程的一些学生一起)在DAWNBench竞赛中取得了巨大成功,赢得了CIFAR-10(一个包含25,000张32x32像素小图像的数据集)的总体最快训练奖,以及单机(标准AWS公共云实例)上Imagenet(一个包含超过一百万张百万像素图像的大得多数据集)的最快训练奖。我们之前撰文介绍了我们在该项目中采用的方法。Google也表现出色,使用他们不对公众开放的“TPU Pod”集群赢得了Imagenet总速度类别的冠军。我们的单机参赛用时约三小时,Google的集群参赛用时约半小时。在此项目之前,在公共云上训练ImageNet通常需要几天才能完成。
我们参加这场竞赛是因为我们想证明,你不必拥有巨大的资源也能处于AI研究的最前沿,我们在这方面非常成功。我们特别喜欢The Verge的头条新闻:“一次AI速度测试显示,聪明的程序员仍然可以击败像Google和Intel这样的科技巨头。”
然而,很多人问我们——如果你在多台可用的公共机器上训练会发生什么?你能否击败Google令人印象深刻的TPU Pod结果?问这个问题的人之一是DIU(国防部的硅谷创新实验部门)的Yaroslav Bulatov。Andrew Shaw(我们DAWNBench团队的成员之一)和我决定与Yaroslav合作,看看我们能否实现这个极具挑战性的目标。我们很高兴看到AWS最近成功地在短短47分钟内训练了Imagenet,并在他们的结论中说道:“一台配备8块NVIDIA V100 GPU的Amazon EC2 P3实例,使用Super-Convergence及其他高级优化技术,可以在大约三小时内训练ResNet50 with ImageNet data [fast.ai]。我们相信,通过应用类似的技术,我们可以在分布式配置中进一步缩短训练时间。”他们友好地将这篇文章的代码作为开源分享出来,我们在其中找到了一些有用的网络配置技巧,以确保我们能最大程度地利用Linux网络堆栈和AWS基础设施。
实验基础设施
快速迭代需要解决以下挑战:
- 如何在多台机器上轻松运行多个实验,而无需持续运行大量昂贵的实例?
- 如何便捷地利用AWS的Spot Instances(比常规实例便宜约70%),但每次使用时都需要从头设置?
fast.ai为DAWNBench构建了一个系统,其中包括用于启动和配置新实例、运行实验、收集结果和查看进度的Python API。该系统中一些更有趣的设计决策包括:
- 不使用配置文件,而是使用利用Python API的代码来配置实验。因此,我们可以使用循环、条件语句等快速设计和运行结构化实验,例如超参数搜索。
- 编写一个围绕tmux和ssh的Python API包装器,并在tmux会话中启动所有设置和训练任务。这使我们随后可以登录到机器并连接到tmux会话,以监控其进度、修复问题等。
- 保持一切尽可能简单——避免使用Docker等容器技术,或Horovod等分布式计算系统。我们没有使用复杂的集群架构,如独立的参数服务器、存储阵列、集群管理节点等,而只是使用单一类型的实例和常规的EBS存储卷。
DIU独立地面对了一系列类似的挑战,并开发了一个集群框架,其动机和设计选择与此类似,提供了并行运行许多大规模训练实验的能力。该解决方案,nexus-scheduler,灵感来源于Yaroslav在Google的Borg系统上运行机器学习实验的经验。
fast.ai开发的工具集侧重于单实例实验的快速迭代,而DIU开发的nexus-scheduler则侧重于鲁棒性和多机实验。Andrew Shaw将fast.ai软件的一部分合并到nexus-scheduler中,使我们拥有了两者中最优秀的部分,我们用这个来进行了实验。
使用nexus-scheduler帮助我们在分布式实验上进行迭代,例如:
- 为单个实验启动多台机器,以进行分布式训练。分布式运行的机器会自动放入一个*Placement Group*中,从而实现更快的网络性能。
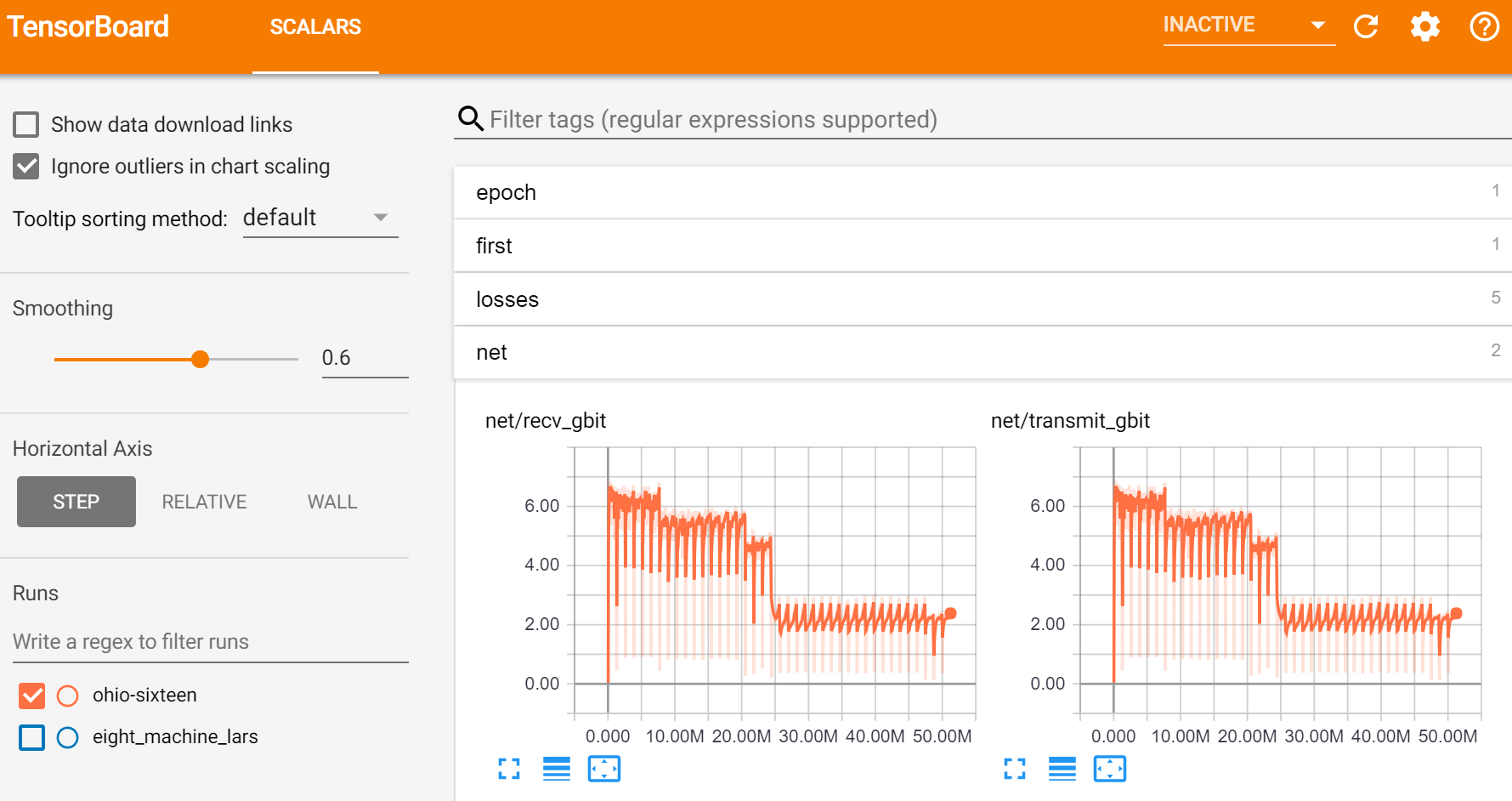
- 通过Tensorboard(一个最初为Tensorflow编写,但现在也可与Pytorch及其他库配合使用的系统)提供监控,事件文件和检查点存储在区域范围的文件系统上。
- 自动化设置。分布式训练所需的各种资源,如VPC、安全组和EFS,都会在后台透明地创建。
AWS提供了一个非常有用的API,使我们能够快速轻松地构建所需的一切。对于分布式计算,我们使用了NVIDIA出色的NCCL库,该库实现了与PyTorch的*all-reduce*分布式模块集成的*ring-style collectives*。我们发现AWS的实例非常可靠,并提供一致的性能,这对于从all-reduce算法中获得最佳结果非常重要。
nexus-scheduler的第一个正式版本,包括从fast.ai工具合并的功能,计划于8月25日发布。
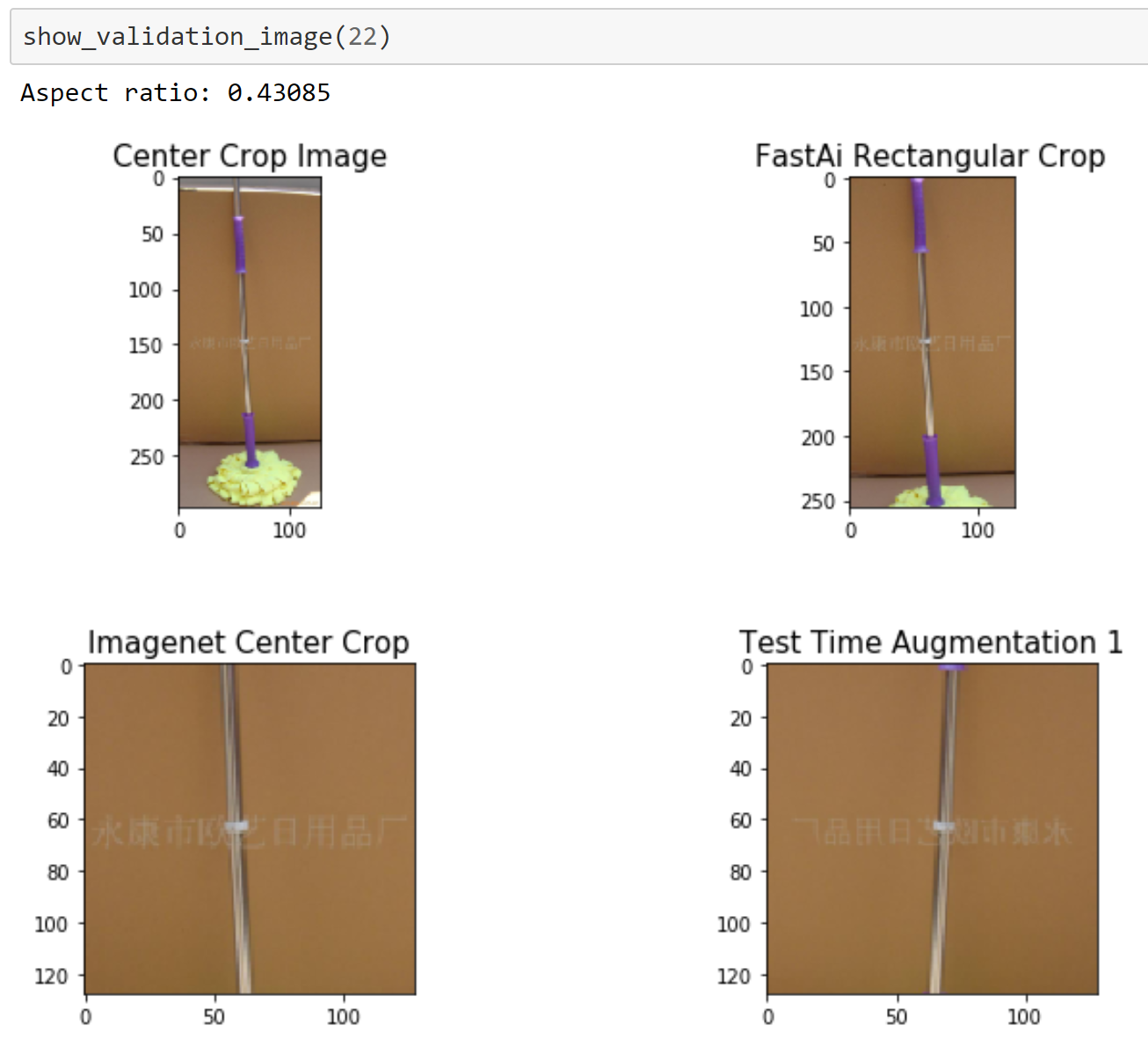
一个简单的新训练技巧:矩形图像!
DAWNBench结束后,我向Andrew提到,我认为深度学习从业者(包括我们自己!)正在做一件非常愚蠢的事情:我们在预测时,会把矩形图像(比如Imagenet中使用的那些)只裁剪出中心部分。另一种(非常慢的)广泛使用的替代方法是选取5个裁剪区域(左上、左下、右上、右下加上中心),然后平均预测结果。这就引出了一个显而易见的问题:为什么不直接使用矩形图像呢?
很多人误认为卷积神经网络(CNNs)只能使用一个固定的图像尺寸,而且必须是矩形。然而,大多数库支持“自适应”或“全局”池化层,这完全避免了这一限制。一些库(如Pytorch)分发的模型没有使用这一特性,这并没帮上忙——这意味着除非这些库的用户替换掉这些层,他们就只能使用一个固定的图像尺寸和形状(通常是224x224像素)。fastai库会自动将固定尺寸的模型转换为动态尺寸的模型。
我以前从未见过有人尝试使用矩形图像进行训练,也没有在任何研究论文中看到过提及,而且我找到的标准深度学习库中也没有任何支持这一点。所以Andrew去研究如何用fastai和Pytorch实现预测时使用矩形图像。
结果令人惊叹——我们立即看到达到93%基准准确率所需的时间缩短了23%。你可以在这个notebook中看到不同方法的比较,并在这个notebook中比较它们的准确率。
渐进式图像尺寸调整、动态批量大小及更多
我们在DAWNBench中的主要进展之一是引入了用于分类的渐进式图像尺寸调整——在训练开始时使用较小的图像,随着训练的进行逐渐增加尺寸。这样,当模型早期非常不准确时,它可以快速看到大量图像并取得快速进展;在训练后期,它可以看到更大的图像以学习更精细的区别。
在这项新工作中,我们还在一些中间epoch使用了更大的批量大小——这使我们能够更好地利用GPU RAM并避免网络延迟。
最近,腾讯发表了一篇非常好的论文,展示了在2048块GPU上将Imagenet训练到小于7分钟。他们提到一个我们之前没有尝试过但非常有道理的技巧:从BatchNorm层移除权重衰减。这使我们又从训练时间中节省了几个epoch。(腾讯的论文还使用了一种由NVIDIA研究开发的动态学习率方法,称为LARS,我们也一直在为fastai开发,但这些结果中尚未包含。)
结果
当我们把所有这些方法结合起来时,在16个AWS实例上获得了18分钟的训练时间,总计算成本(包括机器设置时间)约为40美元。能够训练超过100万张图像的数据集带来的好处是巨大的,例如:
- 拥有大型图像库的组织,如放射中心、汽车保险公司、房地产列表服务和电子商务网站,现在可以创建自己的定制模型。虽然使用如此多图像进行迁移学习通常是过度的,但对于高度专业化的图像类型或细粒度分类(在医学成像中很常见),使用更多的数据量可能会获得更好的结果。
- 小型研究实验室可以试验不同的架构、损失函数、优化器等,并在Imagenet上进行测试,这是许多审稿人希望在发表论文中看到的。
- 通过允许使用标准的公共云基础设施,无需前期资本支出即可开始尖端深度学习研究。
下一步
不幸的是,使用大型计算资源的大公司往往会获得远超出其应有份额的宣传。这可能导致AI评论员得出结论,认为只有大公司才能在最重要的AI研究领域竞争。例如,在腾讯最近的论文之后,OpenAI的Jack Clark声称:“*尽管行业谈论民主化,但事实是优势积累在拥有大型计算机的人身上*。”OpenAI(和Jack Clark)正在努力民主化AI,例如通过优秀的OpenAI Scholars项目和Jack信息量丰富的Import AI通讯;然而,这种认为AI的成功取决于拥有更大的计算机的误解可能会扭曲研究议程。
在过去25年里,我不断看到“大成果需要大计算”说法的变种。这从未是真的,也没有理由会改变。我们今天使用的有趣思想中,很少有是由于拥有最大计算机的人创造的。像BatchNorm、ReLU、Dropout、Adam/AdamW和LSTM这样的思想都是在不需要大型计算基础设施的情况下创建的。今天,任何人都可以按需访问大规模计算基础设施,并按需付费。让深度学习更容易获得比专注于赋能最大的组织具有更高的影响力——因为那样我们可以利用全球数百万人的集体智慧,而不是局限于聚集在几个地理中心的少数同质群体。
我们正在将本项目中使用的所有最佳实践直接整合到fastai库中,包括自动化选择超参数以实现快速准确的训练。
我们还没结束呢——我们还有一些进一步的简单优化想法,我们会尝试。我们不知道能否达到腾讯不到7分钟的水平,因为他们使用了比AWS提供的更快的网络,但肯定还有很大的提速空间。
特别感谢AWS和PyTorch团队,他们在这个项目过程中耐心回答了我们的问题,并提供了他们令人赞叹的实用产品供所有人使用!
您可能还对我们的另一篇博文感兴趣:用25美元在3小时内训练Imagenet;以及用0.26美元训练CIFAR10。