今天,我们将发布我们最新(也是规模最大!)的课程:面向程序员的机器学习导论。这门课程在旧金山大学录制,是其数据科学理学硕士课程的一部分,涵盖了现代机器学习最重要的实践基础。课程共有12节课,每节课时长约两小时——所有课程列表以及每节课的截图都附在本文章末尾。它们都由我(Jeremy Howard)教授;我学习和使用机器学习已有超过25年,从我在麦肯锡公司开始职业生涯担任分析专家,到后来担任Kaggle总裁兼首席科学家以及Enlitic创始CEO。
目前已经有一些优秀的机器学习课程,最著名的莫过于吴恩达(Andrew Ng)精彩的Coursera课程。但这门课程现在看来有些过时,尤其是它在课程作业中使用了Matlab。这门新课程使用了现代工具和库,包括Python、pandas、scikit-learn和pytorch。与该领域的许多教学材料不同,我们的方法是“代码优先”,而不是“数学优先”。它非常适合每天编写代码,但可能不经常练习数学技能的人(尽管我们在适当的时候会涵盖所有必要的理论)。也许最重要的是,这门课程非常具有主见性——我们不会全面介绍每种类型的模型,而是专注于那些在实践中真正重要的模型。
课程涵盖两种主要类型的模型:基于决策树的模型(特别是袋装决策树组成的“森林”)和基于梯度下降的模型(特别是逻辑回归及其变体)。决策树模型构建的结构看起来像这样(实际中你通常会使用更大的树)

(上面的示例来自Terence Parr教授和Prince Grover关于决策树可视化技术的精彩讨论,并使用了他新的animl可视化库。Terence和我目前正在基于本课程材料撰写一本书,前几章的预览已可获取。所以如果你更喜欢通过书籍学习而非视频,请务必关注!)
决策树方法非常灵活且易于使用,通过集成(使用bagging或boosting)在许多实际任务中达到了最先进水平。然而,它们难以对外推(超出训练数据范围)的数据进行预测,并且对于图像、音频和自然语言等数据类型准确性不高。这些问题通常最适合使用梯度下降方法解决,在课程的后半部分我们将介绍其中一些最重要的方法,并以一个简单的深度学习神经网络作为结束。(如果你已经参加过我们的面向程序员的实用深度学习课程,这里会有少量的概念重叠,但教学方式非常不同。)
你将学习如何从零开始创建一个完整的决策树森林实现,并从零开始编写和训练你的深度学习模型。在此过程中,你将学到许多重要技能,包括数据准备、模型测试和产品开发(包括数据产品特有的伦理问题)。
以下是每节课的快速概览,以及示例截图(你可以在课程网站上找到相同的详细信息)
第一课 - 随机森林导论
第一课将向你展示如何创建“随机森林™”——这可能是应用最广泛的机器学习模型——来解决Kaggle竞赛中的“推土机公牛书”(Bull Book for Bulldozers)问题,这将让你进入排行榜前25%。你将学习如何使用Jupyter Notebook构建和分析模型,如何下载数据,以及开始实践机器学习所需的其他基本技能。
第二课 - 随机森林深度探索
今天,我们首先学习评估指标、损失函数,以及(也许是最重要的机器学习概念)过拟合。我们将讨论如何使用验证集和测试集来帮助衡量过拟合。
然后,我们将学习随机森林是如何工作的——首先,通过查看构成它的单个决策树,然后学习“bagging”,这个简单的技巧使得随机森林比任何单个决策树都要准确得多。接下来,我们来看看随机森林支持的一些有用的技巧,以使其更快、更准确。
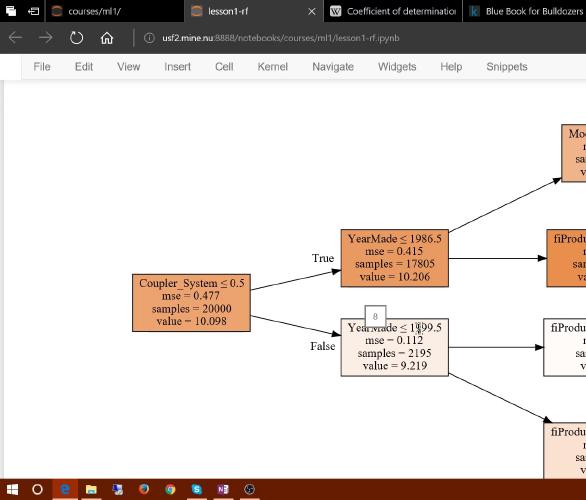
第三课 - 性能、验证与模型解释
今天,我们将看到如何读取一个大得多的数据集——大到可能无法完全载入你机器的内存(RAM)中!我们还将学习如何为该数据集创建随机森林。我们还会讨论软件工程中的“性能分析(profiling)”概念,学习如何在代码不够快时加速它——这对于处理大型数据集尤其有用。
接下来,我们将更深入地探讨验证集,讨论什么是好的验证集,并利用这次讨论为新数据选择一个验证集。
在课程的后半部分,我们将探讨“模型解释”——这项使用模型更好地理解数据的至关重要技能。今天解释的重点是“特征重要性图”,这也许是最有用的模型解释技术。
第四课 - 特征重要性,树解释器
今天,我们将深入探讨特征重要性,包括如何让你的重要性图更具信息量,如何利用它们来修剪特征空间,以及使用“树状图(dendrogram)”来理解特征之间的关系。
在课程的后半部分,我们将学习另外两种非常重要的解释技术:偏依赖图(partial dependence plots)和“树解释器(tree interpreter)”。
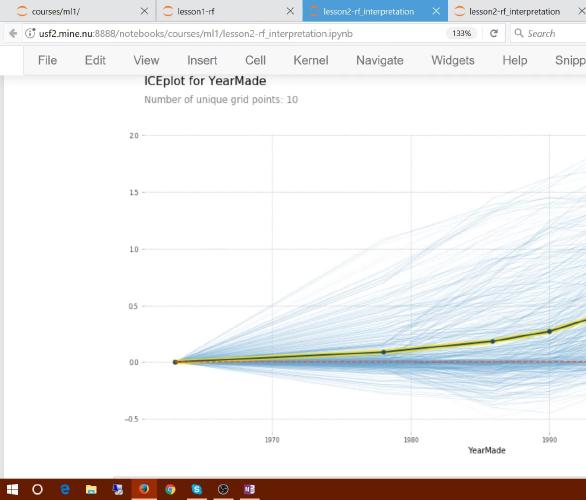
第五课 - 外推与从零开始实现随机森林
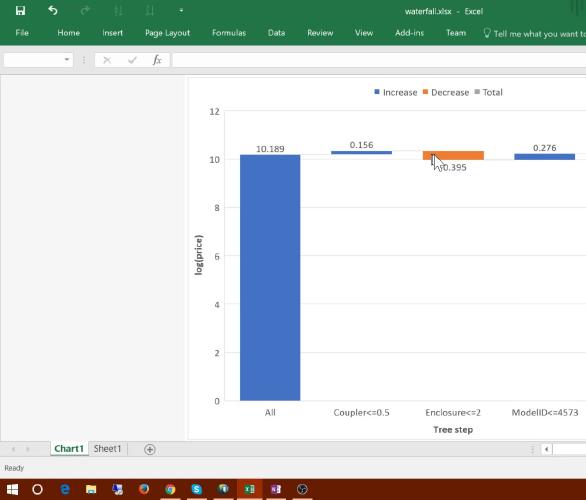
在今天的课程中,我们首先深入学习“树解释器”,包括如何使用“瀑布图(waterfall charts)”来分析其输出。接下来,我们将探讨一个微妙但重要的问题:外推(extrapolation)。这是随机森林的弱点——它们无法预测超出输入数据范围之外的值。我们将研究如何识别何时发生这个问题,以及如何处理它。
在本课程的后半部分,我们将开始从零开始编写我们自己的随机森林!
第六课 - 数据产品
在今天课程的前半部分,我们将学习如何基于“传动系统方法(The Drivetrain Method)”,使用机器学习模型创建“数据产品”,特别是模型解释在这种方法中如何发挥重要作用。
接下来,我们将使用实时编码(Live Coding)的方法更深入地探讨外推问题——我们也将借此机会学习几个实用的numpy技巧。
第七课 - 从零开始实现随机森林
今天我们将完成“从零开始实现”随机森林的解释!我们还将简要介绍神奇的“cython”库,通过对你的Python代码进行少量修改,它就能达到与C代码相同的速度。
然后我们将开始我们旅程的下一阶段——基于梯度下降的方法,如逻辑回归和神经网络……
第八课 - 梯度下降与逻辑回归
今天我们开始课程的后半部分——我们将从基于决策树的方法(如随机森林)转向基于梯度下降的方法(如深度学习)。
我们旅程的第一步是使用Pytorch帮助我们从零开始实现逻辑回归。我们将为经典的MNIST手写数字数据集构建一个模型。
第九课 - 正则化、学习率与自然语言处理
今天,我们继续从零开始构建逻辑回归模型,并为其添加最重要的特性:正则化。我们将学习L1和L2正则化的区别以及如何实现它们。我们还将更详细地讨论学习率的工作原理以及如何为你的问题选择合适的学习率。
在课程的后半部分,我们开始讨论自然语言处理(NLP)。我们将使用稀疏矩阵来确保良好的性能和合理的内存使用,为流行的IMDb文本数据集构建一个“词袋(bag of words)”表示。我们将基于此构建多种模型,包括朴素贝叶斯和逻辑回归,并通过添加ngram特征来改进这些模型。
第十课 - 更多自然语言处理与列式数据
在今天的课程中,我们将通过结合朴素贝叶斯和逻辑回归的优点,进一步开发我们的NLP模型,创建一个混合的“NB-SVM”模型,这是文本分类的一个非常强大的基准模型。为此,我们将在pytorch中创建一个新的nn.Module类,并了解其背后的工作原理。
在课程的后半部分,我们将通过查看Kaggle竞赛数据集“Rossmann”,开始学习使用深度学习处理表格和关系型数据。今天,我们将在这个有趣的数据集上开始特征工程的探索。我们将研究连续变量和分类变量,以及可以针对每种变量进行哪些特征工程,特别关注如何为分类变量使用嵌入矩阵。
第十一课 - 词嵌入
今天,回顾了朴素贝叶斯背后的数学原理后,我们将深入探讨嵌入(embeddings)——既包括用于表格数据中分类变量的嵌入,也包括用于自然语言处理中词语的嵌入。
第十二课 - 完成Rossmann项目,伦理问题
在今天课程的前半部分,我们将把学到的所有内容整合起来,为Rossmann数据集创建一个完整的模型,包括分类特征和连续特征,并对所有列进行细致的特征工程。
在课程的后半部分,我们将学习在实现机器学习模型时出现的一些伦理问题。我们将了解为什么这些问题对实践者很重要,以及如何思考它们。许多学生告诉我们,他们认为这是课程中最重要的一部分!
