今天我们发布了一门新课程(由我教授),《从基础学习深度学习》,该课程展示了如何从头构建一个最先进的深度学习模型。它将带你从实现矩阵乘法和反向传播的基础,到高性能混合精度训练,再到最新的神经网络架构和学习技术,以及介于两者之间的一切。课程涵盖了许多构成现代深度学习基础的最重要的学术论文,采用“代码优先”的教学方法,其中每种方法都用 Python 从头实现并详细解释(在此过程中,我们还将讨论许多重要的软件工程技术)。整个课程包含约15小时的教学和数十个互动笔记本,完全免费(无广告),作为一项社区服务提供。前五节课使用 Python、PyTorch 和 fastai 库;最后两节课使用 Swift for TensorFlow,并由 Swift、clang 和 LLVM 的原始创建者 Chris Lattner 共同教授。
本课程是 fast.ai 2019年深度学习系列课程的第二部分;第一部分,《面向程序员的实用深度学习》,已于一月份发布,是本课程的必修前置课程。这体现了我们持续致力于为深度学习实践者和教育者提供免费、实用、前沿教育的承诺——这一承诺已受到数十万学生的赞赏,并使得 《经济学人》 评论道:“Jeremy Howard 的目标是揭开这个领域的神秘面纱,让任何想学习如何构建人工智能软件的人都能接触到它……这正在奏效”,并且 fast.ai 被 CogX 授予了 杰出人工智能贡献奖。

从某些方面来说,《从基础学习深度学习》的目的与第一部分恰恰相反。这一次,我们学习的不是可以直接使用的实用技能,而是可以作为基石的基础知识。如今这一点尤为重要,因为这个领域发展得太快了。在这门新课程中,我们将学习实现 fastai 和 PyTorch 库中的许多内部功能。事实上,我们将重新实现 fastai 库的一个重要子集!在此过程中,我们将练习实现论文,这是构建最先进模型时需要掌握的一项重要技能。

最后两节课投入了巨大的工作量——团队不仅需要创建涵盖 TensorFlow 和 Swift 的新教学材料,还需要从头创建新的 fastai Swift 库,并在 Swift for TensorFlow 中添加许多新功能(并修复了一些错误!)。这是 Google Brain 的 Swift for TensorFlow 团队与 fast.ai 之间非常紧密的合作,如果没有两边整个团队的热情、投入和专业知识,这是不可能实现的。这种合作仍在进行中,今天 Google 发布了与新课程配套的 Swift for TensorFlow 新版本 (0.4)。有关 Swift for TensorFlow 发布和课程的更多信息,请查看 TensorFlow 博客上的这篇博文。
在这篇博文的剩余部分,我将快速总结一下本课程预计涵盖的一些主题——如果听起来很有趣,那么现在就开始学习吧!如果在学习过程中有任何疑问(或者只是想与其他学生交流),课程有一个非常活跃的论坛,已经有成千上万的帖子了。
第8课:矩阵乘法;前向和后向传播
我们的主要目标是构建一个完整的系统,能够以世界一流的准确性和速度训练 ImageNet。因此,我们需要涵盖很多领域。
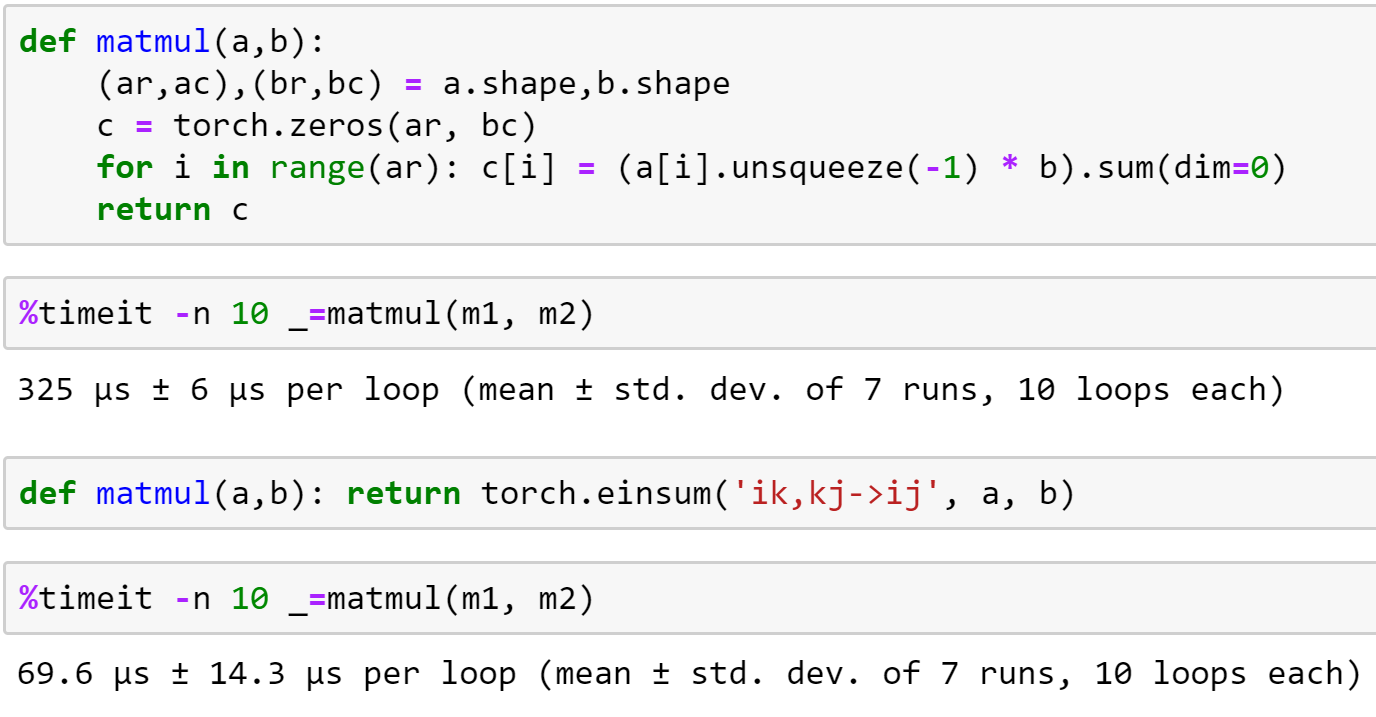
第一步是矩阵乘法!我们将逐步重构和加速我们第一个纯 Python 实现的矩阵乘法,并在此过程中学习广播和爱因斯坦求和约定。然后我们将用它来创建一个基本的神经网络前向传播,包括初步了解神经网络是如何初始化的(这个主题将在接下来的课程中深入探讨)。
然后我们将实现后向传播,包括简要回顾链式法则(后向传播的本质)。接着我们将重构后向路径,使其更灵活和简洁,最后我们将看到这如何转化为 PyTorch 的实际工作方式。

讨论过的论文
- 理解训练深度前馈神经网络的难度 – 引入 Xavier 初始化的论文
- Fixup 初始化:无归一化的残差学习 – 强调归一化重要性的论文 - 训练无正则化的万层网络
第9课:损失函数、优化器和训练循环
在上一课中,我们有一个关于 PyTorch CNN 默认初始化的悬而未决的问题。为了回答这个问题,我做了一些研究,在第9课中,我们将看到我是如何进行这项研究以及我学到了什么。学生们经常问“我该如何做研究”,所以这是一个很好的小型案例研究。
然后我们深入探讨训练循环,并展示如何使其简洁灵活。首先,我们简要回顾损失函数和优化器,包括实现 softmax 和交叉熵损失(以及 logsumexp 技巧)。然后我们创建一个简单的训练循环,并逐步重构它,使其更加简洁和灵活。在此过程中,我们将学习 nn.Parameter 和 nn.Module,并了解它们如何与 nn.optim 类一起工作。我们还将看到 Dataset 和 DataLoader 的实际工作原理。
一旦这些基本组成部分到位,我们将仔细研究 fastai 的一些关键构建块:Callback、DataBunch 和 Learner。我们将了解它们如何提供帮助以及如何实现。然后我们将开始编写大量回调函数,以实现许多新功能和最佳实践!
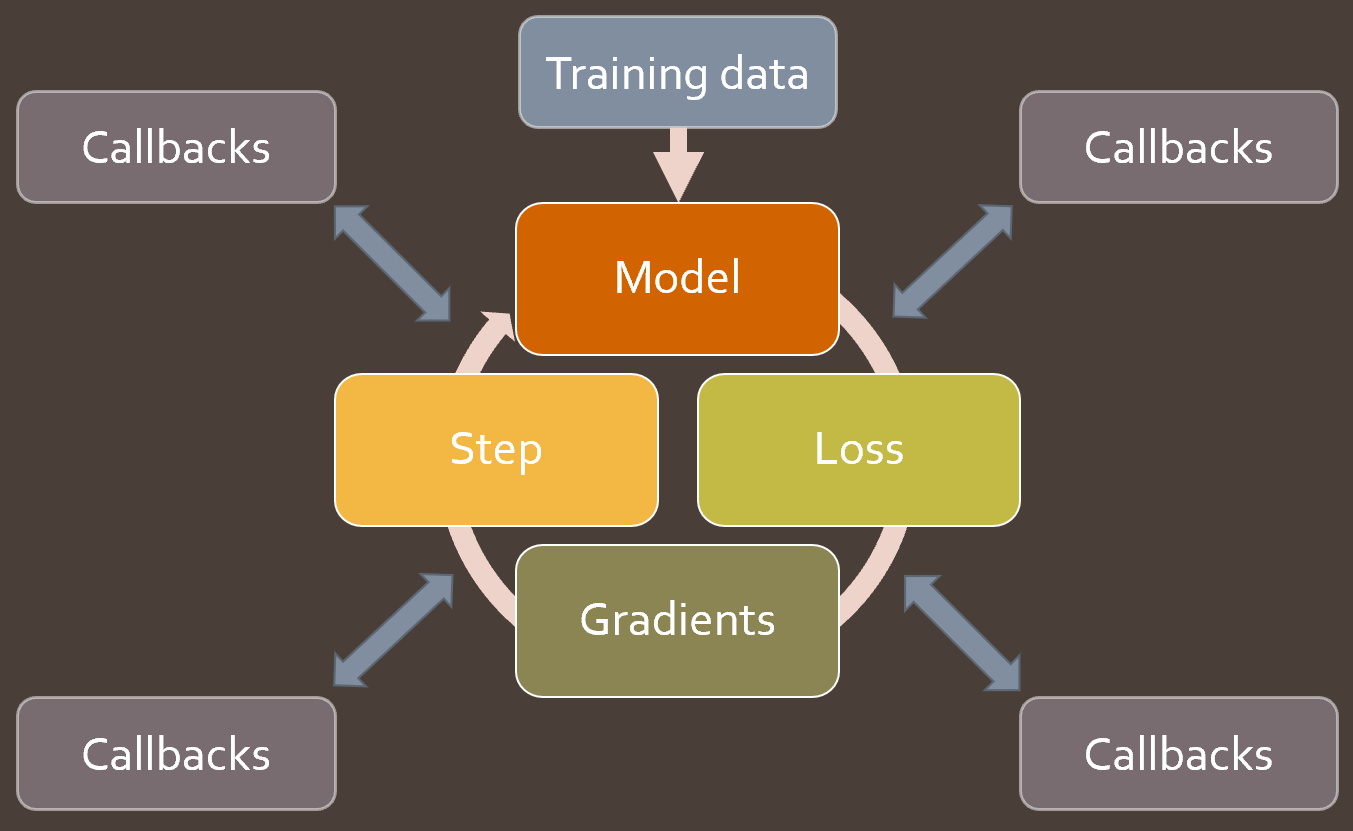
讨论过的论文
- 自归一化神经网络 (SELU)
- 深度线性神经网络中学习非线性动力学的精确解 (正交初始化)
- 你只需要一个好的初始化
- 深入探索整流器:在 ImageNet 分类中超越人类水平性能 – 赢得 ImageNet 的2015年论文,并引入了 ResNet 和 Kaiming 初始化。
第10课:深入模型内部
在第10课中,我们首先更深入地探讨回调和事件处理器的基本思想。我们研究了在 Python 中实现回调的许多不同方法,并讨论了它们的优缺点。然后我们快速回顾其他一些重要的基础知识
- Python 中的
__dunder__特殊符号 - 如何使用编辑器浏览源代码
- 方差、标准差、协方差和相关性
- Softmax
- 将异常作为控制流
接下来,我们使用创建好的回调系统来设置在 GPU 上进行 CNN 训练。在这里,我们开始看到这个系统的灵活性——在本课程中,我们将创建许多回调函数。

然后我们继续讨论本课的主要主题:深入模型内部,了解它在训练过程中的行为。为此,我们首先需要了解 PyTorch 中的 钩子(hooks),它允许我们在前向和后向传播中添加回调。我们将使用钩子来跟踪训练过程中每层激活值的分布变化。通过绘制这些分布图,我们可以尝试找出训练中的问题。
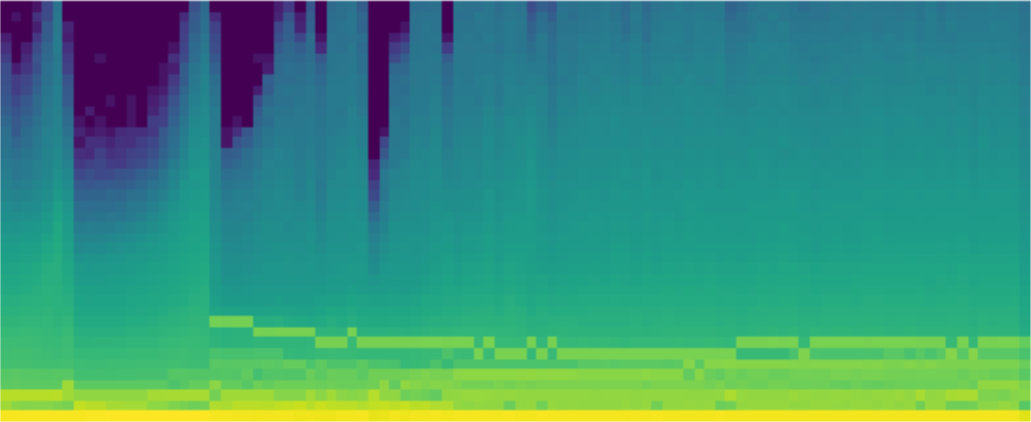
为了解决我们看到的问题,我们尝试改变激活函数,并引入批量归一化 (batchnorm)。我们研究了 batchnorm 的优缺点,并注意到它在某些方面表现不佳。最后,我们开发了一种新型的归一化层来克服这些问题,将其与先前发表的方法进行比较,并看到了一些非常令人鼓舞的结果。
讨论过的论文
第11课:Data Block API 和通用优化器
在第11课中,我们首先简要介绍一种智能而简单的初始化技术,称为逐层序贯单位方差 (LSUV)。我们从头实现它,然后使用上一课介绍的方法来研究这项技术对模型训练的影响。看起来效果相当不错!
然后我们看看 fastai 的一个瑰宝:Data Block API。我们已经在课程的第一部分中看到了如何使用这个 API;但现在我们将学习如何从头创建它,在此过程中,我们还将学到如何更好地使用和自定义它。我们将仔细研究每个步骤
- 获取文件:我们将学习
os.scandir如何提供一种高度优化的文件系统访问方式,以及os.walk如何在此之上提供强大的递归树遍历抽象 - 转换:我们创建一个简单但功能强大的
list和函数组合,以实现数据的即时转换 - 分割和标记:我们为每个步骤创建灵活的函数
- DataBunch:我们将看到
DataBunch是一个非常简单的容器,用于容纳我们的DataLoaders
接下来,我们构建一个新的 StatefulOptimizer 类,并展示现代深度学习训练中使用的几乎所有优化器都只是这个类的特殊情况。我们使用它添加权重衰减、动量、Adam 和 LAMB 优化器,并详细研究动量如何改变训练。

最后,我们研究数据增强,并对各种数据增强技术进行基准测试。我们开发了一种新的基于 GPU 的数据增强方法,发现它显著提高了速度,并且允许我们添加更复杂的基于扭曲的转换。

讨论过的论文
第12课:高级训练技术;从头实现 ULMFiT
在第12课中,我们实现了一些非常重要的训练技术,所有这些都使用了回调
- MixUp,一种数据增强技术,能显著改善结果,尤其是在数据量较少或可以训练更长时间的情况下
- 标签平滑,与 MixUp 结合效果尤其好,并在标签噪声较大时显著提高结果
- 混合精度训练,在许多情况下能将模型训练速度提升约 3 倍。

我们还实现了 xresnet,它是经典 ResNet 架构的一个改进版本,提供了实质性的改进。更重要的是,它的开发过程为我们深入了解什么能使架构表现出色提供了宝贵的见解。
最后,我们将展示如何从头实现 ULMFiT,包括构建一个 LSTM RNN,并研究处理自然语言数据以便将其输入神经网络所需的各种步骤。

讨论过的论文
第13课:用于深度学习的 Swift 基础
到第12课结束时,我们已经从头完成了大部分 Python fastai 库的构建。接下来,我们将为 Swift 重复这个过程!最后两节课由 Jeremy 和 Swift 的原始开发者、Google Brain Swift for TensorFlow 项目负责人 Chris Lattner 共同教授。
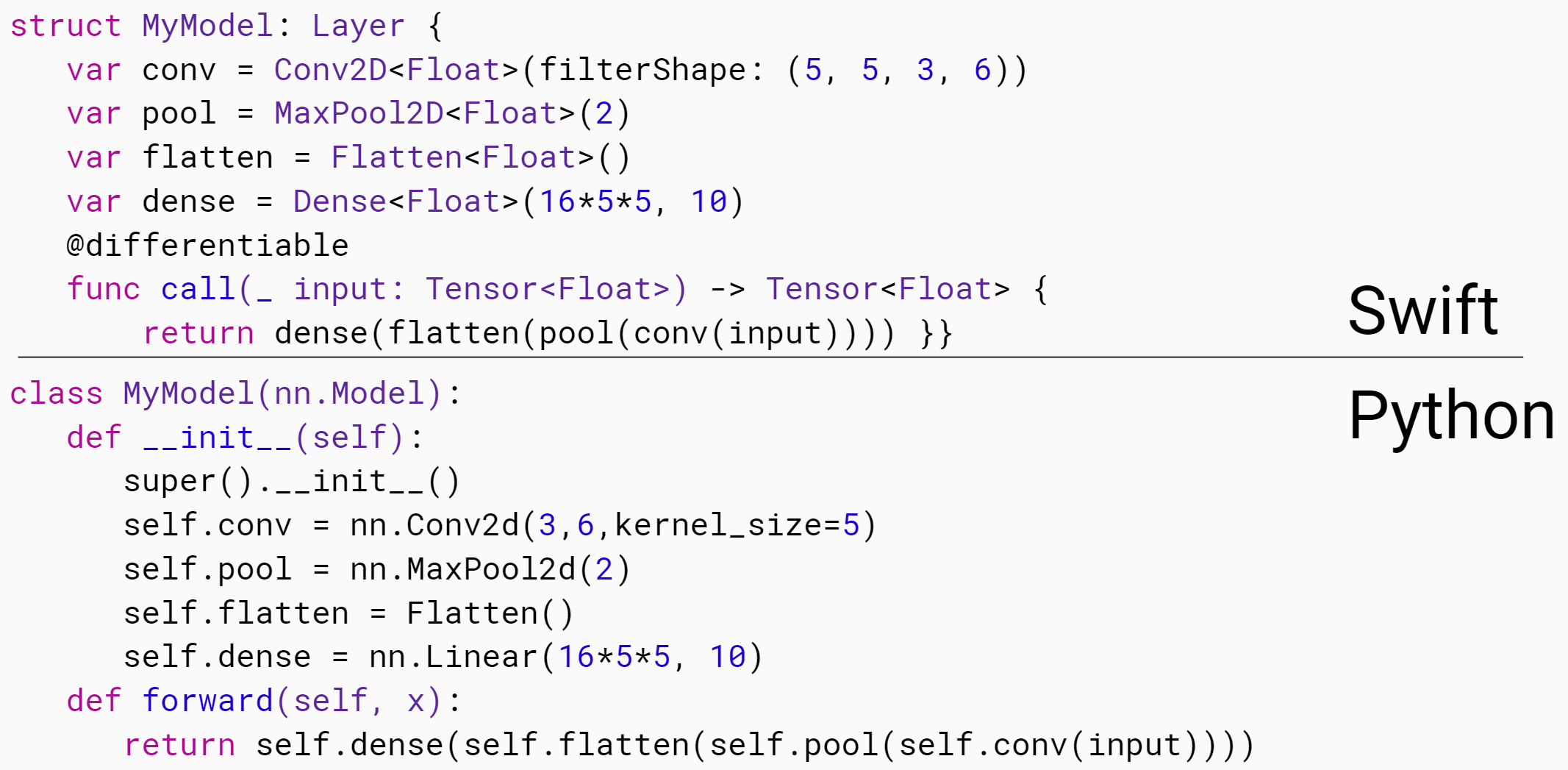
在本课中,Chris 解释了 Swift 是什么,以及它的设计目标。他分享了关于其开发历史的见解,以及为什么他认为它非常适合深度学习和更广泛的数值编程。他还提供了一些关于 Swift 和 TensorFlow 如何协同工作(包括现在和将来)的背景信息。接下来,Chris 演示了如何使用类型来减少代码错误,同时让 Swift 为你推断出大多数类型。他还解释了我们需要入门的一些关键语法元素。
Chris 还解释了什么是编译器,以及 LLVM 如何让编译器开发变得更容易。然后他展示了我们如何直接从 Swift 访问和修改 LLVM 的内置类型!得益于编译和语言设计,基础代码运行速度确实非常快——在 Chris 在课堂上演示的简单示例中,比 Python 快约 8000 倍。
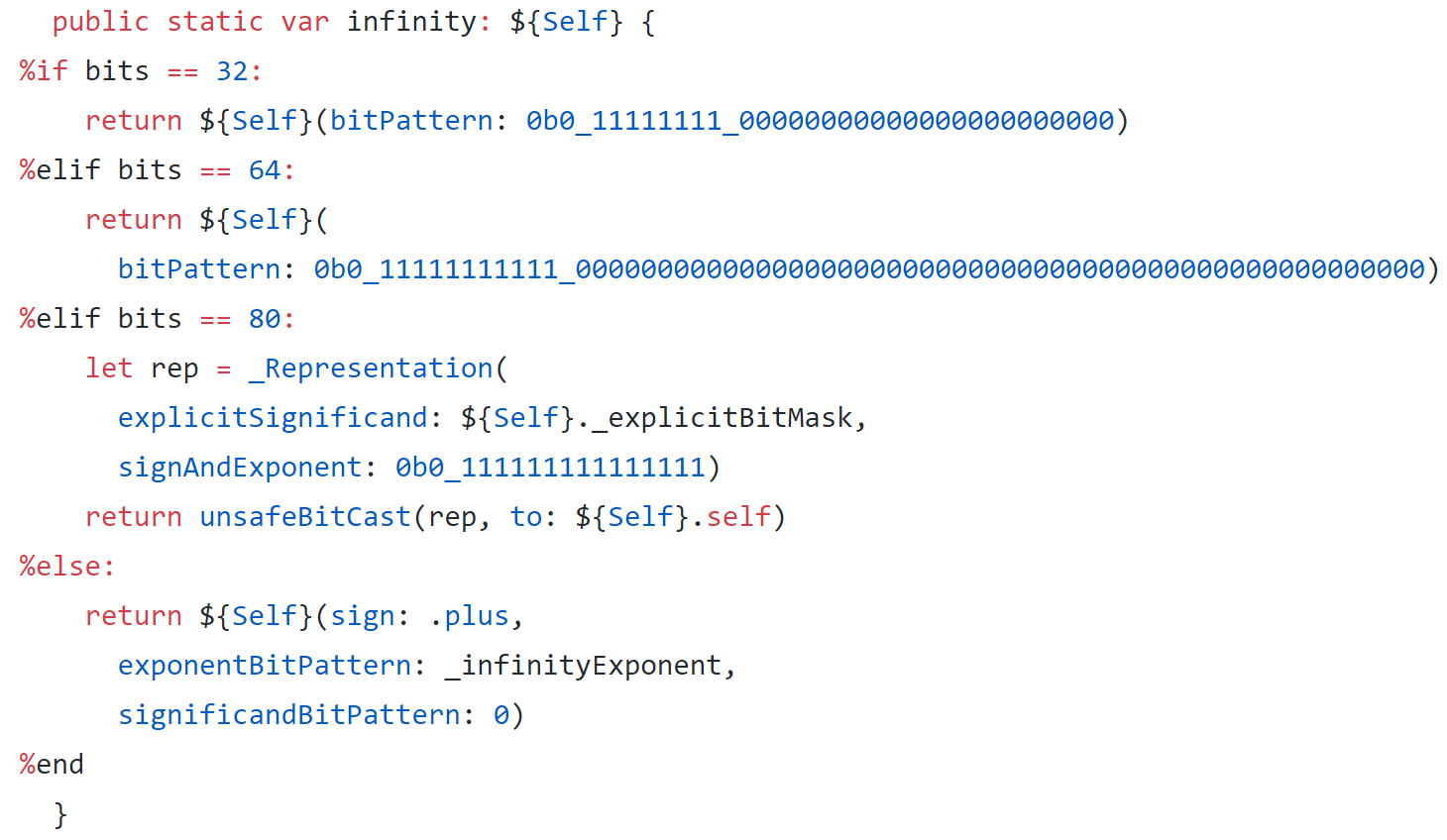
float 的实现最后,我们看看在 Swift 中计算矩阵乘积的不同方法,包括使用 Swift for TensorFlow 的 Tensor 类。
Swift 资源
- 《Swift 编程语言》
- Swift 概览(如果可能,请在 iPad 或 Mac 的 Playground 中下载)。
- harebrain 论坛类别。这里是提问 S4TF 相关问题的地方。
- 为什么 fastai 选择拥抱 S4TF?
第14课:C 语言互操作;协议;整合一切
今天的课程从讨论 Swift 程序员如何用纯 Swift 编写高性能 GPU 代码的方式开始。Chris Lattner 讨论了内核融合、XLA 和 MLIR,这些令人兴奋的技术即将向 Swift 程序员开放。
然后 Jeremy 讨论了现在就可以使用的东西:非常出色的 C 语言互操作。他展示了如何通过与现有 C 库进行接口,快速轻松地获得高性能代码,并以 Sox 音频处理以及 VIPS 和 OpenCV 图像处理作为完整的实际示例。

接下来,我们在 Swift 中实现 Data Block API!嗯……实际上,在某些方面它甚至比原始的 Python 版本更 优秀。我们利用了 Swift 中一个极其强大的特性:协议(protocols)(也称为 类型类)。

我们现在拥有足够的 Swift 知识,可以在 Swift 中实现一个完整的全连接网络前向传播——所以我们就这么做了!然后我们开始研究后向传播,并使用 Swift 可选的 引用语义 来复制 PyTorch 的方法。但随后我们学习如何以更“Swifty”的方式做同样的事情,使用 值语义 以一种非常简洁灵活的方式进行后向传播。
最后,我们将所有内容整合起来,实现我们的通用优化器、Learner、回调等,从头训练 Imagenette!Swift 中的最终笔记本展示了如何在 Swift 中构建和使用 fastai.vision 库的大部分功能,尽管在这两节课中没有时间涵盖所有内容。所以一定要仔细研究笔记本,学习更多 Swift 技巧……
更多信息
- 跳过 FFI:嵌入 Clang 实现 C 语言互操作
- 值语义 演讲,由 @AlexisGallagher
- Tensor Comprehensions:框架无关的高性能机器学习抽象
更多课程
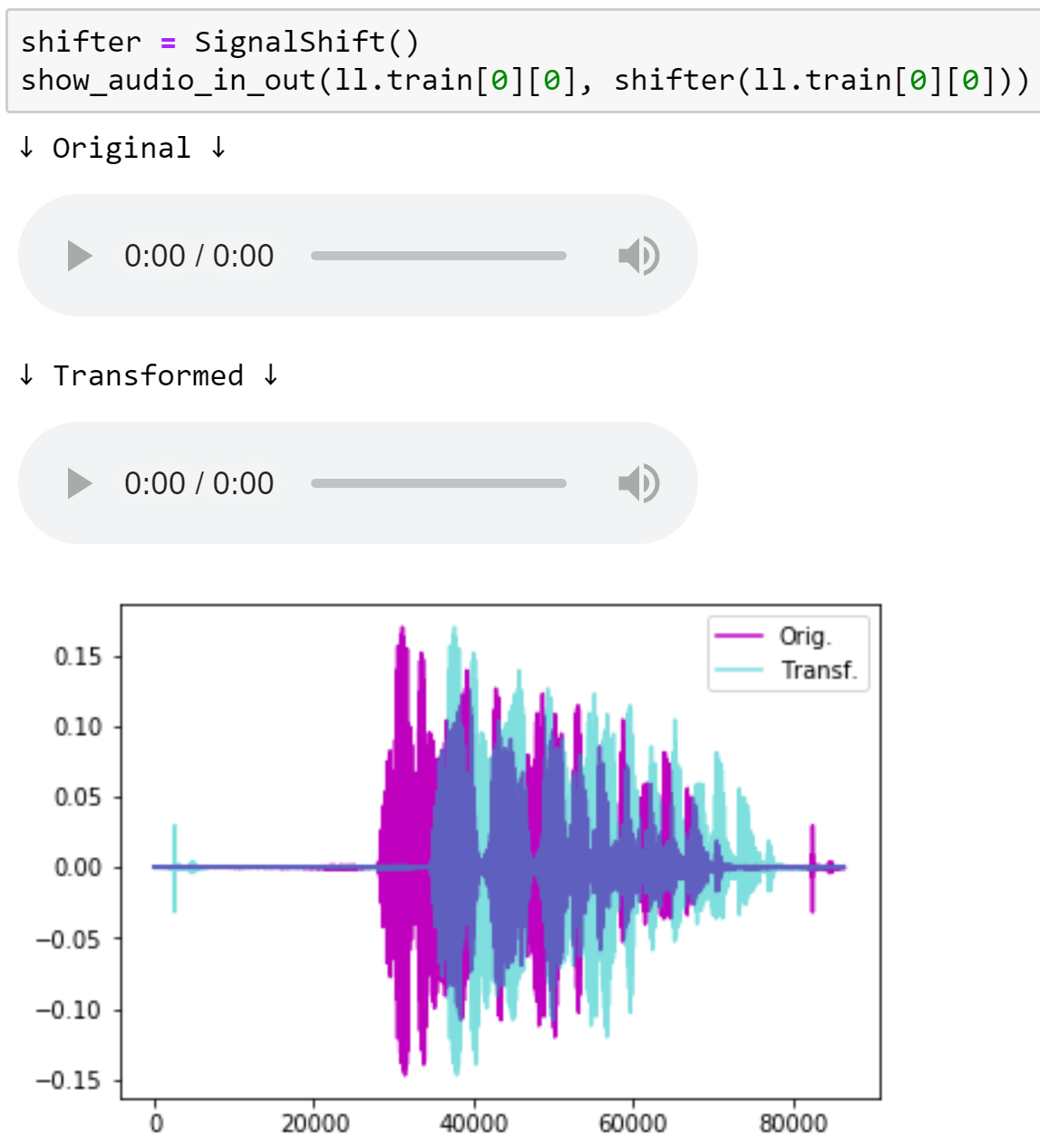
在接下来的几个月里,我们将发布更多课程,并将它们添加到我们将称之为 深度学习应用 的附属课程中。它们将链接到第二部分课程页面,请留意。本系列的第一课将是关于音频处理和音频模型的。我迫不及待地想与大家分享!