我们的最新课程是一门代码优先的自然语言处理入门课程,遵循 fast.ai 的教学理念,即分享实用的代码实现,让学生在深入研究底层细节之前,对“全局”有一个整体认识。课程涵盖的应用包括主题建模、分类(识别评论的情感是积极还是消极)、语言建模和翻译。本课程结合了传统的自然语言处理主题(包括正则表达式、SVD、朴素贝叶斯、分词)和最新的神经网络方法(包括 RNN、seq2seq、注意力机制和 Transformer 架构),同时也讨论了紧迫的伦理问题,例如偏见和虚假信息。主题可以按任何顺序观看。
所有代码都是用 Python 编写在 Jupyter Notebooks 中,使用了PyTorch 和 fastai 库。你可以在GitHub 上找到所有 Notebook 的代码,以及所有课程视频都在此播放列表中。
本课程最初于 2019 年 5 月至 6 月在旧金山大学的数据科学硕士项目中讲授。旧金山大学的数据科学硕士项目已开设 7 年(在此期间,超过 330 名学生毕业并成为数据科学家!),目前设在旧金山市中心的数据研究院。在此之前几年,Jeremy 在项目中教授机器学习课程,我教授了一门计算线性代数选修课作为该项目的一部分。
亮点
我特别激动的一些课程亮点
- 自然语言处理中的迁移学习
- 关于处理非英语语言的技巧
- 注意力机制与Transformer
- 文本生成算法(包括 Allen 研究所一篇新论文的实现)
- 偏见问题以及一些解决步骤
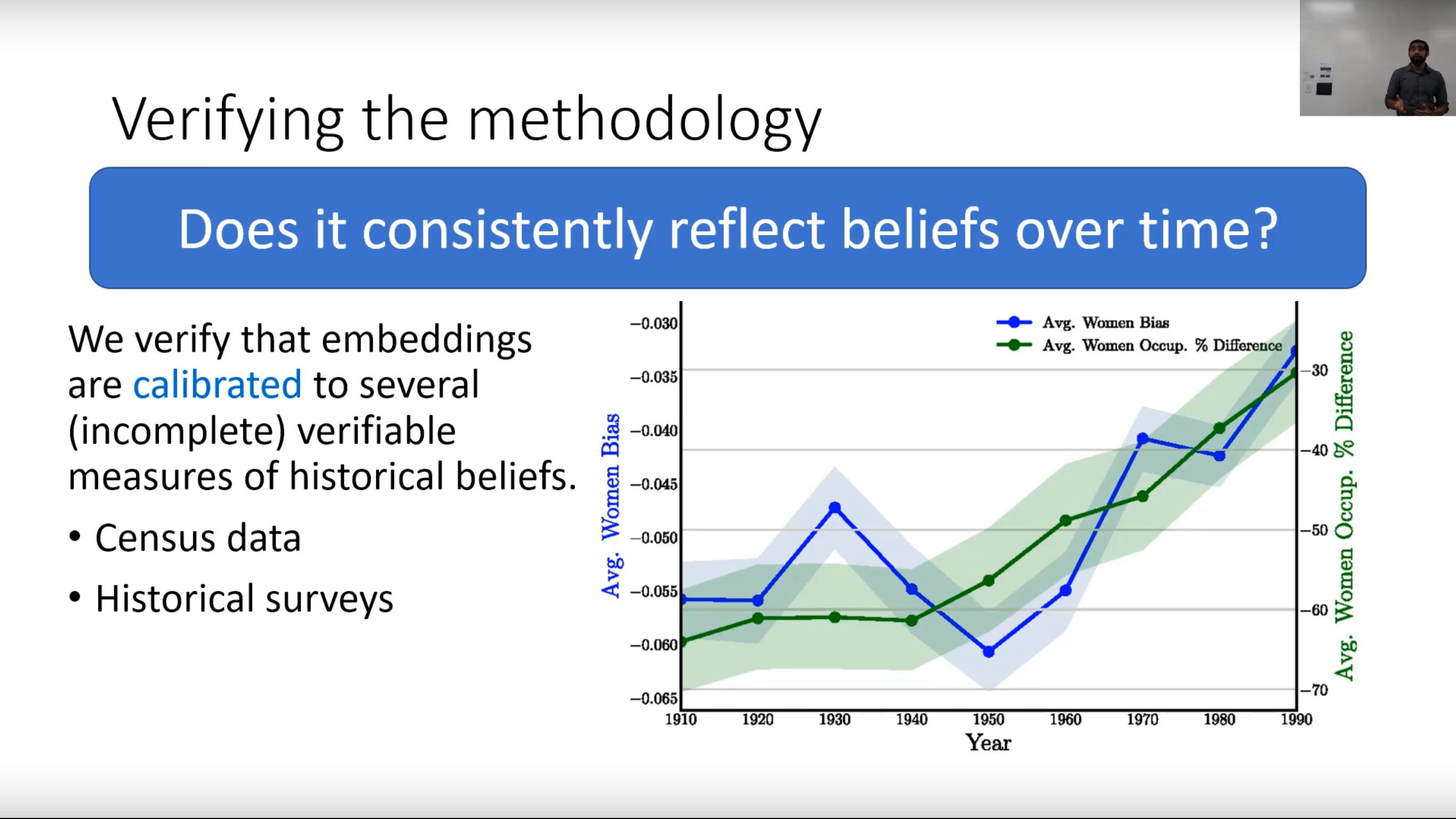
- 由 Nikhil Garg 带来的关于词嵌入如何编码刻板印象(以及这在过去 100 年中如何变化)的特别嘉宾讲座
- 自然语言处理的进步如何加剧了虚假信息的风险

大多数主题都可以独立理解,因此如果你只对特定主题感兴趣,无需按顺序学习本课程(尽管我希望大家都能观看关于偏见和虚假信息的视频,因为这些对于所有对机器学习感兴趣的人来说都很重要)。请注意,视频时长在 20-90 分钟之间。
课程主题
概述
去年,自然语言处理领域取得了许多重大进展,每个月都有新的最先进成果出现。自然语言处理仍然是一个变化迅速的领域,最佳实践不断变化,新标准尚未确定。这使得学习自然语言处理成为一个令人兴奋的时期。本课程结合了更传统的技艺、较新的神经网络方法以及紧迫的偏见和虚假信息问题。
传统自然语言处理方法
课程的前三分之一涵盖了使用 SVD 进行主题建模、通过朴素贝叶斯和逻辑回归进行情感分类以及正则表达式。在此过程中,我们学习了关键的处理技术,例如分词和数值化。
深度学习:自然语言处理中的迁移学习
Jeremy 分享了循序渐进讲解ULMFit的 Jupyter Notebook,ULMFit 是他去年与 Sebastian Ruder 合作完成的突破性工作,成功地将迁移学习应用于自然语言处理。该技术包括在一个大型语料库上训练语言模型,然后在不同且较小的语料库上进行微调,最后添加一个分类器。这项工作已被 BERT、GPT-2 和 XLNet 等更新的论文所借鉴。在新材料中(伴随 fastai 库的更新),Jeremy 分享了处理非英语语言的技巧,并演示了如何在越南语和土耳其语中实现 ULMFit 的示例。
深度学习:Seq2Seq 翻译与 Transformer
我们将深入探讨简单 RNN 的工作原理的底层细节,然后考虑用于翻译的 seq2seq 模型。我们逐步构建我们的翻译模型,添加诸如教师强制、注意力机制和 GRU 等方法来提高性能。然后我们就可以继续学习 Transformer,并探索一个实现。
![]()
自然语言处理中的伦理问题
自然语言处理提出了重要的伦理问题,例如刻板印象如何编码在词嵌入中,以及边缘化群体的词语通常更容易被分类为有毒。特别荣幸邀请到斯坦福大学博士生 Nikhil Garg 分享他已在 PNAS 上发表的关于此主题的工作。我们还学习了一个更好地理解不同类型偏见成因的框架,质疑我们应该完全避免做哪些工作的重要性,以及解决偏见的一些步骤,例如自然语言处理的数据声明。
偏见并非自然语言处理中唯一的伦理问题。更复杂的语言模型可以生成令人信服的虚假散文,这可能会淹没真实的人类声音或操纵公众舆论。我们涵盖了虚假信息的动态、令人信服的计算机生成文本的风险、OpenAI 分阶段发布 GPT-2 的争议决定,以及一些提出的解决方案步骤,例如验证系统或数字签名。

我们希望你会关注本课程!课程中使用的所有 jupyter notebook 代码都可以在GitHub 上找到,所有视频的播放列表在YouTube 上提供。
先决条件
(更新添加)熟悉在 Python 中处理数据以及机器学习概念(例如训练集和测试集)是必要的先决条件。有一些 PyTorch 和神经网络的经验会有帮助。
一如既往,在 fast.ai 我们建议按需学习(太多学生觉得他们需要花几个月甚至几年的时间学习背景材料,才能开始学习他们真正感兴趣的东西,而很多时候,这些背景材料最终根本不是必需的)。如果你对本课程感兴趣,但不确定自己是否有合适的背景,那就勇敢尝试吧!如果你发现不熟悉的必要概念,你可以随时暂停学习并补习。
另外,请务必查看fast.ai 论坛,那里是提问和分享资源的地方。