更新:本文已扩充为一篇论文,题为指标问题是人工智能的一个根本问题,由Rachel Thomas和David Uminsky撰写,并被2020年数据科学伦理大会接受。该论文版本包含更多基于先前学术工作的论证以及缓解这些危害的框架。
古德哈特定律指出,“当某个度量变成一个目标时,它就不再是一个好的度量。” 从本质上讲,当前大多数人工智能方法所做的就是优化指标。优化指标的做法并非新鲜事物,也并非人工智能独有,但人工智能在这方面可能特别高效(甚至过于高效!)。
理解这一点很重要,因为人工智能会加剧优化指标的风险。虽然指标在其恰当位置时可能有用,但不假思索地应用它们会带来危害。一些最可怕的算法失控案例(例如谷歌算法助长人们转向白人至上主义、教师被算法解雇,或奖励复杂无意义内容的论文评分软件)都源于对指标的过度强调。我们必须理解这种动态,才能理解由于滥用人工智能而面临的紧迫风险。

我们无法衡量那些最重要的事物
指标通常只是我们真正关心的事物的代理。机器学习会自动产生道德风险和错误吗?这篇论文涵盖了一个有趣的例子:研究人员调查了某人电子病历中的哪些因素最能预测未来的中风。然而,研究人员发现,一些最具预测性的因素(如意外伤害、良性乳房肿块或结肠镜检查)作为中风的风险因素并不合理。那么,到底发生了什么?结果表明,该模型只是识别出那些经常利用医疗保健的人。他们实际上没有谁中风的数据(中风是一种脑区域无法获得新氧的生理事件);他们拥有的是关于谁能够获得医疗护理、选择去看医生、接受了必要的检查并在其病历中添加了相应的计费代码的数据。但是许多因素影响着这个过程:谁拥有医疗保险或支付得起共同支付额,谁能请假或找到儿童照料,影响获得准确诊断的性别和种族偏见,文化因素等等。结果,该模型主要识别的是利用医疗保健的人,而不是没有利用的人。
这是不得不使用代理的常见现象的一个例子:你想知道用户喜欢什么内容,所以你衡量他们点击了什么。你想知道哪些老师最有效,所以你衡量他们学生的考试分数。你想了解犯罪情况,所以你衡量逮捕数量。这些事物并不相同。我们确实关心的许多事物是无法衡量的。指标可能有帮助,但我们不能忘记它们只是代理。
再举一个例子,谷歌使用用户观看YouTube的时长作为衡量用户对内容满意度的代理,在谷歌博客上写道:“如果观众观看更多YouTube,这向我们表明他们对找到的内容更满意。” 曾在谷歌/YouTube工作的AI工程师Guillaume Chaslot分享了这如何产生了激励阴谋论的副作用,因为说服用户其他媒体都在撒谎会让他们观看更多YouTube。
指标可以,而且会被操纵
指标几乎不可避免地会被操纵,尤其是在它们被赋予过多权力的情况下。今年春天的一周内,Chaslot从YouTube收集了84,695个视频,分析了观看次数以及推荐这些视频的频道数量。这是他的发现(也在《华盛顿邮报》中有报道)
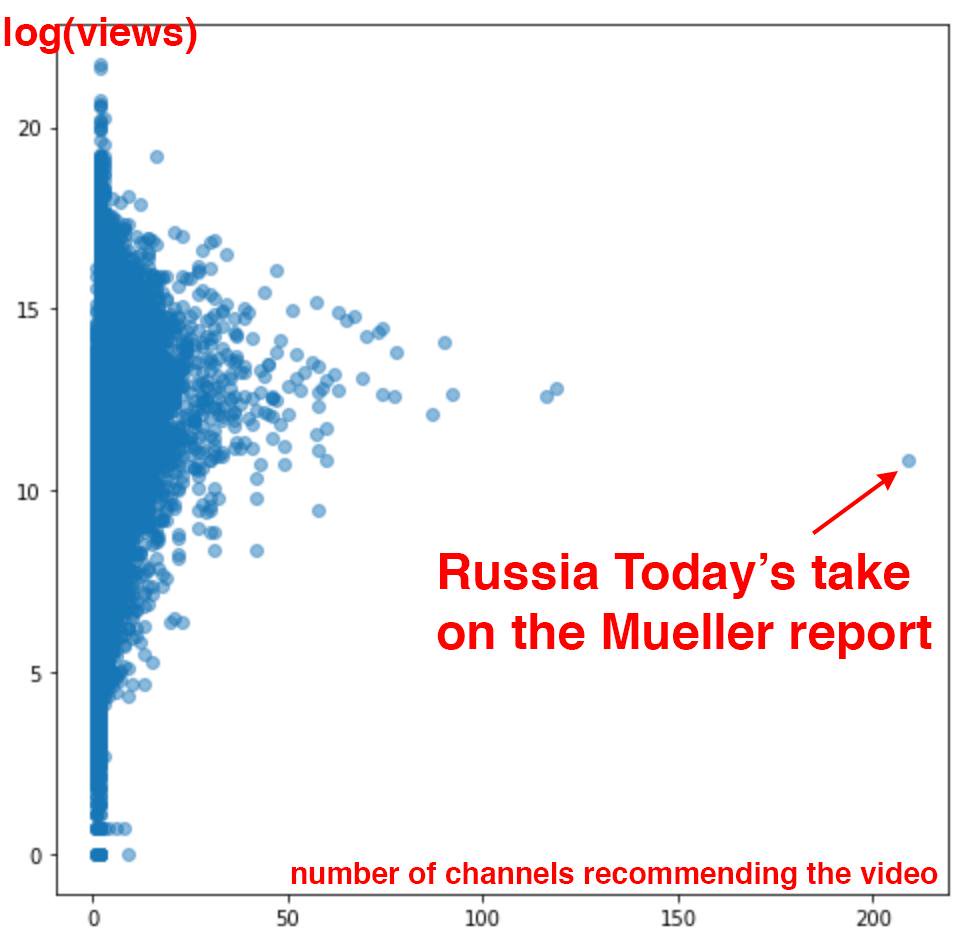
国有媒体“今日俄罗斯”(Russia Today)在YouTube算法选择其被各种其他YouTube频道推荐的程度上是一个极端异常值。这种算法选择在当前视频播放完毕后立即开始自动播放,占用户花在YouTube上时间的70%。这张图表强烈表明,“今日俄罗斯”在某种程度上操纵了YouTube的算法。(关于YouTube推荐系统问题的更多证据在此详细介绍。)平台充斥着操纵算法的尝试,通过虚假点击、虚假评论、虚假粉丝等方式,使其在搜索结果或推荐内容中排名更高。
自动论文评分软件主要侧重于句子长度、词汇量、拼写以及主谓一致等指标,但无法评估写作中难以量化的方面,如创造力。因此,由计算机程序随机生成的包含大量复杂词汇的无意义论文得分很高。来自中国大陆的学生在论文长度和复杂词汇选择上表现出色,他们从算法那里获得的评分比专家人工评分员更高,这表明这些学生可能使用了预先背诵的文本片段。
随着美国教育政策开始过度强调学生考试分数作为评估教师的主要方式,在佐治亚、印第安纳、马萨诸塞、内华达、弗吉尼亚、得克萨斯等地以及其他地方,出现了教师和校长通过修改学生分数进行作弊的广泛丑闻。由此产生的一个后果是,不作弊的教师可能会受到惩罚,甚至被解雇(当学生考试分数在他们的指导下似乎下降到更平均的水平时)。当指标被赋予不应有的重要性时,操纵这些指标的尝试变得司空见惯。
指标倾向于过度强调短期关注点
衡量短期指标要容易得多:点击率、月度用户流失率、季度收益。许多长期趋势涉及复杂的多种因素,更难量化。将您的品牌与宣传恋童癖、白人至上主义和地球平面论联系在一起,会对用户信任产生怎样的长期影响?多年来一直是隐私丑闻、政治操纵和助长种族灭绝的主题,这对招聘会产生怎样的长期影响?
简单地衡量用户点击了什么是一个短期关注点,没有考虑到一篇可能耗时数月研究的长篇调查文章可能产生的潜在长期影响,这样的文章可以帮助塑造读者对复杂问题的理解,甚至可能导致重大的社会变革。
最近一篇《哈佛商业评论》文章以富国银行(Wells Fargo)为例,探讨了让指标取代战略如何损害企业。在将交叉销售确定为衡量长期客户关系的指标后,富国银行过度强调了交叉销售指标:对员工施加巨大压力,再加上不道德的销售文化,导致在未经客户同意的情况下开设了350万个欺诈性存款和信用卡账户。与培养长期客户关系的崇高目标相比,交叉销售的指标是一个更短期的关注点。过度强调指标会使我们忽视价值观、信任、声誉以及对社会和环境的影响等长期关注点,而只会目光短浅地关注短期。
许多指标收集的是我们在高度容易上瘾的环境中的行为数据
我们收集哪些指标以及在何种环境中收集这些指标至关重要。技术公司高度依赖用户点击了什么、他们在网站上花费了多少时间以及“参与度”等指标作为用户偏好的代理,并用于推动重要的商业决策。不幸的是,这些指标是在被设计成高度容易上瘾、充满黑暗模式的环境中收集的,而且在这些环境中,财务和设计决策已经极大地限制了选择范围。

北卡罗来纳大学教授、《纽约时报》常驻撰稿人Zeynep Tufekci将推荐算法(例如YouTube选择哪些视频自动播放给您,以及Facebook决定将什么内容放在您的新闻动态顶部)比作一家将垃圾食品塞进儿童嘴里的自助餐厅。“这有点像学校里的自动驾驶自助餐厅,它发现孩子们喜欢甜食,也喜欢油腻和咸味的食物。于是你设置了一个提供此类食物的队列,一旦年轻人面前的薯条或糖果吃完,下一盘食物就会自动加载。” 随着这些选择变得常态化,结果变得越来越极端:“因此,食物中的糖、脂肪和盐(人类自然渴望的)含量越来越高,而YouTube推荐和自动播放的视频则越来越怪异或充满仇恨。” 我们的许多在线环境都像这样,指标捕捉到我们喜欢糖、脂肪和盐,却没有考虑到我们正处于数字化的食物荒漠中,而且公司并没有被要求在其提供的食物上贴上营养标签。这样的指标并不能表明我们在更健康或更赋能的环境中会喜欢什么。
何时指标有用
所有这些并不是说我们应该彻底抛弃指标。数据在帮助我们理解世界、检验假设以及超越直觉或预感方面可能非常有价值。当指标处于其恰当的背景和位置时,它们会很有用。将指标置于其恰当位置的一种方法是考虑一系列多种指标以获得更全面的图景(并抵制将其归结为单一分数的诱惑)。例如,了解科技公司雇佣来自欠代表群体的人的比例是一个非常有限的数据点。为了评估科技公司的多样性和包容性,我们需要了解可比较的晋升率、股权分配、保留率(许多科技公司就像旋转门,通过其有毒文化将来自欠代表群体的人赶走)、因保密协议而沉默的骚扰受害者人数、低级别安置率等等。即便如此,所有这些数据仍应与倾听在这些公司工作的人的第一手经验相结合。
哥伦比亚大学教授兼《纽约时报》首席数据科学家Chris Wiggins写道,定量度量应始终与定性信息相结合,“由于我们无法预先知道用户将经历的每种现象,因此我们无法预先知道哪些指标将量化这些现象。为此,数据科学家和机器学习工程师必须与用户体验研究人员合作或学习其技能,从而赋予用户发言权。”
将指标置于其恰当位置的另一个关键是让领域专家和最受影响的人员密切参与其开发和使用。大多数教师肯定能够预见到,主要根据学生的标准化考试成绩来评估教师会带来一系列负面后果。
我并不反对指标;我担心的是过度强调指标所造成的危害,这是一种我们在人工智能中经常看到的现象,并且正在产生负面的、现实世界的影响。人工智能不受约束地优化指标已经导致谷歌/YouTube大力推广白人至上主义内容、奖励无意义内容的论文评分软件等等。通过记住指标的风险,我们可以努力预防这些危害。