更新:2020年1月20日:感谢 Yann LeCun 推荐了两篇来自 Facebook AI 的论文:《自监督学习前置不变表示》和 《无监督视觉表示学习的动量对比方法》。我增加了一个“一致性损失”部分,讨论了这些论文中使用的(以及类似的)方法。感谢 Phillip Isola 找到了“自监督学习”一词的早期使用,我已将其添加到文章中。
- 目录 {:toc}
自监督学习简介
只要有可能,你就应该从预训练模型开始神经网络训练,并对其进行微调。你肯定不想从随机权重开始,因为那意味着你正在从一个完全不知道如何做任何事情的模型开始!使用预训练模型,你可以使用比从头开始训练少1000倍的数据。
那么,如果你的领域没有预训练模型怎么办?例如,医学影像领域就很少有预训练模型。最近一篇有趣的论文 《Transfusion: Understanding Transfer Learning for Medical Imaging》 研究了这个问题,发现即使使用少量来自 ImageNet 预训练模型的早期层,也能提高医学影像模型的训练速度和最终准确率。因此,即使与你正在解决的问题领域不符,你也应该使用通用预训练模型。
然而,正如这篇论文所指出的,将 ImageNet 预训练模型应用于医学影像所带来的改进幅度并不大。我们想要一种效果更好但又不需要大量数据的方法。秘诀就是“自监督学习”。这是一种使用输入数据中固有标签而非需要独立外部标签来训练模型的方法。
这个想法源远流长,早在1989年,Jürgen Schmidhuber 在他(超前时代!)1989年的论文 《让世界可微分》 中就讨论过。到1994年,“自监督学习”一词也被用来涵盖一种相关方法,即使用一种模态作为另一种模态的标签,例如论文 《利用未标记数据学习分类》,该论文使用音频数据作为标签,视频数据作为预测器。论文给出了例子:
听到“哞哞”声和看到奶牛往往同时发生
自监督学习是 ULMFiT 的秘诀,这是一种在自然语言处理领域取得巨大进步的训练方法。在 ULMFiT 中,我们首先预训练一个“语言模型”——即学习预测句子下一个单词的模型。我们不一定对语言模型本身感兴趣,但事实证明,能够完成这项任务的模型必须在训练过程中学习语言的本质,甚至了解一些关于世界的信息。当我们随后使用这个预训练的语言模型,并将其微调用于另一项任务,例如情感分析时,结果表明我们可以用很少的数据非常快速地获得最先进的结果。有关其工作原理的更多信息,请参阅这篇 ULMFiT 简介 和语言模型预训练的文章。
计算机视觉中的自监督学习
在自监督学习中,我们用于预训练的任务称为“前置任务(pretext task)”。我们随后用于微调的任务称为“下游任务(downstream tasks)”。尽管自监督学习如今在自然语言处理中几乎普遍使用,但考虑到其效果,在计算机视觉模型中的使用却远不如我们预期的那样广泛。这或许是因为 ImageNet 预训练模型取得了巨大成功,因此像医学影像等领域的人们可能不太熟悉自监督学习的需求。在这篇文章的其余部分,我将尽力简要介绍自监督学习在计算机视觉中的应用,希望能帮助更多人利用这项非常有用的技术。
要在计算机视觉中使用自监督学习,最重要的问题是:“你应该使用哪种前置任务?”事实证明,你可以从中选择很多。下面列出了几种任务及其描述论文,并附有各部分中一篇论文的图片,展示了相关方法。
着色

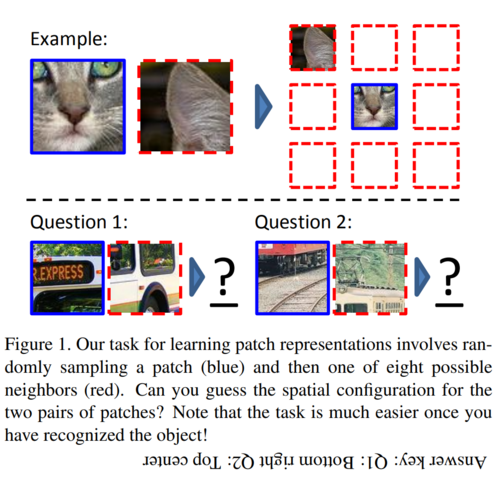
将图像块放置到正确位置
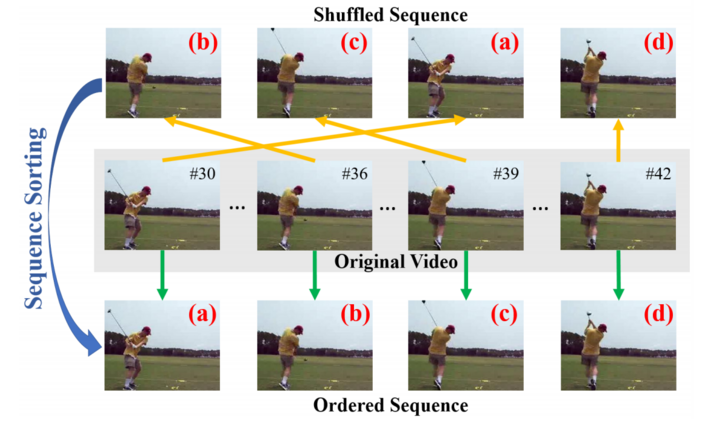
将视频帧按正确顺序排列
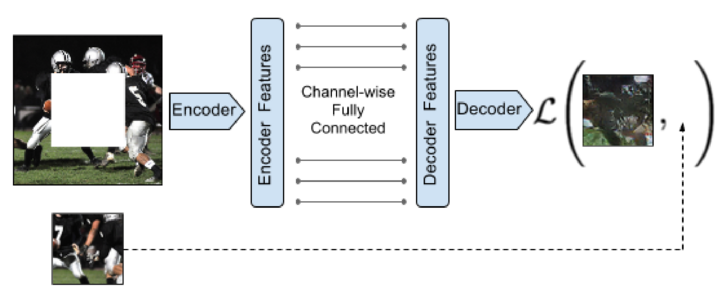
图像修补
(论文)
对损坏的图像进行分类
(论文)

在此示例中,绿色图像未损坏,红色图像已损坏。请注意,过于简单的损坏方案可能导致任务过于容易,并且无法产生有用的特征。上述论文采用了一种巧妙的方法,即损坏自编码器的特征,然后尝试重建它们,以使其成为一个具有挑战性的任务。
选择一个前置任务
你选择的任务需要是这样的:如果解决了它,将需要对你的数据有所理解,这种理解也正是解决下游任务所需的。例如,实践者经常使用一种称为“自编码器”的方法作为前置任务。这是一种模型,它可以接收输入图像,将其转换为大幅缩减的形式(使用瓶颈层),然后再将其尽可能地转换回接近原始图像。这实际上是将压缩作为前置任务。然而,解决这项任务不仅需要重新生成原始图像内容,还需要重新生成原始图像中的任何噪声。因此,如果你的下游任务是生成更高质量的图像,那么这将是一个糟糕的前置任务选择。
你还应该确保前置任务是人类能够完成的任务。例如,你可能使用生成视频未来帧的问题作为前置任务。但是,如果你试图生成的帧在未来太远,那么它可能属于一个完全不同的场景,模型根本无法自动生成它。
为下游任务进行微调
使用前置任务预训练模型后,就可以进行微调了。此时,你应该将其视为迁移学习问题,因此要小心不要损害你的预训练权重。利用 ULMFiT 论文中讨论的方法来帮助你,例如逐步解冻、差异化学习率和 one-cycle 训练。如果你使用 fastai2,只需调用 fine_tune 方法即可自动完成所有这些操作。
总的来说,我建议不要花太多时间去创建完美的前置模型,只需构建一个合理快速且容易的模型即可。然后你可以看看它是否足以满足你的下游任务。通常情况下,事实证明你并不需要一个特别复杂的前置任务就能在下游任务上获得很好的结果。因此,你很容易因为过度设计前置任务而浪费时间。
另请注意,你可以进行多轮自监督预训练和常规预训练。例如,你可以使用上述方法之一进行初始预训练,然后进行分割作为额外的预训练,最后训练你的下游任务。你还可以在一个或两个阶段同时进行多个任务(多任务学习)。当然,首先做最简单的事情,只有当你确定确实需要时再增加复杂度!
一致性损失
在自监督训练之上,你可以添加一个非常有用的技巧,这在自然语言处理中被称为“一致性损失(consistency loss)”,在计算机视觉中被称为“噪声对比估计(noise contrastive estimation)”。基本思想是:你的前置任务会扰乱你的数据,例如遮挡部分、旋转、移动图像块,或者(在自然语言处理中)改变单词或将句子翻译成外语再翻译回来。在每种情况下,你都希望原始项和被“扰乱”的项在前置任务中给出相同的预测,并在中间表示中创建相同的特征。你还希望同一项以两种不同方式被“扰乱”(例如 图像旋转不同的角度)时,也应该具有相同的一致表示。
因此,我们在损失函数中添加一项,惩罚同一数据的不同版本得到不同的结果。这是来自 Google 博文 《通过无监督数据增强推进半监督学习》 的图示表示。
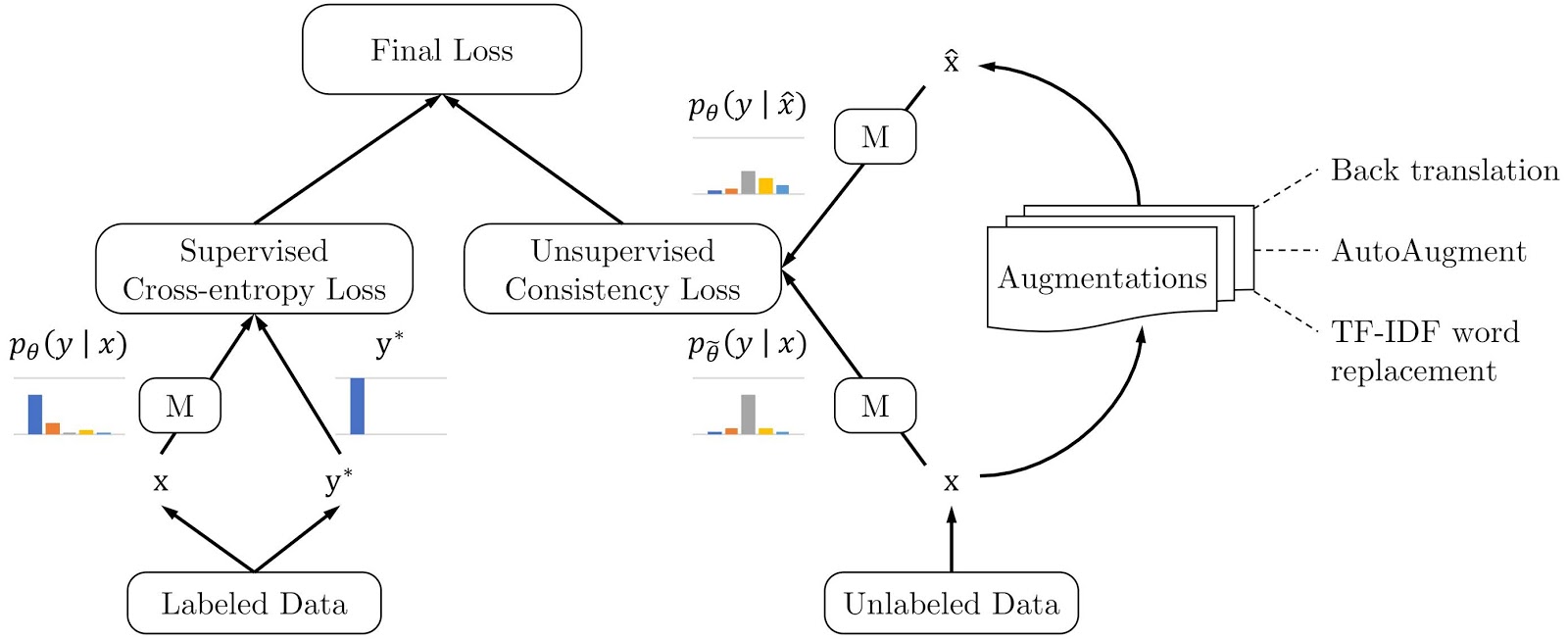
说这“有效”简直是巨大的低估……例如,上述 Google 博文讨论的方法完全、彻底地打破了我们之前使用 ULMFiT 在文本分类方面取得的最先进成果。他们使用的标注数据量比我们少1000倍!
Facebook AI 最近发布了两篇在计算机视觉环境下使用这一思想的论文:《自监督学习前置不变表示》 和 《无监督视觉表示学习的动量对比方法》。与自然语言处理中的 Google 论文一样,这些方法击败了之前最先进的方法,并且需要更少的数据。
你很可能可以将一致性损失添加到你的模型中,几乎适用于你选择的任何前置任务。由于它非常有效,我强烈建议你试一试!
延伸阅读
如果你对学习计算机视觉中的自监督学习更感兴趣,可以看看这些最近的作品