本文介绍 fastai v2。本文的 PDF 版本 可在 arXiv 获取;该版本已通过同行评审,并将发表在开放获取期刊 Information 上。fastai v2 目前处于预发布阶段;我们预计将于2020年7月左右正式发布。预发布版本功能已完整,但文档尚不完整。有一个 专门论坛 用于讨论 fastai v2。Jeremy 将于2020年3月开始在旧金山教授一门关于使用 fastai v2 进行 深度学习的课程。我们(Jeremy 和 Sylvain)撰写的一本关于使用 fastai 和 PyTorch 进行 深度学习的 O’Reilly 图书 已开放预订,预计2020年7月交付。
摘要: fastai 是一个深度学习库,为实践者提供可快速轻松在标准深度学习领域提供最先进结果的高层组件,并为研究人员提供可混合搭配以构建新方法的底层组件。它的目标是在易用性、灵活性或性能方面不做出实质性妥协的同时实现这两个目标。这得益于精心设计的分层架构,该架构以解耦抽象(decoupled abstractions)的形式表达了许多深度学习和数据处理技术的常见底层模式。通过利用底层 Python 语言的动态性以及 PyTorch 库的灵活性,可以简洁明了地表达这些抽象。fastai 包括
- 一种用于 Python 的新型类型分派系统以及张量的语义类型层次结构
- 一个 GPU 优化(GPU-optimized)的计算机视觉库,可用纯 Python 进行扩展
- 一个优化器,它将现代优化器的通用功能重构为两个基本部分,使得优化算法可以用4-5行代码实现
- 一种新颖的双向(2-way)回调系统,可在训练期间访问数据、模型或优化器的任何部分并在任何时候对其进行更改
- 一种新的数据块(data block)API
- ……还有更多。
我们已成功利用该库创建了一门完整的深度学习课程,编写速度比以往更快,且代码更清晰。该库已广泛应用于研究、工业和教学领域。
目录
引言
fastai 是一个现代化的深度学习库,以 Apache 2 许可下开源,可从 GitHub 获取,并可使用 conda 或 pip 包管理器直接安装。它包括完整的文档和教程,并且是书籍 Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD (Howard and Gugger 2020) 的主题。
fastai 围绕两个主要设计目标进行组织:易于入门且快速高效,同时又具有高度可定制性(hackable and configurable)。其他库往往迫使用户在简洁性和开发速度之间做出选择,或在灵活性和表达力之间做出选择,但不能兼得。我们希望兼具 Keras (Chollet 等人 2015) 的清晰度和开发速度以及 PyTorch 的可定制性。这种兼得两者优点的目标推动了分层架构的设计。高层 API 提供即用型函数(ready-to-use functions),用于在各种应用中训练模型,并提供具有合理默认值(sensible defaults)的可定制模型。它建立在提供可组合构建块(composable building blocks)的更低层 API 的层次结构之上。这样一来,想要重写高层 API 的一部分或添加特定行为以满足自身需求的用户,就不必学习如何使用最底层的功能了。
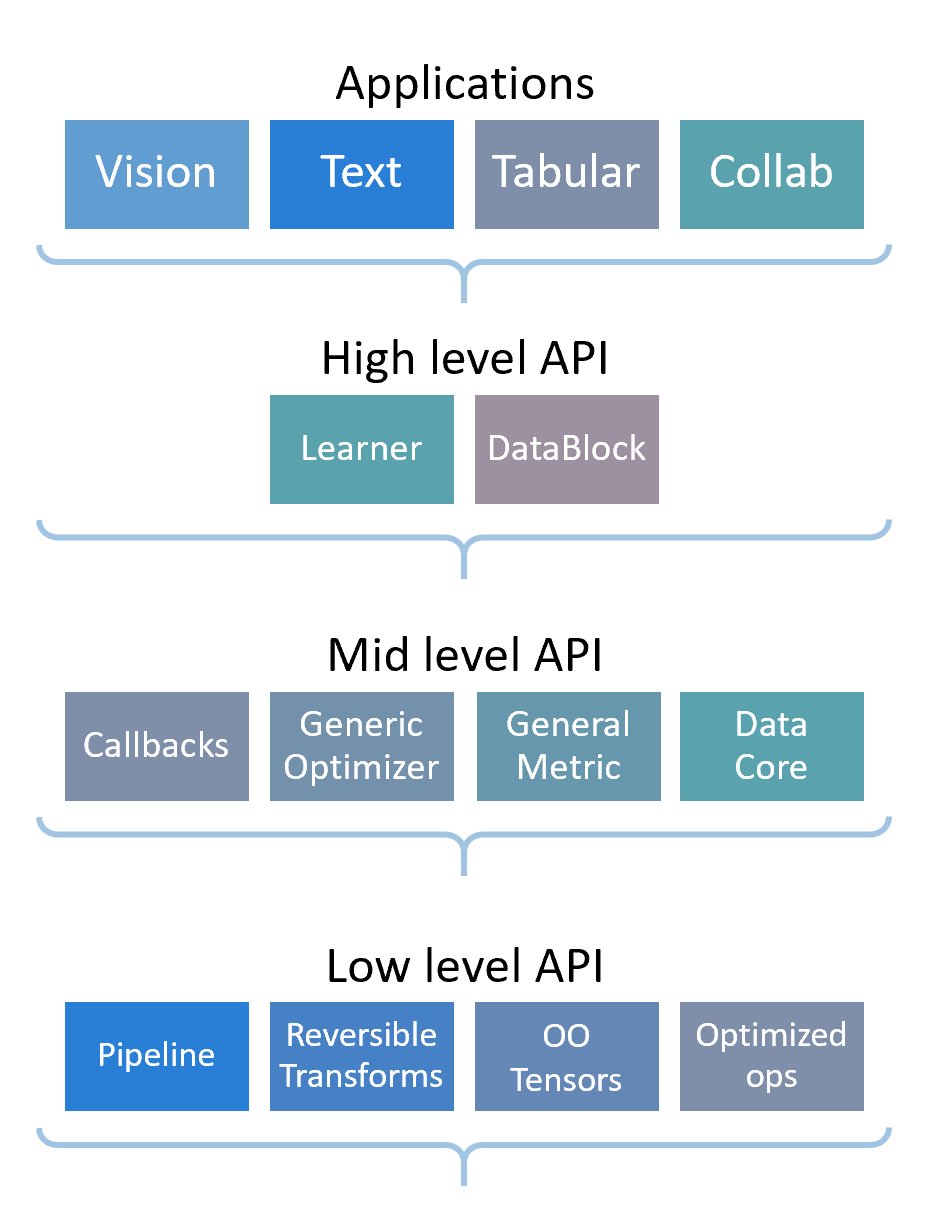
API 的高层最有可能对初学者和主要对应用现有深度学习方法感兴趣的实践者有用。它在四个主要应用领域提供简洁的 API:视觉、文本、表格数据和时间序列分析以及协同过滤。这些 API 基于所有可用信息选择智能默认值和行为。例如,fastai 提供了一个单一的 Learner 类,它将架构、优化器和数据结合在一起,并在可能的情况下自动选择适当的损失函数(loss function)。将这些关注点整合到一个类中,使得 fastai 能够策划(curate)合适的默认选项。再举一个例子,通常训练集应该被打乱(shuffled),而验证集则不需要。因此 fastai 提供了一个单一的 DataLoaders 类,它自动构建处理好这些细节的验证和训练数据加载器(data loaders)。这有助于实践者确保他们不会犯诸如未包含验证集等错误。此外,由于训练集和验证集被整合到一个类中,fastai 默认总能在训练期间使用验证集显示指标(metrics)。
这种智能默认值的使用——基于我们自身的经验或最佳实践——尽可能地扩展到纳入最先进的研究成果。例如,迁移学习(transfer learning)对于快速、准确、经济地训练模型至关重要,但细节非常重要。fastai 自动提供针对迁移学习优化的批归一化(batch-normalization) (Ioffe and Szegedy 2015) 训练、层冻结(layer freezing)和判别式学习率(discriminative learning rates) (Howard and Ruder 2018)。总的来说,库中使用集成默认值意味着用户无需编写太多代码来重新指定信息或仅仅连接组件。因此,用户的每一行代码更有可能具有意义,且更易于阅读。
中层 API 为这些应用提供核心的深度学习和数据处理方法,底层 API 提供经过优化的原语(primitives)库以及函数式(functional)和面向对象(object-oriented)的基础,使得中层 API 得以开发和定制。该库本身构建在 PyTorch (Paszke 等人 2017), NumPy (Oliphant, n.d.), PIL (Clark 和贡献者, n.d.), pandas (McKinney 2010) 和其他各种库之上。为了实现其可定制性的目标,该库不旨在取代或隐藏这些较低层或这些基础。在 fastai 模型内部,用户可以直接与底层 PyTorch 原语进行交互;而在 PyTorch 模型内部,用户可以逐步采用 fastai 库的组件作为便利功能,而非集成包。
我们相信 fastai 达到了其设计目标。用户可以使用四行易于理解的代码,利用迁移学习创建并训练一个最先进的视觉模型。也许更能说明问题的是,我们只需花费几个小时就能实现最新的深度学习研究论文,同时能达到论文中所示的性能。我们还使用该库在 DawnBench 竞赛 (Cody A. Coleman and Zahari 2017) 中获胜,在 ImageNet 上训练 ResNet-50 并在18分钟内达到目标精度。
以下部分将更详细地描述不同 API 层的主要功能,并回顾先前的相关工作。我们选择包含大量代码来阐述我们所提出的概念。尽管随着库或其依赖项的演变,代码可能会略有变化(当前版本为 fastai v2.0.0),但其背后的思想保持不变。下一节将回顾高层 API 在一些最常用的深度学习领域的“开箱即用”(out-of-the-box)应用。提供的应用包括视觉、文本、表格数据和协同过滤。
应用
视觉
这里是一个如何在 Oxford IIT Pets 数据集 (Parkhi 等人 2012) 上微调 ImageNet (Deng 等人 2009) 模型,并在单 GPU 上经过几分钟训练达到接近最先进精度的例子
from fastai.vision.all import *
path = untar_data(URLs.PETS)
dls = ImageDataLoaders.from_name_re(path=path, bs=64,
fnames = get_image_files(path/"images"), pat = r'/([^/]+)_\d+.jpg$',
item_tfms=RandomResizedCrop(450, min_scale=0.75),
batch_tfms=[*aug_transforms(size=224, max_warp=0.), Normalize.from_stats(*imagenet_stats)])
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(4)这不是代码摘录;这是完成此任务所需的所有代码行。每行代码执行一个重要任务,让用户可以专注于他们需要做什么,而不是次要细节。让我们逐行查看
第一行从库中导入所有必需的组件。fastai 设计成既可在读取-求值-打印循环(REPL)环境中使用,也可在复杂的软件系统中使用。即使通常不推荐使用“import *”语法,REPL 程序员通常更喜欢直接获取他们所需的符号,这就是 fastai 支持“import *”风格的原因。该库经过精心设计,以确保通过这种方式导入只会导入对用户真正可能有用的符号,并避免污染命名空间(namespace)或遮蔽(shadowing)重要符号。
第二行从 fast.ai 数据集集合下载标准数据集(如果之前未下载),将其提取到可配置位置(默认为 ~/.fastai/data,如果之前未提取),并返回一个包含提取位置的 pathlib.Path 对象。
此行设置 DataLoaders 对象。这是一个抽象,表示训练和验证数据的组合,将在后面的部分更详细地描述。DataLoaders 可以使用数据块 API(data block API)(参见 3.1)灵活定义,或者像这里一样,使用特定的子类为特定的预定义应用构建。在这种情况下,使用正则表达式标注器(regular expression labeller)创建 ImageDataLoaders 子类。提供了许多其他标注器,尤其侧重于基于不同文件和文件夹名称模式的标注,这在各种数据集中非常常见。
此 API 的一个有趣特性(也被较低层 fastai 数据 API 共享)是项目级(item level)和批级(batch level)变换的分离。项目变换应用于 CPU 上的单个图像。另一方面,批变换应用于 mini batch,如果可用则在 GPU 上进行。虽然 fastai 支持在 GPU 上进行数据增强,但在打包成批次之前,图像需要具有相同大小。aug_transforms() 选择一组数据增强,这些增强在各种视觉数据集和问题中表现良好,并且可以通过向函数提供参数进行完全自定义。这是一个简单的“辅助函数”(helper function)的好例子;它并非严格必要,因为用户可以使用各个数据增强类列出他们所需的所有增强。然而,通过提供一个单一函数来整合最佳实践并将最常见的定制类型通过一个函数提供,用户需要学习的组件更少,从而获得良好结果。
定义 DataLoaders 对象后,用户可以通过一行代码轻松查看数据

这第四行创建一个 Learner,它提供了一个抽象,将优化器、模型和用于训练的数据结合在一起——这将在 4.1 中更详细地描述。每个应用都有一个创建 Learner 的自定义函数,它会自动为用户处理尽可能多的细节。例如,在这种情况下,如果 ImageNet 预训练模型尚不可用,它会下载该模型,移除模型的分类头(classification head),用适用于该特定数据集的头替换它,并为优化器、权重衰减(weight decay)、学习率(learning rate)等设置适当的默认值(除非用户覆盖)。
第五行拟合模型。在这种情况下,它使用了 1cycle 策略 (Smith 2018),这是最近的一种训练最佳实践,默认情况下在大多数深度学习库中并不广泛可用。它对学习率和动量都进行退火(annealing),在验证集上打印指标,在 HTML 表格中显示结果(如果在 Jupyter Notebook 中运行,否则显示为控制台表格),记录每个批次后的损失和指标以便后续绘图等。如果 GPU 可用,将使用 GPU。
训练模型后,用户可以通过各种方式查看结果,包括使用 show_results() 分析错误

这里是另一个视觉应用的例子,这次是 CamVid 数据集 (Brostow 等人 2008) 上的分割(segmentation)任务。
from fastai.vision.all import *
path = untar_data(URLs.CAMVID)
dls = SegmentationDataLoaders.from_label_func(path=path, bs=8,
fnames = get_image_files(path/"images"),
label_func = lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
codes = np.loadtxt(path/'codes.txt', dtype=str),
batch_tfms=[*aug_transforms(size=(360,480)), Normalize.from_stats(*imagenet_stats)])
learn = unet_learner(dls, resnet34, metrics=acc_segment)
learn.fit_one_cycle(8, pct_start=0.9)创建和训练此模型的代码行与分类模型几乎完全相同,只是需要告诉 fastai 输入数据处理方面的差异。与图像分类示例中用于显示数据的完全相同的代码行也可用于显示分割数据

此外,用户还可以查看模型的结果,这些结果同样会自动以适合此任务的方式可视化显示。

文本
在现代自然语言处理(NLP)中,构建模型的最重要方法也许是微调预训练语言模型(pre-trained language models)。在 fastai 中训练语言模型所需的代码与之前的例子非常相似(这里是 IMDb 数据集 (Maas 等人 2011))。
from fastai.text.all import *
path = untar_data(URLs.IMDB_SAMPLE)
df_tok,count = tokenize_df(pd.read_csv(path/'texts.csv'), ['text'])
dls_lm = TextDataLoaders.from_df(df_tok, path=path,
vocab=make_vocab(count), text_col='text', is_lm=True)
learn = language_model_learner(dls_lm, AWD_LSTM, metrics=Perplexity()])
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7,0.8))对该模型进行微调以用于分类需要相同的基本步骤
dls_clas = TextDataLoaders.from_df(df_tok, path=path
vocab=make_vocab(count), text_col='text', label_col='label')
learn = text_classifier_learner(dls_clas, AWD_LSTM, metrics=accuracy)
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7,0.8))也使用相同的 API 查看 DataLoaders

创建文本应用的最大挑战通常在于输入数据的处理。fastai 提供了一个灵活的处理流水线,其中包含预定义的最佳实践规则,例如通过添加 token 来处理大小写。例如,将所有文本转为小写会丢失信息,而保留原始大小写会导致词汇表中 token 过多,这两者之间需要权衡。fastai 的处理方式是:添加一个特殊的单个 token,表示下一个符号应被视为大写或句首大写,然后将文本本身转换为小写。fastai 使用了许多这样的特殊 token。另一个例子是,连续三个以上重复字符会被替换为一个特殊的重复 token,后跟重复次数和重复字符。这些规则基本复制了 (Howard and Ruder 2018) 中讨论的方法,且通常不作为默认功能在大多数 NLP 建模库中提供。
分词(tokenization)灵活,可支持许多不同的组织者。默认使用 Spacy。库中也提供了 SentencePiece 分词器 (Kudo and Richardson 2018)。子词分词(Subword tokenization) (Wu 等人 2016) (Kudo 2018),例如 SentencePiece 提供的,已在许多近期 NLP 的突破中得到应用 (Radford 等人 2019) (Devlin 等人 2018)。
数值化(Numericalization)和词汇表创建通常需要大量代码,且在此处的仔细管理容易出错,包括缓存。在 fastai 中,这被透明且自动地处理。输入数据可以许多不同形式提供,包括:每个文档对应磁盘上的一个单独文件、各种格式的分隔文件等。API 也允许完全自定义。SentencePiece 对于处理多种语言特别有用,并与 fastai 一起用于 MultiFIT (Eisenschlos 等人 2019) 中的这一目的。这使得使用单一代码库就能在多种不同语言上获得模型和最先进的结果。
fastai 的文本模型基于 AWD-LSTM (Merity, Keskar, and Socher 2017)。用户社区提供了连接流行的 HuggingFace Transformers 库 (Wolf 等人 2019) 的外部连接器。模型的训练方式与视觉示例相同,会自动选择适用于这些模型的默认值。据我们所知,没有其他库直接支持 NLP 中的迁移学习最佳实践,例如 (Howard and Ruder 2018) 中所示的那些。由于分词构建在分层架构之上,用户可以用自己的选择替换基础分词器,并自动获得 fastai 提供的底层并行处理模型的支持。它还会自动处理中间输出的序列化(serialization),以便在未来的处理流水线中重用。
模型的训练结果可以使用与图像模型相同的 API 进行可视化,以适合 NLP 的方式显示

表格数据
表格模型在深度学习中并未得到非常广泛的应用;梯度提升机(Gradient boosting machines)和类似方法在工业和研究环境中更为常用。然而,已有使用深度学习赢得竞赛和获得学术最先进结果的例子 (Brébisson 等人 2015)。深度学习模型对于包含高基数类别变量(high cardinality categorical variables)的数据集特别有用,因为它们提供 embeddings,这些 embedding 甚至可以用于非深度学习模型 (Guo and Berkhahn 2016)。挑战之一是,目前还没有直接支持使用深度学习进行表格建模的最佳实践的库示例。
pandas 库 (McKinney 2010) 已为处理表格数据集提供了出色的支持,fastai 不试图取代它。相反,它通过各种预处理函数(pre-processing functions)向 pandas DataFrames 添加附加功能,例如自动添加对建模日期数据有用的特征。fastai 还提供了自动创建适当 DataLoaders 的功能,使用各种机制来分离验证集和训练集,例如随机分割行,或根据某些列选择行。
创建和训练适用于此数据的模型的代码应该看起来很熟悉,只需要在构建 DataLoaders 对象时提供表格数据特定的信息。
from fastai2.tabular.all import *
path = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(path/'adult.csv')
dls = TabularDataLoaders.from_df(df, path,
procs=[Categorify, FillMissing, Normalize],
cat_names=['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race'],
cont_names=['age', 'fnlwgt', 'education-num'],
y_names='salary', valid_idx=list(range(1024,1260)), bs=64)
learn = tabular_learner(dls, layers=[200,100], metrics=accuracy)
learn.fit_one_cycle(3)与其他所有应用一样,dls.show_batch 和 learn.show_results 将显示包含一些样本的 DataFrame。
fastai 还与 NVIDIA 的 cuDF 库集成,提供端到端 GPU 优化的数据处理和模型训练。fastai 是第一个以这种方式与 cuDF 集成的深度学习框架。
协同过滤
协同过滤通常使用概率矩阵分解方法(probabilistic matrix factorisation)进行建模 (Mnih and Salakhutdinov 2008)。然而在实践中,数据集通常不仅仅包含(例如)用户 ID 和产品 ID,还包含用户的许多特征、产品特征、时间段等。使用这些特征来训练模型是相当标准的做法,因此,fastai 试图弥合协同过滤和表格建模之间的差距。fastai 中的协同过滤模型可以简单地看作是一个带有高基数类别变量的表格模型。还提供了经典的矩阵分解模型。两者都使用我们在其他应用中看到的相同步骤进行训练,就像这个使用流行 Movielens 数据集 (Harper and Konstan 2015) 的例子一样
from fastai2.collab import *
ratings = pd.read_csv(untar_data(URLs.ML_SAMPLE)/'ratings.csv')
dls = CollabDataLoaders.from_df(ratings, bs=64, seed=42)
learn = collab_learner(dls, n_factors=50, y_range=[0, 5.5])
learn.fit_one_cycle(3)部署
fastai 主要专注于模型训练,但训练完成后,可以轻松导出 PyTorch 模型以在生产环境中使用。命令 Learner.export 将模型以及输入流水线(仅变换,不包括训练数据)序列化,以便能够将相同的流程应用于新数据。
该库提供 Learner.predict 和 Learner.get_preds 用于评估单个项目或新的推理 DataLoader 上的模型。这样的 DataLoader 可以使用命令 test_dl 轻松地从一组项目构建。
高层API设计考量
高层API基础
高层 API 是使用这些应用的人员所使用的 API。所有 fastai 应用都共享一些基本组件。其中一个组件是可视化 API,它使用少量方法,主要方法是 show_batch(用于显示输入数据)和 show_results(用于显示模型结果)。不同类型的模型和数据集能够使用这个一致的 API,这得益于 fastai 的类型分派系统(type dispatch system),这是一个将在 5.3 中讨论的较低层组件。跨应用共享的迁移学习能力依赖于 PyTorch 的参数组(parameter groups),然后 fastai 的中层 API 利用这些组,例如通用优化器(参见 4.3)。
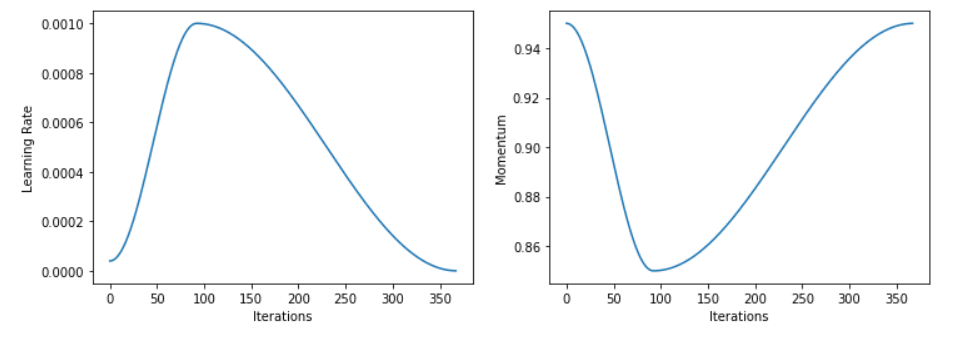
在所有这些应用中,获得的 Learner 都具备相同的模型训练功能。推荐的模型训练方式是使用 1cycle 策略 (Smith 2018) 的一个变体,该变体对学习率使用热身(warm-up)和退火(annealing),而对动量参数执行相反操作。
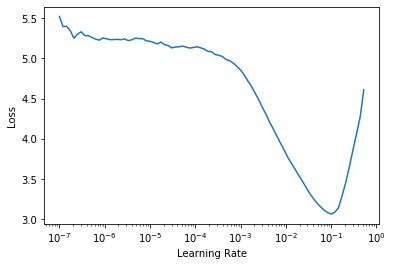
学习率是需要调整的最重要的超参数(通常也是唯一一个,因为库设置了适当的默认值)。其他库通常提供网格搜索(grid search)或 AutoML 来猜测最佳值,但 fastai 库实现了学习率查找器(learning rate finder) (Smith 2015),它在模拟训练(mock training)后更快地为此参数提供最佳值。命令 learn.lr_find() 将返回如下所示的图
另一个重要的高层 API 组件,在所有应用中共享,是 数据块 API(data block API)。数据块 API 是一个富有表现力的数据加载 API。据我们所知,这是首次尝试系统地定义准备深度学习数据所需的所有步骤,并为用户提供一个可组合(mix and match)这些组件(我们称之为 数据块 - data blocks)的指南。数据块 API 定义的步骤是
- 获取源项目,
- 将项目分割为训练集和一个或多个验证集,
- 标注项目,
- 处理项目(例如标准化),以及
- 可选地将项目整理成批次。
这里是一个如何使用数据块 API 使 MNIST 数据集 (LeCun, Cortes, and Burges 2010) 准备好进行建模的例子
mnist = DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter(),
get_y=parent_label)
dls = mnist.databunch(untar_data(URLs.MNIST_TINY), batch_tfms=Normalize)在 fastai v1 及之前版本中,我们对此使用了 fluent API 而非 functional API(意味着执行这些步骤的语句是链式调用的)。我们发现这是一个错误;虽然 fluent API 在用户定义步骤的顺序上很灵活,但在实践中顺序非常重要。有了这个 functional DataBlock,例如,你无需记住是在标注数据之前还是之后进行分割。此外,至少在 Python 中,fluent API 通常与自动补全技术不兼容。数据处理可以使用 Transforms 定义(参见 5.2)。这里是一个使用数据块 API 完成前面看到的相同分割任务的例子
path = untar_data(URLs.CAMVID_TINY)
camvid = DataBlock(blocks=(ImageBlock, ImageBlock(cls=PILMask)),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=lambda o: path/'labels'/f'{o.stem}_P{o.suffix}')
dls = camvid.databunch(path/"images",
batch_tfms=[*aug_transforms(), Normalize.from_stats(*imagenet_stats)])也可以使用相同的功能完成目标检测(object detection)(此处使用 COCO 数据集 (Lin 等人 2014))。
coco_source = untar_data(URLs.COCO_TINY)
images, lbl_bbox = get_annotations(coco_source/'train.json')
lbl = dict(zip(images, lbl_bbox))
coco = DataBlock(blocks=(ImageBlock, BBoxBlock, BBoxLblBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
getters=[noop, lambda o:lbl[o.name][0], lambda o:lbl[o.name][1]],
n_inp=1)
dls = coco.databunch(coco_source, item_tfms=Resize(128),
batch_tfms=[*aug_transforms(), Normalize.from_stats(*imagenet_stats)])在这种情况下,目标是包含两项的元组:一个边界框列表和一个标签列表。这就是为什么有三个块,一个 getter 列表和一个额外参数,用于指定应将多少块视为输入(其余部分构成目标)。
前面看到的语言建模数据也可以使用数据块 API 构建
df = pd.read_csv(untar_data(URLs.IMDB_SAMPLE)/'texts.csv')
df_tok,count = tokenize_df(df, 'text')
imdb_lm = DataBlock(blocks=TextBlock(make_vocab(count),is_lm=True),
get_x=attrgetter('text'),
splitter=RandomSplitter())
dls = imdb_lm.databunch(df_tok, bs=64, seq_len=72)我们从用户那里听说,他们认为数据块 API 在简洁性和表达力之间取得了良好的平衡。许多库提供了各种数据处理方法。在数据科学领域,scikit-learn (Pedregosa 等人 2011) 的 pipeline 方法被广泛使用。这个 API 提供了非常高的表达力水平,但观点不够明确,无法确保用户完成准备数据进行建模所需的所有步骤。再举一个例子,TensorFlow (Abadi 等人 2015) 提供了 tf.data 库,它并没有将用户完成任务所需的步骤与 API 提供的功能精确地对应起来。Torchvision (Massa and Chintala, n.d.) 库是一个很好的例子,它的 API 高度专注于特定子领域的一小部分数据处理任务。fastai 试图在不妥协的情况下捕捉频谱两端的优点;数据块 API 是大多数用户转换数据以与库一起使用的方式。
逐步适配PyTorch代码
用户经常需要使用现有的纯 PyTorch 代码(即不使用 fastai 的代码),例如他们在没有 fastai 的情况下开发的现有代码库,或者使用用纯 PyTorch 编写的第三方代码。fastai 支持逐步将 fastai 特性添加到这些代码中,而无需进行大量重写。
例如,在撰写本文时,官方 PyTorch 仓库包含一个 MNIST 训练示例1。要使用 fastai 的 Learner 训练这个示例,只需要两个步骤。首先,可以删除示例中覆盖 test() 和 train() 函数的30行代码。然后,将训练循环(training loop)的4行代码替换为以下代码
data = DataLoaders(train_loader, test_loader).cuda()
learn = Learner(data, Net(), loss_func=F.nll_loss, opt_func=Adam, metrics=accuracy)
learn.fit_one_cycle(epochs, lr)无需其他修改,用户即可享受 fastai 的所有回调、进度报告(progress reporting)、集成调度器(integrated schedulers)(例如 1cycle 训练)等优势。
跨领域的一致性
正如应用示例所示,fastai 库允许使用非常一致的 API 训练各种应用模型和各种数据集。这种一致性不仅涵盖初始训练,还包括可视化和探索输入数据及模型输出。这种一致性有助于学生,既减少了学习内容,又展示了不同类型模型之间的统一概念。它还有助于实践者和研究人员专注于模型开发,而不是学习跨领域 API 之间的附带差异。例如,当 NLP 专家试图将其专业知识迁移到计算机视觉应用时,这尤其有益。
有许多库为特定应用提供高层 API,例如 Facebook 的 Torchvision (Massa and Chintala, n.d.), Detectron (Girshick 等人 2018) 和 Fairseq (Ott 等人 2019)。然而,每个库都有不同的 API、输入表示(input representation),并对训练细节有不同的假设,用户每次都必须从头开始学习所有这些内容。这意味着有许多深度学习实践者和研究人员成为特定子领域的专家,部分原因在于他们对这些子领域工具(toiling)的理解。通过提供一致的 API,fastai 用户能够快速地在不同领域之间切换并重用他们的专业知识。
自定义预定义应用的行为可能具有挑战性,这意味着研究人员常常“重复造轮子”,或者将自己限制在工具允许自定义的特定部分。因为 fastai 提供了分层架构,软件用户可以根据需要自定义每个部分。分层架构也是允许 PyTorch 用户逐步将 fastai 功能添加到现有代码库的重要基础。此外,fastai 的层在所有应用中都被重用,因此学习这些层的投入可以在许多不同项目中得到利用。
创建分层 API 的方法在软件工程中有着悠久的历史。软件工程的最佳实践包括构建解耦组件,这些组件可以以灵活的方式组合在一起,然后在每个部分之上创建越来越不抽象、越来越定制化的层。
分层 API 设计对于旨在创造一流结果的研究人员和实践者也很重要。随着深度学习领域的成熟,有越来越多的架构、优化器、数据处理流水线和其他方法可供选择。当每种方法使用不同、不兼容的 API,并对模型训练方式有不同预期时,试图将多种方法整合到一个项目中可能极具挑战性。例如,在原始的 mixup 文章 (Zhang 等人 2017) 中,研究人员提供的代码仅适用于一个特定数据集、一套特定指标和一个特定优化器。试图将研究人员的 mixup 代码与其他训练最佳实践(例如混合精度训练 - mixed precision training (Micikevicius 等人 2017))结合,需要从头开始进行大量重写。下一节将介绍 fastai 提供的中层 API 组件,这些组件可以混合搭配,以便快速可靠地创建自定义方法。
中层API
许多库,包括 fastai 版本1或更早版本,为用户提供高层 API,并提供用于内部实现该功能的底层 API,但两者之间没有任何层。这有两个问题:第一个是随着系统变得越来越复杂,创建额外的高层功能变得越来越困难,因为底层 API 变得越来越复杂和混乱。第二个问题是,对于希望自定义和调整系统的用户,他们往往需要重写高层 API 的很大一部分,并且为了这样做,需要理解底层 API 的广泛接口(surface area)。这往往意味着只有一小部分专门的专家社区才能真正自定义软件。
这些问题在几乎所有软件开发中都很常见,许多软件工程师一直努力寻找方法来处理这种复杂性并开发分层架构。然而,深度学习社区的问题在于,这些实践似乎尚未被广泛理解或采纳。然而,也有例外;与本文最相关的是 PyTorch 库 (Paszke 等人 2017),它具有精心设计的分层结构,并且高度可定制。
fastai 的大部分创新在于其新的中层 API。本节将介绍以下中层 API:数据、回调、优化器、模型层和指标。这四个 fastai 应用就是使用这些 API 构建的,并且这些 API 都有完整的文档并对用户开放,以便他们可以构建自己的应用或自定义现有应用。
Learner
如前所述,库可以通过确保类拥有做出适当选择所需的所有信息来提供更合适的默认值和用户友好行为。一个例子是 DataLoaders 类,它汇集了创建建模所需数据的所有必要信息。fastai 还提供了 Learner 类,它汇集了基于数据训练模型所需的所有信息。Learner 所需的信息,并存储在 Learner 对象的状态(state)中,包括:一个 PyTorch 模型、一个优化器、一个损失函数和一个 DataLoaders 对象。传递优化器和损失函数是可选的,在许多情况下 fastai 可以自动选择合适的默认值。
Learner 还负责(与 Optimizer 一起)处理 fastai 的迁移学习功能。创建 Learner 时,用户可以传递一个 分割器(splitter)。这是一个描述如何将模型层分割成 PyTorch 参数组(parameter groups)的函数,这些参数组随后可以被冻结(frozen)、用不同的学习率训练,或由优化器以更一般的方式区别处理。
我们在迁移学习中发现特别敏感的一个领域是批归一化层(batch-normalization layers)的处理 (Ioffe and Szegedy 2015)。我们尝试了各种训练和更新这些层移动平均统计量的方法,不同的配置常常能使错误率改变高达300%。只有一种方法在我们尝试的所有数据集上都始终表现良好,那就是永不冻结批归一化层,也永不关闭其移动平均统计量的更新。因此,默认情况下,当用户要求冻结某些参数组时,Learner 会跳过批归一化层。用户经常报告说,这一个微小的调整显著提高了他们模型的精度,并且据我们所知,这是其他任何库中都没有的。
DataLoaders 和 Learner 也协同工作,确保模型权重和输入数据都在同一设备上。这使得使用 GPU 变得更加简单直接,并可根据需要轻松地从 CPU 切换到 GPU。
双向回调
在 fastai 0.7 版本中,我们反复修改 Learner 中的训练循环以支持许多不同的调整和自定义。然而,随着时间的推移,这变得难以管理(unwieldy)。我们注意到在所有这些调整中都出现了核心功能的子集,并且所有需要的其他更改都可以重构(refactored)为一组特定的自定义点(customization points)。换句话说,可以使用一个单一的通用训练系统来表示各种各样的训练方法。一旦提取出这些通用部分,剩下的就是基本的 fastai 训练循环,以及我们称之为 双向回调(two-way callbacks)的自定义点。
Learner 类新颖的双向(2-way)回调系统允许在训练期间的任何时刻读取和更改梯度(gradients)、数据、损失(losses)、控制流(control flow)以及其他任何东西。使用回调来实现数值软件自定义有着丰富的历史,如今几乎所有现代深度学习库都提供此功能。然而,据我们所知,fastai 的回调系统是第一个支持完整双向回调所需设计原则的系统
- 回调应在训练期间代码可以运行的每一个点可用,以便用户可以自定义训练方法的每一个细节;
- 每个回调应能访问训练循环在该阶段可用的所有信息,包括超参数(hyper-parameters)、损失、梯度、输入和目标数据等;
这是回调通常的设计方式,但此外,还有一个关键设计原则
- 每个回调应能随时在信息使用前修改所有这些信息,并能跳过一个批次(batch)、一个 epoch、训练或验证阶段,或取消整个训练循环。
这就是为什么我们称之为双向(2-way)回调,因为信息不仅从训练循环流向回调,也反方向流动。例如,这里是 fastai 中训练单个批次 b 的代码
try:
self._split(b); self.cb('begin_batch')
self.pred = self.model(*self.x); self.cb('after_pred')
if len(self.y) == 0: return
self.loss = self.loss_func(self.pred, *self.y); self.cb('after_loss')
if not self.training: return
self.loss.backward(); self.cb('after_back')
self.opt.step(); self.cb('after_step')
self.opt.zero_grad()
except CancelBatchException: self.cb('after_cancel')
finally: self.cb('after_batch')此示例清晰展示了过程的每一步如何与回调相关联(调用 self.cb()),并展示了如何利用异常(exceptions)作为其灵活的控制流机制。
在 fastai v0.7 中,我们没有遵循这三个设计原则。结果是,我们不得不频繁更改训练循环以支持附加功能和新的研究论文。另一方面,有了这个新的回调系统,我们完全无需更改训练循环,而是使用了回调来实现 mixup 增强、生成对抗网络(generative adversarial networks)、优化的混合精度训练、PyTorch hooks、学习率查找器等等。最重要的是,我们尚未遇到任何混合搭配这些回调导致问题的案例。因此,用户可以使用他们想要的所有训练功能,并可以轻松进行消融研究(ablation studies),根据需要添加、删除和修改技术。
案例研究:使用回调进行生成对抗网络(generative adversarial network)训练
GANTrainer 是 fastai 回调的一个很好的例子,它实现了生成对抗网络 (Goodfellow 等人 2014) 的训练。为此,它必须完成以下任务
- 冻结生成器(generator),并训练判别器(critic)一个(或多个)步骤,方法是
- 获取一批“真实”图像;
- 生成一批“虚假”图像;
- 让判别器评估每个批次并计算损失函数,该函数积极奖励检测真实图像并惩罚虚假图像;
- 使用此损失的梯度更新判别器的权重。
- 冻结判别器,并训练生成器一个(或多个)步骤,方法是
- 生成一批“虚假”图像;
- 让判别器对其进行评估;
- 返回一个损失,该损失积极奖励判别器认为这些是真实图像;
- 使用此损失的梯度更新生成器的权重。
为此,它依赖于包含生成器和判别器的 GANModule,然后根据标志 gen_mode 的值将输入委托给适当的模型,并依赖于也具有生成器或判别器行为并处理前面提到的评估的 GANLoss。然后,它定义了以下回调方法
-
begin_fit:初始化生成器、判别器、损失函数和内部存储 -
begin_epoch:将判别器或生成器设置为训练模式(training mode) -
begin_validate:切换到生成器模式以显示结果 -
begin_batch:根据是处于生成器模式还是判别器模式设置适当的目标 -
after_batch:记录损失到生成器或判别器日志 -
after_epoch:可选地显示示例图像
然后使用另一个回调对该回调进行自定义,该回调定义何时从判别器切换到生成器,反之亦然。fastai 包括为此目的提供的几种可能性,例如 AdaptiveGANSwitcher,它根据生成器和判别器各自损失达到特定阈值的情况自动切换训练模式。这种训练方法可以使模型的训练比标准的固定调度方法更快更轻松。
通用优化器
fastai 提供了一个新的通用优化器基础,通过将现代优化器的通用功能重构为两个基本部分,使得最新的优化技术可以用少量代码实现
- stats(统计量),它跟踪和聚合统计信息,例如梯度的移动平均值;
- steppers(步进器),它结合统计量和超参数,使用某个函数更新权重。
这使得我们能够在 fastai 中实现我们尝试过的所有优化器,而无需扩展或更改这个基础。这对研究和开发都非常有利。作为开发改进的一个例子,以下是支持解耦权重衰减(decoupled weight decay,也称为 AdamW (Loshchilov and Hutter 2017))所需的全部更改
另一方面,PyTorch 库中的实现需要创建一个全新的类,包含超过50行代码。对研究的好处在于,可以轻松快速地实现新发表的论文,识别不同技术之间的相似点和差异点,并尝试这些底层差异的变体和组合,其中许多尚未发表。生成的代码往往看起来很像论文中所示的数学公式。例如,这里是 fastai 中 LAMB 优化器 (You 等人 2019) 的代码以及论文中的算法

代码和图之间的唯一区别是
- 更新 mt 和 vt 的均值没有出现,因为这在单独的 stat 函数中完成;
- 作者没有提供他们使用的 ϕ 函数的完整定义(它依赖于未定义的参数),下面的代码基于官方的 TensorFlow 实现。
为了支持 LARS 等现代优化器,fastai 允许用户选择是在模型级别、层级别还是激活级别聚合统计量(stats)。
泛化指标API
几乎所有的机器学习和深度学习库都提供对 指标(metrics)的支持。这些通常被定义为简单的函数,用于计算训练期间记录的某个度量的均值,或者在某些情况下使用自定义归约函数(reduction function)。然而,有些指标无法使用这个框架正确定义。例如,Dice 系数(dice coefficient)被广泛用于衡量分割精度,无法直接使用简单的归约表达。
为了提供更灵活的基础来支持这样的指标,fastai 提供了一个 Metric 抽象类(abstract class),它定义了三个方法:reset、accumulate 和 value(这是一个属性)。reset 在训练开始时调用,accumulate 在每个批次后调用,然后最终调用 value 来计算最终检查。因此,只要可能,我们就可以避免在内存中记录和存储所有预测。例如,这里是 Dice 系数的定义
class Dice(Metric):
def __init__(self, axis=1): self.axis = axis
def reset(self): self.inter,self.union = 0,0
def accumulate(self, learn):
pred,targ = flatten_check(learn.pred.argmax(self.axis), learn.y)
self.inter += (pred*targ).float().sum().item()
self.union += (pred+targ).float().sum().item()
@property
def value(self): return 2. * self.inter/self.union if self.union>0 else NoneScikit-learn 库 (Pedregosa 等人 2011) 已经提供了各种各样的有用指标,因此 fastai 没有重新发明它们,而是提供了一个简单的包装函数 skm_to_fastai,允许在 fastai 中使用它们,并且可以自动添加预处理步骤,例如 sigmoid、argmax 和 thresholding。
fastai.data.external
许多库最近开始将对外部数据集的访问直接集成到它们的 API 中。fastai 基于这一趋势,在一个地方整理和收集了许多数据集(由 AWS 公共数据集计划2托管),并通过 fastai.data.external 模块提供访问。fastai 在首次使用这些数据集时会自动下载、提取和缓存它们。这类似于 Torchvision、TensorFlow datasets 和类似库提供的功能,此外还更紧密地集成到 fastai 生态系统中。例如,fastai 提供了许多数据集的精简“样本”版本,这些版本足够小,可以直接在文档、持续集成测试(continuous integration testing)等中使用和下载。这些数据集也用于文档中,以及展示用户使用这些数据集训练模型时可以期望的结果的示例。由于文档是以交互式笔记本(interactive notebooks)的形式编写的(如后面章节讨论),这也意味着用户只需运行和修改文档笔记本,即可直接使用这些数据集和模型进行实验。
funcs_kwargs 和 DataLoader
用户获得数据后,需要将其转换为可以输入到 PyTorch 模型的形式。直接输入模型的最常用类是 PyTorch 中的 DataLoader 类。此类提供快速可靠的多线程数据处理执行,并有多个点允许自定义。然而,我们发现它的灵活性不足以方便地完成我们所需的一些任务,例如为 NLP 语言模型构建 DataLoader。因此,fastai 在 PyTorch 使用的内部类之上包含了一个新的 DataLoader 类。这结合了 PyTorch 提供的快速可靠基础设施的优点,以及为用户提供的更灵活、更具表达力的前端。
DataLoader 通过可自定义方法(customizable methods)提供了15个扩展点(extension points),用户可以根据需要替换这些方法。这些可自定义方法代表了我们已确定的15个数据加载阶段,这些阶段可归为三个主要阶段:样本创建(sample creation)、项目创建(item creation)和批次创建(batch creation)。相比之下,在标准的 PyTorch DataLoader 类中,只有这些阶段的一小部分被明确地提供给用户进行自定义。除非用户的需求可以通过这个子集满足,否则用户被迫从头开始实现自己的解决方案。这种额外可定制性的影响可能非常显著。例如,采用此方法后,fastai 语言模型 DataLoader 的代码量从90行减少到30行。
实现这种灵活性的关键是 Python 装饰器(decorator) funcs_kwargs。这个装饰器创建一个类,在该类中,可以通过向构造函数传递新函数或通过继承来替换任何方法。这允许用户替换 DataLoader 类中的任何一部分逻辑。为了最大限度地发挥其作用,fastai DataLoader 的几乎每个部分都是只有一行代码的方法。因此,用户几乎可以调整每一个设计选择。
fastai 还提供了一个称为 TfmdDL 的转换型 DataLoader,它是 DataLoader 的子类。在 TfmdDL 中,回调和自定义点执行 变换(Transforms)的 流水线(Pipelines)。两种机制都在 5.2 中描述;本节在此提供简要概述。一个 Transform 只是一个 Python 函数,它也可以包含其逆函数(inverse function)——即“撤销”(undoes)该变换的函数。可以使用 Pipeline 类组合变换,这样整个函数组合也可以被逆转。我们将这两个方向,即函数的正向(forward)和逆向(inverse),称为 Transform 的 encodes 和 decodes 方法。
TfmdDL 为应用部分讨论的可视化支持提供了基础,具有显示一批数据的基本模板。为此,它需要 解码(decode)流水线中的任何变换,这是自动完成的。例如,表示类别级别的整数将被转换回该整数所代表的字符串。
fastai.data.core
当需要为数据块 API 创建新类型块的用户,或者需要数据块 API 甚至不支持的自定义级别时,他们可以使用数据块 API 构建所依赖的中层组件。这些是少量简单的类,它们将 fastai 的变换流水线功能与 Python 的集合接口(collections interface)结合起来。
最基础的类是转换列表或 TfmdLists,它对集合进行懒惰地应用变换流水线,同时提供标准的 Python 集合接口。这是深度学习的一个重要基础功能,例如能够按索引访问文件名集合,并按需读取图像文件,然后应用模型所需的任何处理,例如数据增强和标准化。TfmdLists 还提供了 子集(subset)功能,允许用户定义数据子集,例如代表训练集和验证集的子集。项目属于哪个子集的信息会被传递给变换,以确保它们进行适当的处理——例如,数据增强处理通常会跳过验证集,除非进行测试时增强(test time augmentation)。
在该层 API 中另一个重要的数据类是 Datasets,它将多个变换流水线并行应用于单个集合。与 TfmdLists 一样,它提供标准的 Python 集合接口。按索引访问 Datasets 对象会返回一个元组,其中包含每个变换流水线对输入项目的处理结果。这是数据块 API 用于返回例如图像张量和该图像标签的类,两者都源自同一个输入文件名。
层和架构
PyTorch(像许多其他库一样)提供了一个基本的“顺序”(sequential)层对象,可以按顺序组合形成网络的组件。这代表了函数的简单组合,其中每一层的输出是下一层的输入。然而,现代网络架构中的许多组件无法以这种方式表示。例如,ResNet 块 (He 等人 2015) 以及任何其他需要跳跃连接(skip connection)的块,都与顺序层不兼容。在 PyTorch 中,解决这个问题的常用方法是编写自定义的 forward 函数,这实际上是依靠 Python 的全部灵活性来逃避组合这些顺序层的限制。
然而,存在一个显著的缺点:模型现在不再容易进行分析和修改,例如为了进行迁移学习而移除最后几层。这还使得难以支持自动绘制表示模型的图、打印模型摘要(model summary)、按层准确报告模型计算需求等。
因此,fastai 试图提供基础,允许通过堆叠少量预定义构建块来构建现代神经网络架构。该系统的第一部分是 SequentialEx 层。该层具有与 PyTorch 的 nn.Sequential 相同的基础 API,但有一个关键区别:函数的原始输入值对块中的每一层都可用。因此,用户可以例如包含一个将顺序块的当前值添加到顺序块输入值的层(例如在 ResNet 中所做的那样)。
为了充分利用此功能,fastai 还提供了一个 MergeLayer 类。这允许用户传递任何函数,该函数将依次获得层块输入值和顺序块的当前值。例如,如果传入一个简单的加法函数,则 MergeLayer 提供标准 resnet 块中恒等连接(identity connection)的功能。或者,如果用户传入一个拼接函数(concatenation function),则它提供 Densenet 块 (Huang, Liu, and Weinberger 2016) 中拼接连接(concatenating connection)的基础功能。通过这种方式,fastai 提供了原语,允许从预定义构建块表示现代网络架构,而无需回退到 forward 函数中的 Python 代码。
fastai 还提供了一个通用类,用于将这些层组合成各种现代卷积神经网络架构。这些主要基于 ResNet (He 等人 2015) 的底层基础,因此这个类称为 XResNet。通过向此类提供参数,用户可以自定义它以创建包含挤压和激发块(squeeze and excitation blocks) (Hu, Shen, and Sun 2017)、分组卷积(grouped convolutions)(例如 ResNext (Xie 等人 2017))、深度可分离卷积(depth-wise convolutions)(例如 Xception 架构 (Chollet 2016))、加宽因子(widening factors)(例如 Wide ResNets (Zagoruyko and Komodakis 2016))、自注意力(self-attention)和对称自注意力(symmetric self-attention)功能、自定义激活函数等各种架构。通过对这些现代神经网络架构集群进行这种通用重构,我们能够非常轻松地设计和实验新颖的组合。用户也更清楚地了解他们的模型中正在发生什么,因为各种特定的架构被清晰地表示为输入参数的更改。
在实践中非常有用的一组技术是 (He 等人 2018) 中描述的对 ResNet 架构的调整。这些方法在 XResNet 中默认使用。另一种在许多情况下效果良好的架构调整是最近开发的 Mish 激活函数 (Misra 2019)。fastai 包含 Mish 的实现,该实现使用 PyTorch 的即时编译器(just-in-time compiler, JIT)进行了优化。
类似的方法已用于重构 U-Net 架构 (Ronneberger, Fischer, and Brox 2015)。通过研究一系列分割领域的竞赛获奖和最先进论文,我们整理了一套在实践中效果良好的方法。这些在 fastai 的 U-Net 实现中默认可用,该实现还为任何给定输入大小动态创建 U-Net 交叉连接(cross connections)。
底层API
fastai 库的分层方法在其堆栈的较低层具有特定含义。与其将 Python (Python Core Team 2019) 本身视为计算的基础层(中层依赖于它),这些层依赖于较低层提供的一组基本抽象。中层是使用那组抽象进行编程的。fastai 堆栈的底层提供了一组抽象,用于
- 变换流水线:映射并分派到元组元素上的部分可逆组合函数
- 基于数据处理流水线需求的类型分派
- 将语义附加到张量对象,并确保这些语义在整个
Pipeline中得到维护 - GPU 优化的计算机视觉操作
- 便利功能,例如一个用于简化修补现有对象的装饰器,以及一个具有类似 NumPy API 的通用集合类。
本节的其余部分将解释转换管道系统是如何建立在 PyTorch、类型分派和语义张量提供的基础之上,为 fastai 的其余部分提供所需的灵活基础设施。
PyTorch基础
fastai 的主要基础是 PyTorch (Paszke 等人 2017) 库。PyTorch 提供了一个 GPU 优化的张量类、一个有用的模型层库、用于优化模型的类,以及一个集成这些元素的灵活编程模型。fastai 使用 PyTorch 库各个部分的构建模块,包括直接修补其张量类、完全替换其优化器库、提供简化的机制来使用其钩子等等。在 fastai 早期的原型中,我们使用 TensorFlow (Abadi 等人 2015) 作为我们的平台(在此之前使用 (Theano Development Team 2016)),但后来转向 PyTorch,因为我们发现它有一个快速的核心、一个简单且精心设计的 API,并且在研究社区中迅速普及。目前,顶尖深度学习会议的大多数论文都是使用 PyTorch 实现的。
fastai 构建在许多其他开源库之上。对于 CPU 图像处理,fastai 使用并扩展了 Python 图像库 (PIL) (Clark 和 Contributors, 无日期);对于读取和处理表格数据,它使用 pandas;对于大多数度量,它使用 Scikit-Learn (Pedregosa 等人 2011);对于绘图,它使用 Matplotlib (Hunter 2007)。这些是 Python 开源数据科学社区中最广泛使用的库,并为 fastai 库提供了必要的功能。
变换和流水线
一个关键的动机是经常需要能够撤销应用于创建用于建模的数据的某些转换子集。表示类别的字符串不能直接用于模型中,需要使用某个词汇表将其转换为整数。图像的像素值通常会被归一化。这两者都不能直接可视化,因此在推理时我们需要应用这些函数的逆函数来获得可理解的数据。因此,fastai 引入了一个 Transform 类,它提供可调用对象以及一个 decode 方法。decode 方法旨在反转转换提供的函数;它需要用户手动实现;它类似于 Scikit-Learn (Pedregosa 等人 2011) 管道和转换器中可以提供的 inverse_transform。通过在一个地方提供 encode 和 decode 方法,用户最终得到一个可以组合到管道中、序列化等操作的单个对象。
API 这一部分的另一个动机是洞察到 PyTorch 数据加载器提供元组,而 PyTorch 模型期望元组作为输入。有时这些元组应该以连接和依赖的方式表现,例如在分割模型中,数据增强必须以相同的基础方式应用于独立变量和依赖变量。然而,有时必须对不同类型使用不同的实现;例如,在对分割掩码进行仿射变换时需要最近邻插值,但对于图像通常会使用更平滑的插值函数。
此外,有时转换需要能够完全选择不处理,这取决于上下文。例如,除了进行测试时间增强之外,数据增强方法不应该应用于验证集。因此,fastai 会自动将当前的子集索引传递给转换,允许它们根据子集(例如训练集与验证集)修改其行为。这在很大程度上对用户是隐藏的,因为提供了基础类会自动完成这种依赖于上下文的跳过。然而,需要完全定制的高级用户可以直接使用此功能。
深度学习管道中的转换通常需要状态,这可能取决于输入数据。例如,归一化统计数据可能基于数据批次的样本,分类转换可能直接从依赖变量获取其词汇表,或者 NLP 数值化转换可能从输入语料库中使用的令牌获取其词汇表。因此,fastai 转换和管道支持一个 setup 方法,可用于在设置 Pipeline 时创建此状态。当设置管道时,管道中所有先前的转换会首先运行,以便正在设置的转换接收与其在调用时相同的数据结构。
这与 TfmdList 的实现密切相关。因为 TfmdList 对集合延迟应用管道,所以 fastai 可以在 TfmdList 中连接到集合时自动调用 Pipeline 的 setup 方法。
类型分派
fastai 类型分派系统类似于 Python 标准库中提供的 functools.singledispatch 系统,同时支持对两个参数的多重分派。对两个参数进行分派对于用户希望根据模型的输入和目标定制行为的任何情况都是必要的。例如,fastai 使用它来实现 show_batch 和 show_results 方法。如应用部分所示,这些方法会自动提供模型输入、目标和结果的适当可视化,这需要响应两个参数的类型。在一个示例中,输入是图像,目标是分割掩码,show results 方法会自动使用颜色编码叠加来显示掩码。另一方面,对于图像分类问题,输入将显示为图像,预测和目标将显示为文本标签,并根据它们是否正确进行颜色编码。
它还提供了更具表达性且更简洁的语法来注册额外的分派函数或方法,利用了 Python 最近引入的类型注解语法。下面是创建两个根据参数类型进行分派的不同方法的示例。
@typedispatch
def f_td_test(x:numbers.Integral, y): return x+1
@typedispatch
def f_td_test(x:int, y:float): return x+y这里 f_td_test 对数值类型的 x 和所有 y 有一个通用实现,当 x 是 int 且 y 是 float 时有一个专门的实现。
面向对象语义张量
通过使用 fastai 的转换管道功能(严重依赖类型),中高层 API 可以为用户提供强大的功能、简洁性和表达性。然而,这与 PyTorch 提供的类型不兼容,因为基本的张量类型没有任何可以用于类型分派的子类。此外,对 PyTorch 张量进行子类化是具有挑战性的,因为没有提供实例化子类的基本功能,并且进行任何张量操作都会剥离子类信息。
因此,fastai 提供了一个新的张量基类,可以轻松实例化和子类化。fastai 还修补了 PyTorch 的张量类,以在可能的情况下通过操作尝试维护子类信息。不幸的是,不可能始终在所有可能的操作中完美维护此信息,因此所有 fastai Transform 都会自动适当地维护子类类型。
fastai 还为 Python 图像库类提供了相同的功能,以及用于 Python 内置集合类型、NumPy 数组等的一些基本类型层次结构。
GPU加速数据增强
fastai 库在 GPU 上以批处理级别提供计算机视觉中的大多数数据增强。从历史上看,计算机视觉中的处理流程一直是打开图像并使用 PIL (Clark 和 Contributors, 无日期) 或 OpenCV (Bradski 2000) 等专用库在 CPU 上应用数据增强,然后在将结果传输到 GPU 并用于训练模型之前进行批处理。然而,在现代 GPU 上,像标准 ResNet-50 这样的架构通常会受到 CPU 瓶颈。因此,fastai 在 GPU 上实现了大多数常用函数,使用了 PyTorch 对 grid_sample 的实现(它执行从坐标图和原始图像的插值)。
大多数数据增强是随机仿射变换(旋转、缩放、平移等)、坐标图上的函数(透视扭曲)或应用于像素的简单函数(对比度或亮度变化),所有这些都可以轻松并行化并应用于图像批次。在 fastai 中,我们将所有仿射和坐标变换组合在一个步骤中,以只应用一次插值,从而产生更平滑的结果。大多数其他视觉库不会这样做,在连续应用多个变换时会丢失原始图像的大量细节。

类型分派系统有助于将适当的转换应用于图像、分割掩码、关键点或边界框(用户可以通过编写自己的函数来添加对其他类型的支持)。
便利功能
fastai 还有一些旨在使 Python 更易于使用的附加功能,包括用于列表的类似 NumPy API 的 L 类,以及一些用于简化委托或修补的装饰器。
当一个函数调用另一个函数并向其发送一堆带有默认值的关键字参数时,会使用委托。为了避免重复这些参数,它们通常被分组到 **kwargs 中。问题在于它们随后从委托函数的签名中消失,您无法使用现代 IDE 的工具来获得这些委托参数的 tab 补全或在签名中查看它们。为了解决这个问题,fastai 提供了一个名为 @delegates 的装饰器,它会分析委托函数的签名以更改原始函数的签名。例如,Learner 的初始化有 11 个关键字参数,因此任何创建 Learner 的函数都使用此装饰器以避免全部提及它们。例如,函数 tabular_learner 定义如下:
但当你查看其签名时,你会看到 Learner.__init__ 的 11 个附加参数及其默认值。
Monkey-patching 是 Python 语言中的一项重要功能,用于向现有对象添加功能。fastai 使用 Python 的类型注解系统,通过一个 @patch 装饰器使其更简单、更简洁。例如,fastai 添加 read() 方法到 pathlib.Path 类的方式如下:
@patch
def write(self:Path, txt, encoding='utf8'):
self.parent.mkdir(parents=True,exist_ok=True)
with self.open('w', encoding=encoding) as f: f.write(txt)最后,受 NumPy (Oliphant, 无日期) 库的启发,fastai 提供了一个名为 L 的集合类型,它支持高级索引(fancy indexing),并有许多方法允许用户编写简单且富有表现力的代码。例如,下面的代码接受一个对的列表,选择每对的第二个项,取其绝对值,过滤掉大于 4 的项,并将它们加起来:
L 使用依赖于上下文的功能来简化用户代码。例如,sorted 方法可以接受以下任何一种作为键:一个可调用对象(根据用项调用键的值进行排序)、一个字符串(用作属性名)或一个整数(用作索引)。
nbdev
为了帮助开发这个库,我们构建了一个名为 nbdev 的编程环境,它允许用户创建完整的 Python 包,包括测试和丰富的文档系统,所有这些都在 Jupyter Notebooks (Kluyver 等人 2016) 中进行。nbdev 是一个用于 探索式编程 的系统。探索式编程基于这样一种观察:大多数开发者将大部分时间花在编码、探索和实验上。探索最容易在提示符(或 REPL)下进行,或者使用面向 Notebook 的开发系统,如 Jupyter Notebooks。但这些系统对于“编程”部分来说不够强大,因为它们缺少 IDE 和编辑器提供的功能,如良好的文档查找、良好的语法高亮、与单元测试的集成,以及(最重要的是)生成最终可分发源代码文件的能力。
nbdev 构建在 Jupyter Notebook 之上,并添加了以下对软件开发至关重要的工具:
- 自动创建 Python 模块,遵循最佳实践,例如自动定义带有导出函数、类和变量的
__all__ - 在标准文本编辑器或 IDE 中导航和编辑代码,并将任何更改自动导出回您的 Notebook
- 自动从您的代码创建可搜索、带超链接的文档(如图 [fig:nbdev]所示;任何被反引号包围的词语都会超链接到相应的文档,文档站点中会创建一个侧边栏,其中包含指向每个模块的链接,等等)
- Pip 安装程序(自动上传到 pypi)
- 测试(直接在 Notebook 中定义,并并行运行)
- 持续集成
- 版本控制冲突处理
我们计划在未来的论文中提供更多关于 nbdev 的功能、优势和历史的信息。
相关工作
Python 中的深度学习高层 API 有着悠久的历史,这段历史对 fastai 的发展产生了重大影响。我们发现的第一个 Python 深度学习库是 Calysto/conx,它在 2001 年实现了 Python 的反向传播。自那时以来,出现了数十种高层 API 方法,其中最重要的(按时间顺序排列)可能是 Lasagne (Dieleman 等人 2015)(始于 2013 年)、Fuel/Blocks(始于 2014 年)和 Keras (Chollet 等人 2015)(始于 2015 年)。还有其他方向,例如 Caffe (Jia 等人 2014) 推广的基于配置的方法,以及较低层库,如 Theano (Theano Development Team 2016)、TensorFlow (Abadi 等人 2015) 和 PyTorch (Paszke 等人 2017)。
通用机器学习库的 API 也对 fastai 产生了重要影响。自统计计算早期以来,SPSS 和 SAS 就提供了许多用于数据处理和分析的实用程序。S 语言的发展是一个非常重要的进步,它直接导致了 R (R Core Team 2017)、SPLUS 和 xlisp-stat (Luke Tierney 1989) 等项目。R 在数据处理(主要集中在“Tidyverse” (Wickham 等人 2019))和模型构建(构建在 R 丰富的“公式”系统之上)方面采取的方向表明,一套非常不同的设计选择可以带来非常不同(且有效)的用户体验。Scikit-learn (Pedregosa 等人 2011)、Torchvision (Massa 和 Chintala, 无日期) 和 pandas (McKinney 2010) 是提供函数组合抽象的库示例,这些库(与 fastai 的 Pipeline 一样)旨在帮助用户将数据处理成他们所需的格式(Scikit-Learn 也能对处理后的数据执行学习和预测)。还有一些项目,如 MLxtend (Raschka 2018),它们提供了基于底层编程语言(MLxtend 的情况下是 Python)功能的各种实用程序。
当然,对 fastai 影响最大的是 PyTorch (Paszke 等人 2017);没有它,fastai 将不可能存在。PyTorch API 具有可扩展性和灵活性,并且实现高效。fastai 大量使用了 torch.Tensor 和 torch.nn(包括 torch.nn.functional)。另一方面,fastai 并未大量使用 PyTorch 的更高层 API,如 nn.optim 和 annealing,而是根据上述设计方法和目标独立创建了重叠的功能。
结果与结论
使用 fastai 的早期结果非常积极。我们使用 fastai 库重写了整个 fast.ai 课程“面向程序员的实用深度学习”,该课程包含 14 小时的材料,跨越七个模块,涵盖了本文所述的所有应用(以及一些更多内容)。我们发现,与以前的版本相比,我们能够复制或改进以前版本中的所有结果,并且能够更快、更轻松地创建所需的数据管道和模型。我们还听到了预发布版本库的早期采用者的反馈,他们表示与以前的版本相比,他们能够更快、更轻松地编写深度学习代码和构建模型。fastai 已被选为 PyTorch 官方生态系统的一部分3。根据 2019 年 Kaggle ML & DS 调查4,Kaggle 社区中 10% 的数据科学家已经在使用 fastai。许多研究人员正在使用 fastai 支持他们的工作(例如 (Revay 和 Teschke 2019) (Koné 和 Boulmane 2018) (Elkins, Freitas, 和 Sanz 2019) (Anand 等人 2019))。
基于我们使用 fastai 的经验,我们认为在深度学习中使用分层 API 对研究人员、实践者和学生非常有益。研究人员可以更容易地看到不同领域之间的联系,快速组合和重构想法,并在强大的基线之上运行实验。实践者可以快速构建原型,然后利用 fastai 的 PyTorch 基础构建和优化这些原型,而无需重写代码。学生可以实验模型并尝试变体,而无需在初学思想时被样板代码压垮。
fastai 中表达的基本思想不仅限于在 PyTorch 中使用,甚至不限于 Python。已经有一个 fastai 的部分移植版本到 Swift,称为 SwiftAI (Jeremy Howard, Sylvain Gugger, 和 contributors 2019),我们希望将来看到更多语言和库的类似项目。
致谢
我们要向 Alexis Gallagher 表示深切感谢,他在论文撰写过程中发挥了重要作用,并启发了函数式数据块 API。还要非常感谢 Sebastian Raschka 委托撰写本文并担任本期特刊《Information》的编辑,感谢 Facebook PyTorch 团队在 fastai 开发过程中的所有支持,感谢通过 forums.fast.ai 为 fastai 的开发贡献了许多宝贵想法和拉取请求的全球 fast.ai 社区,感谢 Chris Lattner 和 Swift for TensorFlow 团队帮助开发了 course.fast.ai 上的 Swift 课程和 SwiftAI,感谢 Andrew Shaw 为 nbdev 中 showdoc 的早期原型做出的贡献,感谢 Stas Bekman 为 nbdev 中 git hook 的早期原型以及打包和实用程序做出的贡献,以及感谢 Python 编程语言的开发者,它为 fastai 的功能提供了如此坚实的基础。
参考文献
Abadi, Martı́n, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, et al. 2015. “TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems.” https://tensorflowcn.cn/.
Anand, Sarthak, Debanjan Mahata, Kartik Aggarwal, Laiba Mehnaz, Simra Shahid, Haimin Zhang, Yaman Kumar, Rajiv Ratn Shah, and Karan Uppal. 2019. “Suggestion Mining from Online Reviews Using Ulmfit.”
Bradski, G. 2000. “The OpenCV Library.” Dr. Dobb’s Journal of Software Tools.
Brébisson, Alexandre de, Étienne Simon, Alex Auvolat, Pascal Vincent, and Yoshua Bengio. 2015. “Artificial Neural Networks Applied to Taxi Destination Prediction.” CoRR abs/1508.00021. http://arxiv.org/abs/1508.00021.
Brostow, Gabriel J., Jamie Shotton, Julien Fauqueur, and Roberto Cipolla. 2008. “Segmentation and Recognition Using Structure from Motion Point Clouds.” In ECCV (1), 44–57.
Chollet, François. 2016. “Xception: Deep Learning with Depthwise Separable Convolutions.” CoRR abs/1610.02357. http://arxiv.org/abs/1610.02357.
Chollet, François, and others. 2015. “Keras.” https://keras.org.cn.
Clark, Alex, and Contributors. n.d. “Python Imaging Library (Pillow Fork).” https://github.com/python-pillow/Pillow.
Cody A. Coleman, Daniel Kang, Deepak Narayanan, and Matei Zahari. 2017. “DAWNBench: An End-to-End Deep Learning Benchmark and Competition.” NIPS ML Systems Workshop, 2017.
Deng, J., W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In CVPR09.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” CoRR abs/1810.04805. http://arxiv.org/abs/1810.04805.
Dieleman, Sander, Jan Schlüter, Colin Raffel, Eben Olson, Søren Kaae Sønderby, Daniel Nouri, Daniel Maturana, et al. 2015. “Lasagne: First Release.” https://doi.org/10.5281/zenodo.27878.
Eisenschlos, Julian, Sebastian Ruder, Piotr Czapla, Marcin Kadras, Sylvain Gugger, and Jeremy Howard. 2019. “MultiFiT: Efficient Multi-Lingual Language Model Fine-Tuning.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). https://doi.org/10.18653/v1/d19-1572.
Elkins, Andrew, Felipe F. Freitas, and Veronica Sanz. 2019. “Developing an App to Interpret Chest X-Rays to Support the Diagnosis of Respiratory Pathology with Artificial Intelligence.”
Girshick, Ross, Ilija Radosavovic, Georgia Gkioxari, Piotr Dollár, and Kaiming He. 2018. “Detectron.” https://github.com/facebookresearch/detectron.
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. “Generative Adversarial Nets.” In Advances in Neural Information Processing Systems 27, edited by Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, 2672–80. Curran Associates, Inc. http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
Guo, Cheng, and Felix Berkhahn. 2016. “Entity Embeddings of Categorical Variables.” CoRR abs/1604.06737. http://arxiv.org/abs/1604.06737.
Harper, F. Maxwell, and Joseph A. Konstan. 2015. “The Movielens Datasets: History and Context.” ACM Trans. Interact. Intell. Syst. 5 (4): 19:1–19:19. https://doi.org/10.1145/2827872.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Deep Residual Learning for Image Recognition.” CoRR abs/1512.03385. http://arxiv.org/abs/1512.03385.
He, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. 2018. “Bag of Tricks for Image Classification with Convolutional Neural Networks.” CoRR abs/1812.01187. http://arxiv.org/abs/1812.01187.
Howard, Jeremy, and Sylvain Gugger. 2020. Deep Learning for Coders with Fastai and Pytorch: AI Applications Without a Phd. 1st ed. O’Reilly Media, Inc.
Howard, Jeremy, and Sebastian Ruder. 2018. “Fine-Tuned Language Models for Text Classification.” CoRR abs/1801.06146. http://arxiv.org/abs/1801.06146.
Hu, Jie, Li Shen, and Gang Sun. 2017. “Squeeze-and-Excitation Networks.” CoRR abs/1709.01507. http://arxiv.org/abs/1709.01507.
Huang, Gao, Zhuang Liu, and Kilian Q. Weinberger. 2016. “Densely Connected Convolutional Networks.” CoRR abs/1608.06993. http://arxiv.org/abs/1608.06993.
Hunter, John D. 2007. “Matplotlib: A 2D Graphics Environment.” Computing in Science & Engineering 9 (3): 90.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” CoRR abs/1502.03167. http://arxiv.org/abs/1502.03167.
Jeremy Howard, Sylvain Gugger, and contributors. 2019. SwiftAI. fast.ai, Inc. https://github.com/fastai/swiftai.
Jia, Yangqing, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. 2014. “Caffe: Convolutional Architecture for Fast Feature Embedding.” arXiv Preprint arXiv:1408.5093.
Kluyver, Thomas, Benjamin Ragan-Kelley, Fernando Pérez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, et al. 2016. “Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows.” Edited by F. Loizides and B. Schmidt. IOS Press.
Koné, Ismaël, and Lahsen Boulmane. 2018. “Hierarchical Resnext Models for Breast Cancer Histology Image Classification.” CoRR abs/1810.09025. http://arxiv.org/abs/1810.09025.
Kudo, Taku. 2018. “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates.” CoRR abs/1804.10959. http://arxiv.org/abs/1804.10959.
Kudo, Taku, and John Richardson. 2018. “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing.” CoRR abs/1808.06226. http://arxiv.org/abs/1808.06226.
LeCun, Yann, Corinna Cortes, and CJ Burges. 2010. “MNIST Handwritten Digit Database.” AT&T Labs [Online]. Available: Http://Yann. Lecun. Com/Exdb/Mnist 2: 18.
Lin, Tsung-Yi, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. “Microsoft COCO: Common Objects in Context.” CoRR abs/1405.0312. http://arxiv.org/abs/1405.0312.
Loshchilov, Ilya, and Frank Hutter. 2017. “Fixing Weight Decay Regularization in Adam.” CoRR abs/1711.05101. http://arxiv.org/abs/1711.05101.
Luke Tierney. 1989. “XLISP-STAT: A Statistical Environment Based on the XLISP Language (Version 2.0).” 28. School of Statistics, University of Minnesota.
Maas, Andrew L., Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. “Learning Word Vectors for Sentiment Analysis.” In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, 142–50. Portland, Oregon, USA: Association for Computational Linguistics. http://www.aclweb.org/anthology/P11-1015.
Massa, Francisco, and Soumith Chintala. n.d. “Torchvision.” https://github.com/pytorch/vision/tree/master/torchvision.
McKinney, Wes. 2010. “Data Structures for Statistical Computing in Python.” In Proceedings of the 9th Python in Science Conference, edited by Stéfan van der Walt and Jarrod Millman, 51–56.
Merity, Stephen, Nitish Shirish Keskar, and Richard Socher. 2017. “Regularizing and Optimizing LSTM Language Models.” CoRR abs/1708.02182. http://arxiv.org/abs/1708.02182.
Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, et al. 2017. “Mixed Precision Training.” http://arxiv.org/abs/1710.03740.
Misra, Diganta. 2019. “Mish: A Self Regularized Non-Monotonic Neural Activation Function.” http://arxiv.org/abs/1908.08681.
Mnih, Andriy, and Ruslan R Salakhutdinov. 2008. “Probabilistic Matrix Factorization.” In Advances in Neural Information Processing Systems, 1257–64.
Oliphant, Travis. n.d. “NumPy: A Guide to NumPy.” USA: Trelgol Publishing. https://numpy.com.cn/.
Ott, Myle, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. “Fairseq: A Fast, Extensible Toolkit for Sequence Modeling.” In Proceedings of Naacl-Hlt 2019: Demonstrations.
Parkhi, Omkar M., Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. 2012. “Cats and Dogs.” In IEEE Conference on Computer Vision and Pattern Recognition.
Paszke, Adam, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. “Automatic Differentiation in PyTorch.” In NIPS Autodiff Workshop.
Pedregosa, F., G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, et al. 2011. “Scikit-learn: Machine Learning in Python.” Journal of Machine Learning Research 12: 2825–30.
Python Core Team. 2019. Python: A dynamic, open source programming language. Python Software Foundation. https://pythonlang.cn/.
Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.”
Raschka, Sebastian. 2018. “MLxtend: Providing Machine Learning and Data Science Utilities and Extensions to Python’s Scientific Computing Stack.” The Journal of Open Source Software 3 (24). https://doi.org/10.21105/joss.00638.
R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://r-project.cn/.
Revay, Shauna, and Matthew Teschke. 2019. “Multiclass Language Identification Using Deep Learning on Spectral Images of Audio Signals.”
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” CoRR abs/1505.04597. http://arxiv.org/abs/1505.04597.
Smith, Leslie N. 2015. “No More Pesky Learning Rate Guessing Games.” CoRR abs/1506.01186. http://arxiv.org/abs/1506.01186.
Smith, Leslie N. 2018. “A Disciplined Approach to Neural Network Hyper-Parameters: Part 1 - Learning Rate, Batch Size, Momentum, and Weight Decay.” CoRR abs/1803.09820. http://arxiv.org/abs/1803.09820.
Theano Development Team. 2016. “Theano: A Python framework for fast computation of mathematical expressions.” arXiv E-Prints abs/1605.02688 (May). http://arxiv.org/abs/1605.02688.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, et al. 2019. “HuggingFace’s Transformers: State-of-the-Art Natural Language Processing.” ArXiv abs/1910.03771.
Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, et al. 2016. “Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation.” CoRR abs/1609.08144. http://arxiv.org/abs/1609.08144.
Xie, Saining, Ross Girshick, Piotr Dollar, Zhuowen Tu, and Kaiming He. 2017. “Aggregated Residual Transformations for Deep Neural Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July. https://doi.org/10.1109/cvpr.2017.634.
You, Yang, Jing Li, Jonathan Hseu, Xiaodan Song, James Demmel, and Cho-Jui Hsieh. 2019. “Reducing BERT Pre-Training Time from 3 Days to 76 Minutes.” CoRR abs/1904.00962. http://arxiv.org/abs/1904.00962.
Zagoruyko, Sergey, and Nikos Komodakis. 2016. “Wide Residual Networks.” CoRR abs/1605.07146. http://arxiv.org/abs/1605.07146.
Zhang, Hongyi, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. 2017. “Mixup: Beyond Empirical Risk Minimization.” CoRR abs/1710.09412. http://arxiv.org/abs/1710.09412.