新版本
今天我们发布了面向程序员的实用深度学习 2022——这是 fast.ai 最受欢迎课程的全新重写版本,耗时两年打造。之前的 fast.ai 课程已被来自世界各地、各行各业的数十万学员学习过。fast.ai 的视频观看次数已超过 6,000,000 次!主要区别在于
- 更加注重互动式探索。课程学员将亲手构建简单的 GUI,用于构建决策树、线性分类器和非线性模型,通过这种体验深入直观地理解基础算法的工作原理。
- 使用了更广泛的库和服务组合,包括 Hugging Face 生态系统(Transformers, Datasets, Spaces 和 Model Hub)、Scikit Learn 和 Gradio。
- 涵盖了新的架构,例如 ConvNeXt、Visual Transformers (ViT) 和 DeBERTa v3。
到第二课结束时,学员将已经构建并部署了他们自己的深度学习模型,处理他们自己的数据。许多学员将他们的课程项目发布到我们的论坛。例如,如果你后院有一只不明恐龙,也许你需要这个恐龙分类器!

本年度课程涵盖的主题包括
- 构建和训练用于计算机视觉、自然语言处理、表格数据分析和协同过滤问题的深度学习模型
- 创建随机森林和回归模型
- 如何将你的模型转化为 Web 应用并进行部署
- 使用世界上发展最快的深度学习软件 PyTorch,以及 fastai 和 Hugging Face 等流行库
- 深度学习模型为何以及如何工作,以及如何利用这些知识来提高模型的准确性、速度和可靠性
- 实践中真正重要的最新深度学习技术
- 如何从零开始实现深度学习的基础知识,包括随机梯度下降和完整的训练循环
关于课程
课程共有 9 节课,每节课时长约 90 分钟。本课程基于我们评分五星的图书,该书可免费在线获取。不需要特殊的硬件或软件——课程展示了如何使用免费资源来构建和部署模型。也不需要大学数学——必要的微积分和线性代数会在课程中需要时进行介绍。

本课程由我,Jeremy Howard 主讲。我负责 fastai 的开发,这是整个课程中使用的软件。我使用和教授机器学习已有大约 30 年。我曾在 Kaggle(全球最大的机器学习社区)的机器学习竞赛中连续两年获得全球第一名。在此成功之后,我成为了 Kaggle 的总裁兼首席科学家。自 25 年前首次使用神经网络以来,我领导了许多以机器学习为核心的公司和项目,包括创立第一家专注于深度学习和医疗的公司 Enlitic(被 MIT 技术评论评为“全球最聪明的公司”之一),以及第一家开发完全优化保险定价算法的公司 Optimal Decisions。
学员与成果
许多学员告诉我们,他们如何成为国际机器学习竞赛的多个金牌得主,在国际机器学习竞赛中屡获佳绩,收到顶级公司的 offer,以及研究论文发表。例如,Isaac Dimitrovsky 告诉我们,他“玩机器学习几年了,但一直没真正掌握…… [然后] 去年底学习了 fast.ai 第一部分课程,一下子就懂了”。他接着在享有盛誉的国际 RA2-DREAM Challenge 竞赛中获得了第一名!他利用 fastai 库,开发了一种多阶段深度学习方法,用于评估类风湿关节炎的放射性手足关节损伤评分。
面向程序员的实用深度学习往届学员已进入 Google Brain、OpenAI、Adobe、Amazon 和 Tesla 等组织工作,在 NeurIPS 等顶级会议上发表研究论文,并利用在这里学到的技能创立了初创公司。广受好评的 Camera+ 应用的首席开发者 Petro Cuenca 在完成课程后,为他的产品添加了深度学习功能,该功能随后因其“机器学习魔力”被 Apple 推荐。
人工智能:一种现代方法的作者,前 Google 研究总监 Peter Norvig 评论了我们的书(本课程基于此书),他说:
“深度学习属于每个人”,我们在本书第一章第一节中看到这句话,虽然其他书也可能做出类似的声明,但这本真的兑现了。作者对该领域拥有广泛的知识,但能够以一种非常适合有编程经验但没有机器学习经验的读者的方式进行描述。这本书首先展示示例,只在具体示例的背景下讲解理论。对大多数人来说,这是最好的学习方式。这本书在涵盖计算机视觉、自然语言处理和表格数据处理等深度学习的关键应用方面做得非常出色,同时也涵盖了其他一些书籍可能遗漏的数据伦理等关键主题。
关于深度学习
深度学习是一种计算机技术,通过使用多层神经网络来提取和转换数据——其用例范围从人类语音识别到动物图像分类。许多人认为你需要各种难以找到的资源才能在深度学习中取得好结果,但正如你将在本课程中看到的那样,这些人是错的。这里列出了做世界级深度学习你绝对不需要的几件事:
| 误区(不需要) | 真相 |
|---|---|
| 大量的数学 | 只需高中数学就足够了 |
| 大量的数据 | 我们曾使用不到 50 条数据获得了创纪录的结果 |
| 昂贵的电脑 | 你可以免费获得进行最前沿工作所需的资源 |
课程内容
1: 入门

在最初的五分钟内,你将看到一个完整的端到端示例,展示如何训练和使用一个先进到在 2015 年被认为是研究能力前沿的模型!我们将讨论什么是深度学习和神经网络,以及它们的用途。
我们将探讨深度学习在计算机视觉对象分类、分割、表格分析和协同过滤中的应用示例。
2: 部署
本课程展示了如何设计你自己的机器学习项目,创建你自己的数据集,使用你的数据训练模型,并最终在 Web 上部署应用程序。我们使用 Hugging Face Space 结合 Gradio 进行部署,并使用 JavaScript 在浏览器中实现界面。(部署到其他服务的方法与本课程中的方法非常相似。)
3: 神经网络基础

第 3 课主要讲解深度学习的数学基础,如随机梯度下降 (SGD)、矩阵乘积以及线性函数与非线性激活函数叠加的灵活性。我们特别关注一种流行的组合,称为修正线性单元 (ReLU)。
4: 自然语言 (NLP)
我们研究如何使用自然语言处理 (NLP) 来分析自然语言文档。我们将重点关注 Hugging Face 生态系统,特别是 Transformers 库,以及大量预训练的 NLP 模型。本课程的项目是分类描述美国专利所用短语的相似性。类似的方法可应用于营销、物流和医学等广泛领域的各种实际问题。
5: 从零构建模型
在本课程中,我们将学习如何使用 Python 和 PyTorch 从零开始创建一个神经网络,以及如何实现一个训练循环来优化模型的权重。我们将从单层回归模型开始构建,逐步到含有一个隐藏层的神经网络,然后到一个深度学习模型。在此过程中,我们还将探讨如何使用一个称为 sigmoid 的特殊函数来使二分类模型更容易训练,并学习关于指标。
6: 随机森林
随机森林在 20 年前引发了机器学习的一场革命。它首次提供了一种快速可靠的算法,几乎不对数据形式做任何假设,并且几乎不需要预处理。在第 6 课中,你将学习随机森林的真实工作原理,以及如何从零开始构建一个。同样重要的是,你将学习如何解释随机森林,以便更好地理解你的数据。
7: 协同过滤与嵌入
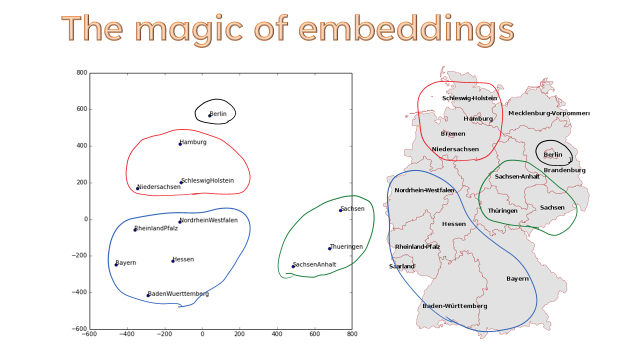
你几乎每天都会与推荐系统互动——这些算法根据你的过去行为来猜测你可能喜欢的产品和服务。这些系统主要依赖于协同过滤,这是一种基于线性代数的方法,用于填充矩阵中的缺失值。在本课程中,我们将看到两种实现方法:一种基于经典的线性代数公式,另一种基于深度学习。我们将通过仔细研究嵌入来结束协同过滤的学习——嵌入是许多深度学习算法的关键组成部分。
8: 卷积 (CNNs)
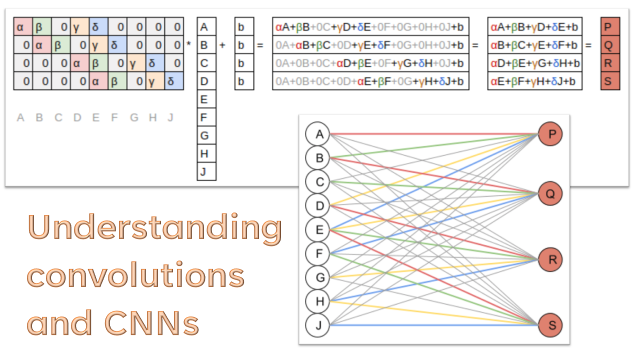
在这里,我们将深入研究卷积神经网络 (CNNs),了解它们是如何真正工作的。我们在之前的课程中使用了大量的 CNN,但我们没有深入窥探其内部,看看里面到底发生了什么。
除了学习 CNN 最基础的构建块——卷积——之外,我们还将探讨池化、Dropout 等。
活跃的社区
许多 fast.ai 校友告诉我们,他们最喜欢这门课程的一点是,围绕课程形成了一个由有趣的人组成的慷慨且富有思考的社区。
如果你需要帮助,或者只是想聊聊你正在学习的内容(或展示你已经构建的作品!),在 forums.fast.ai 有一个很棒的在线社区随时准备为你提供支持。每节课都有专门的论坛帖子——其中许多常见问题都已解答。
对于课程的实时交流,还有一个非常活跃的 Discord 服务器。
开始学习
现在就开始学习课程,请访问 面向程序员的实用深度学习 2022!