Jupyter notebook 默认不支持 git。通过 nbdev2,Jupyter+git 问题已得到彻底解决。它提供了一系列钩子,可以生成干净的 git diff,自动解决大多数 git 冲突,并确保任何剩余冲突都能在标准的 Jupyter notebook 环境中完全解决。要开始使用,请按照Git 友好的 Jupyter 上的说明进行操作。
Jupyter+git 问题
Jupyter notebook 是科学家、工程师、技术作家、学生、教师等的强大工具。它们提供了理想的笔记本环境,用于交互式地探索数据和代码、编写程序以及将结果记录为仪表盘、书籍或博客。
但是,当与他人协作时,这种理想的环境就会化为乌有。这是因为像 git 这样的工具(这是异步协作最流行的方法)使得 notebook 无法使用。字面意思就是这样。如果你和一位同事都修改了同一个 notebook 单元(包括在许多情况下,只是简单地执行一个单元而没有更改它),然后尝试稍后打开该 notebook,情况会是这样:

其原因在于 Jupyter notebook 使用的格式 (JSON) 与 git 冲突标记默认假定的格式(纯文本行)之间存在根本性不兼容。当 git 将其冲突标记添加到 notebook 时,看起来是这样的:
"source": [
<<<<<< HEAD
"z=3\n",
======
"z=2\n",
>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"z"
]这不是有效的 JSON,因此 Jupyter 无法打开它。冲突在 notebook 中尤其常见,因为每次运行 notebook 时,Jupyter 都会更改以下内容:
- 每个单元都包含一个数字,表示其运行顺序。如果你和一位同事以不同的顺序运行单元,那么每个单元都会发生冲突!手动修复这将花费很长时间。
- 对于每个图形,例如绘图,Jupyter 不仅在 notebook 中包含图像本身,还包括一个纯文本描述,其中包含对象的
id(类似于内存地址),例如<matplotlib.axes._subplots.AxesSubplot at 0x7fbc113dbe90>。每次执行 notebook 时,此信息都会更改,因此当两个人执行此单元时,每次都会产生冲突。 - 一些输出可能是非确定性的,例如使用随机数的 notebook,或者与随时间提供不同输出的服务(如天气服务)交互的 notebook。
- Jupyter 会向 notebook 添加元数据,描述上次运行时的环境,例如内核名称。这通常因安装而异,因此两个人保存同一个 notebook(即使没有其他更改)也常常会在元数据中产生冲突。
所有这些对 notebook 文件的更改也会使 notebook 的 git diff 变得非常冗长。这使得代码审查成为一项挑战,并且使 git 仓库比必要的更加臃肿。
这些问题导致许多 Jupyter 用户认为使用 notebook 进行协作是一项笨拙、容易出错且令人沮丧的体验。(我们甚至在社交媒体上看到有人将 Jupyter 的 notebook 格式描述为“愚蠢”或“糟糕”,尽管他们同时声称喜爱这款软件!)
然而,事实证明,Jupyter 和 git 可以非常出色地协同工作,并且完全避免了上述所有问题。所需要的只是一些特殊的软件……
解决方案
Jupyter 和 git 都是设计精良的软件系统,提供了许多强大的可扩展机制。事实证明,我们可以利用这些机制来完全自动地解决 Jupyter+git 问题。我们在上一节中确定了两类问题:
- git 冲突导致 notebook 损坏
- 由元数据和输出引起的不必要冲突。
在我们新发布的nbdev2(一个基于 Jupyter 的开源开发平台)中,我们解决了所有这些问题:
- git 的新 merge driver 提供了“notebook 原生”的冲突标记,使得即使存在 git 冲突,notebook 也能直接在 Jupyter 中打开。
- Jupyter 的新 save hook 自动删除所有不必要的元数据和非确定性的单元输出。
这是使用 nbdev 的合并驱动程序时,冲突在 Jupyter 中显示的样子:
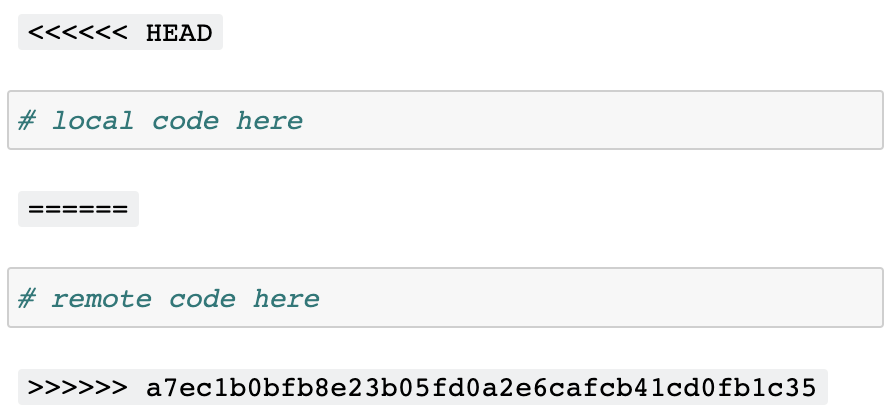
正如你所见,本地和远程的更改在 notebook 中分别清晰地显示为独立的单元,你可以简单地删除你不想保留的版本,或者根据需要合并这两个单元。
使合并驱动程序工作的技术相当引人入胜——让我们深入了解细节吧!
nbdev2 git 合并驱动程序
我们在此提供 git 合并驱动程序的概述——有关完整的详细信息和源代码,请参阅 nbdev.merge 文档。令人惊讶的是,整个实现只有 58 行代码!
基本思想是首先“撤销”产生冲突的原始 git 合并,然后以单元级别(而非行级别)“重做”,并且仅查看单元源代码(而不是输出或元数据)。“撤销”很简单:只需创建冲突文件的两个副本(分别代表文件的本地版本和远程版本),遍历每个 git 冲突标记,并将冲突部分替换为本地或远程版本的代码。
现在我们有了原始的本地和远程 notebook,我们可以使用 execnb.nbio 加载 json,这将为每个 notebook 提供一个单元数组。现在到了有趣的部分——仅基于单元源代码创建单元级别的 diff。
Python 标准库在 difflib 模块中包含了一个非常灵活有效的 diff 算法实现。特别是 SequenceMatcher 类提供了实现您自己的冲突解决系统的基本构建块。我们将两组单元(远程和本地)传递给 SequenceMatcher(...).get_matching_blocks(),它返回匹配的单元段落列表(即没有冲突/差异)。然后我们可以遍历每个匹配段落并将其复制到最终的 notebook 中,并遍历每个不匹配段落,复制进远程和本地单元(在它们之间添加单元来标记冲突)。
使 SequenceMatcher 能够处理 notebook 单元(在 nbdev 中由 NbCell 类表示),只需向 NbCell 添加 __hash__ 和 __eq__ 方法。在每种情况下,这些方法都定义为仅查看实际源代码,而不查看任何元数据或输出。因此,SequenceMatcher 将仅显示源代码中的差异,而忽略其他所有差异。
只需一行配置,我们就可以让 git 在合并更改时调用我们的 Python 脚本,而不是其默认的基于行的实现。nbdev_install_hooks 会自动设置此配置,因此运行它之后,git 冲突会变得少得多,并且绝不会导致 notebook 损坏。
nbdev2 Jupyter 保存钩子
在本地解决 git 合并问题非常有帮助,但我们也需要在远程解决。例如,如果贡献者提交了拉取请求 (PR),而在 PR 合并之前有人对同一个 notebook 进行了提交,那么该 PR 现在可能出现如下冲突:
"outputs": [
{
<<<<<< HEAD
"execution_count": 7,
======
"execution_count": 5,
>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"metadata": {},这个冲突表明两位贡献者以不同的顺序运行了单元(或者其中一位可能在 notebook 中向上添加了几个单元),因此他们的提交具有冲突的执行计数。GitHub 将拒绝允许此 PR 合并,直到此冲突得到解决。
但我们当然根本不关心这个冲突——无论 notebook 中是否存储了执行计数,以及存储了什么计数,都无关紧要。所以我们更希望完全忽略这种差异!
幸好,Jupyter 提供了一个“预保存”钩子,允许在每次保存 notebook 时运行代码。nbdev 使用此钩子设置了一个功能,可在保存时删除所有不必要的元数据(包括 execution_count)。这意味着不会出现上面那样无意义的冲突,因为没有任何提交会首先存储这些信息。
背景
在 fast.ai,我们使用 Jupyter 处理一切。我们所有库的所有测试、文档和模块源代码都完全在 notebook 中开发(当然是使用 nbdev!)。我们所有的库也都使用 git。我们的一些仓库有数百名贡献者。因此,解决 Jupyter+git 问题对我们至关重要。这里提出的解决方案是许多人多年工作的结果。
我们的第一个方法由 Stas Bekman 和我开发,是使用 git “smudge”和“clean”过滤器,在提交时自动重写所有 notebook json 以删除不需要的元数据。这有点帮助,但 git 常常会进入一种奇怪的状态,导致无法合并。
在 nbdev v1 中,Sylvain Gugger 创建了一个名为 nbdev_fix_merge 的神奇工具,它使用非常巧妙的自定义逻辑来手动修复 notebook 中的合并冲突,以确保它们可以在 Jupyter 中打开。对于 nbdev v2,我对库的每个部分都进行了从头重写,我意识到我们可以用上面描述的 SequenceMatcher 方法替换自定义逻辑。
这些步骤都没有完全解决 Jupyter+git 问题,因为我们经常遇到由 smudge/clean git 过滤器引起的合并错误,并且解决冲突需要手动运行 nbdev_fix_merge。Wasim Lorgat 意识到我们可以通过将该逻辑移至 nbdev 保存钩子来解决 smudge/clean 问题,并通过将该逻辑移至 git 合并驱动程序来避免手动修复步骤。这解决了最后剩余的问题!(我实际上对 Wasim 在大约两天内从我们第一次讨论未解决的问题,到弄清楚如何解决所有问题,感到非常震惊……)
结果
nbdev2 中的新工具,我们内部使用已经有几个月了,它彻底改变了我们的工作流程。Jupyter+git 问题已得到彻底解决。我没有看到不必要的冲突,单元级别的合并就像魔法一样奏效,在少数几次与协作者更改同一单元源代码的情况下,在 Jupyter 中修复冲突也变得直接而方便。
后记:其他 Jupyter+git 工具
ReviewNB
我们发现还有一个在使用 Jupyter 和 git 时非常有用的工具,那就是 ReviewNB。ReviewNB 解决了使用 notebook 进行拉取请求的问题。GitHub 的代码审查 GUI 只适用于基于行的文件格式,例如普通的 Python 脚本。这对于 nbdev 导出的 Python 模块来说效果很好,我经常直接在 Python 文件上进行审查,而不是源代码 notebook。
然而,很多时候我宁愿在源代码 notebook 上进行审查,因为:
- 我想审查文档和测试,而不仅仅是实现代码。
- 我想看到单元输出的更改,例如图表和表格,而不仅仅是代码。
为此,ReviewNB 是完美的。就像 nbdev 使 git 合并和提交对 Jupyter 友好一样,ReviewNB 使代码审查对 Jupyter 友好。一张图片胜过千言万语,所以与其尝试解释,我不如直接展示 ReviewNB 网站上的这张图片,说明 PR 在其界面中的样子:

另一种解决方案:Jupytext
解决 Jupyter+git 问题的另一种潜在方案是使用 Jupytext。Jupytext 将 notebook 保存为基于行的格式,而不是 JSON。这意味着所有常用的 git 机制,如合并和 PR,都能正常工作。Jupytext 甚至可以使用 Quarto 的格式 qmd 作为保存 notebook 的格式,然后可用于生成网站。
当您想保存单元输出时,Jupytext 可能有点棘手(我通常希望这样做,因为我的许多 notebook 运行需要很长时间——例如训练深度学习模型)。虽然 Jupytext 可以将输出保存在关联的 ipynb 文件中,但管理这种关联变得复杂,最终又回到了 Jupyter+git 问题!如果您不需要保存输出,那么您可能会觉得 Jupytext 足够了——尽管您当然会错过 ReviewNB 基于单元的代码审查,而且当您的用户在 GitHub 上浏览时,他们将无法正常阅读您的 notebook。
nbdime
还有一个有趣的项目叫做 nbdime,它有自己的 git 驱动程序和过滤器。由于它们与 nbdev 并不是完全兼容(部分原因是它们以不同的方式处理相同的问题),我没有怎么使用它们,因此对它们没有一个深入的看法。不过,我有时会使用 nbdime 的 Jupyter 扩展,它提供了类似于 ReviewNB 的视图,但用于本地更改而不是 PR。
如果你想亲自尝试,请按照Git 友好的 Jupyter 上的说明开始。