在我看来,没有接触过AI伦理的朋友们在ChatGPT4、Bard和Bing Chat发布后开始向我提问。新一代大型语言模型成为头条新闻,引发了广泛的讨论。为了思考新AI应用带来的风险,首先了解几个基本概念很有用。我花费多年时间研究算法系统可能造成损害的机制,并在2021年末就我视为AI伦理核心的关键思想做了一场20分钟的演讲。随着最新一代语言模型的出现,这些概念比以往任何时候都更加重要。
在过去的十年里,诸如可解释性(让计算机解释其计算输出的原因)和公平性/偏见(解决算法在某些人群上的准确性低于其他人群的问题)等话题在AI领域和媒体中获得了更多关注。一些计算机科学家和记者就此止步:他们认为一个能够解释其决策逻辑的计算机程序,或一个在浅肤色男性和深色皮肤女性上具有相同准确性的程序,现在必然是符合伦理的。尽管这些原则很重要,但仅凭它们不足以解决或预防AI系统的损害。
以下是本次演讲的编辑记录。
可操作的补救措施
仅靠可解释性是不够的。考虑一个决定某人是否应该获得贷款的算法系统。通常问题会是“我的贷款为何被拒绝?”,但真正潜在的问题是“我该如何改变我的情况以便将来获得贷款?”
解释应该是可操作的。例如,因种族而拒绝贷款是不可接受的。那是歧视,也无法构成令人满意的解释。对于影响人们生活的决策,还需要有补救机制,以便改变决定。这就是Berk Ustun所描述的可操作的补救措施。
这种可操作的补救措施的基本思想在许多应用中都有体现。我经常会提到一个例子,因为它是一种在许多国家都能看到的模式。在美国,有一个算法用于确定穷人的医疗福利。当它在一个州实施时,代码中存在一个错误,导致脑瘫患者的护理被错误削减。Tammy Dobbs就是因软件错误而失去护理的许多人之一。她需要这种护理来维持非常基本的生活功能:帮助她早上起床、吃早餐等等。她要求解释,但他们没有给她;他们只是说这是算法确定的。本质上,她需要的不仅仅是一个解释,而是一个改变决定的补救机制。最终,这个错误是通过漫长的法庭诉讼才暴露出来的,但这是一种糟糕的安排。

这说明了一个反复出现的普遍问题:自动化系统通常在实施时没有识别和纠正错误的方法。
没有错误捕获机制的原因有几个。自动化通常被用作削减成本的措施,而建立强大的错误检查和错误暴露方法会花费更多。人们可能还会带有偏见,错误地认为计算机是完全准确的。
人权观察组织发布了一份报告,关于欧盟在社会福利中自动化系统的使用情况。许多国家都有令人担忧的例子,存在错误,但却没有明确的方法来识别,更不用说解决这些错误了。法国有一个案例,一个确定食品福利的算法在至少6万个案例中出现了错误。一位女士说,她的个案经理甚至同意这是一个错误,她应该获得福利,但个案经理却没有权力恢复她的福利!

另一个需要考虑的领域是内容审核。圣克拉拉内容审核原则是由一群伦理学家制定的,尽管这些原则并未被主要平台遵守。我想分享原则3,因为我喜欢它的措辞,即公司应提供一个及时且有意义的申诉机会。我非常喜欢这种申诉要有意义和及时的想法。我认为这与内容审核之外的领域也息息相关。很多时候,即使有尝试报告错误的方式,你得到的也只是一个明显未经阅读的自动回复,或者你必须等待数月才能得到答复。重要的是,申诉不仅要可用,还要有意义且及时。
可争议性
可争议性是构建算法系统时,将质疑和不同意结果的机制作为系统的一部分而非外部附加功能包含进去的想法。很多时候,我们构建计算系统时假设一切都会运作良好,然后当出现错误时,再在最后附加一些东西。我认为思考如何将分歧纳入系统的核心这一点颇具启发性。
我在fast.ai的工作中曾从稍有不同的角度思考过这个问题,我们有一个称为增强型机器学习的概念。这与通常旨在端到端自动化流程的自动机器学习不同。在增强型机器学习中,我们真正想思考的是人类擅长哪些事情,以及如何利用人类的优势,而不是简单地尝试自动化一切,然后留下计算机不擅长的奇怪空白。人类和计算机如何才能最好地协同工作?这在系统设计时很重要。
公平性与偏见
考虑公平性和偏见很重要,但这本身是不够的。我想你们很多人都熟悉Joy Boulamwini、Timnit Gebru和Deborah Raji关于面部识别的Gender Shades研究。他们评估了一些知名公司(包括微软、IBM和亚马逊)发布的商业计算机视觉产品。他们发现这些产品在女性上的表现差于男性,在深色皮肤人群上的表现差于浅色皮肤人群,导致对深色皮肤女性的结果非常糟糕。例如,IBM的产品在浅色皮肤男性上的准确率为99.7%,而在深色皮肤女性上只有65%。这对于一款已商业发布的产品来说是巨大的差异。这项研究在引起对这一有害问题的关注方面具有开创性。
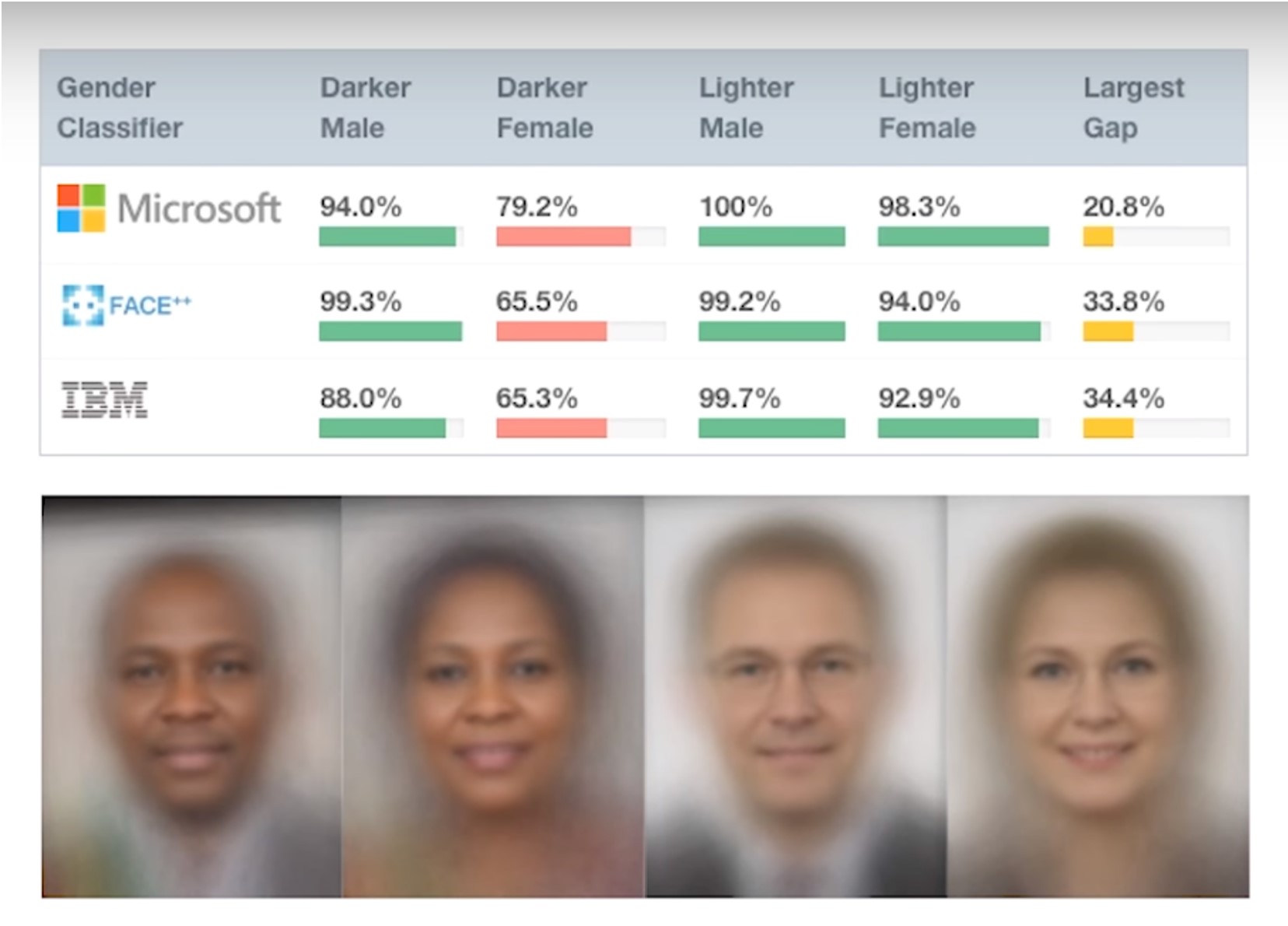
有些人做出了肤浅的回应,这与研究人员的论述不符,他们断定解决方案仅仅是收集更多深色皮肤女性的照片,然后就算完事了。虽然需要解决基础训练数据集中代表性不足的问题,但这只是问题的一部分。我们必须审视这些系统的使用方式,这会带来许多其他重大的损害。
如果不起作用则有害;如果起作用也可能有害
在美国几个城市,警方使用面部识别技术来识别抗议警察种族主义和警察杀害手无寸铁平民的黑人抗议者。当你审视这种技术使用方式时,存在巨大的权力问题。我认为无论它是否奏效,这都是不道德的。误认并逮捕错误的人当然是可怕的,但识别抗议者是对公民权利的威胁。

Timnit Gebru博士写道:“很多时候,人们谈论偏见,是在群体之间实现性能均等化的意义上。他们没有考虑底层基础,即一个任务是否应该首先存在,谁创造它,谁会将其部署到哪个人群上,谁拥有数据,以及如何使用它?”这些都是至关重要的问题。它们是关于权力的问题。是的,你应该检查不同子群体的错误率,但这本身是不够的,并未触及权力问题。
Alvaro Bedoya教授写道:“在整个历史上,监视都被用于对付那些被视为‘低等’的人,对付穷人、有色人种、移民、异教徒。它被用来阻止边缘化人群获得权力。”监视作为一种针对边缘化人群的武器的历史可以追溯到几个世纪以前,早于计算机的出现,但AI现在极大地加速了这种动态。
大规模运作
Robodebt是澳大利亚政府通过自动化系统为数十万人制造非法债务的一个项目。人们会收到通知说他们在福利上被多付了(通常这是假的,但要对此提出异议需要大多数人没有的文件),并且他们现在欠政府大笔钱。这摧毁了许多人的生活,甚至导致一些受害者自杀。令我印象深刻的一个细节是,当这个过程更依赖人工时,每年产生的债务数量是2万笔,而自动化后变成了每周2万笔。这是规模扩大了50倍!自动化被用来大幅度地扩大对穷人制造债务的规模。这是机器学习中另一个令人不安的模式。
权力中心化
机器学习常常会产生权力中心化的影响。它可以被实施而没有补救系统,也没有识别错误的方法,正如我们之前看到的,人们的医疗护理因一个bug而被错误削减。它可以以大规模低成本使用,正如Robodebt所示。它还可以在大规模上复制相同的偏见或错误。
通常当我讲授自动化系统如何造成损害时,人们会指出人类也会犯错和带有偏见。然而,自动化系统存在关键差异。从人工决策者转向自动化决策者并非简单的即插即用式的互换。
自动化系统也可用于逃避责任。这在一般的官僚体系中也是如此。虽然在非自动化的官僚体系中,你也会遇到推卸责任的情况(“我只是奉命行事”或“这是那个人的错”);然而,正如danah boyd所指出的,自动化系统常常被用来延伸官僚体系(正如danah boyd所解释的),增加了更多推卸责任的地方。
在我分享的医疗护理软件错误案例中,一位记者采访了那个算法的创建者。他通过一家私人公司赚取版税,他说提供解释不是公司的责任。他将错误归咎于政策制定者。政策制定者可以责怪实施这个软件的具体人员。每个人都可以指向其他人,甚至指向软件本身。没有人承担责任的系统不会带来好的结果。
反馈循环
当你创造出你试图预测的结果时,就会出现反馈循环。数据可能因模型的输出而受到污染。此外,机器学习模型不仅会编码偏见,还会放大偏见。有多篇论文表明,如果你从一个有偏见的数据集开始训练,你实际上可以训练出一个比训练数据集本身更有偏见的模型。

总之,以上是机器学习可能导致权力中心化以及自动化系统与人工决策者不同的几个原因。AI研究员Pratyusha Kalluri建议我们,与其问一个AI应用是否公平,不如问它如何转移权力。
受影响的人群
关于医疗护理的例子,我还要强调一点:那些医疗护理被错误削减的人们立刻就发现了问题,但却没有办法让这个错误得到承认或解决。
另一个人们发现了问题却无法得到解决的悲惨例子是Facebook在缅甸种族灭绝事件中的作用。2018年,联合国发现Facebook在种族灭绝中“起到了决定性作用”;然而,对于一直关注这些事件的人来说,这并不令人惊讶。一位驻缅甸的科技企业家表示:“这不是事后诸葛亮。这个问题的规模非常大。早在2013年就已经很明显了。”
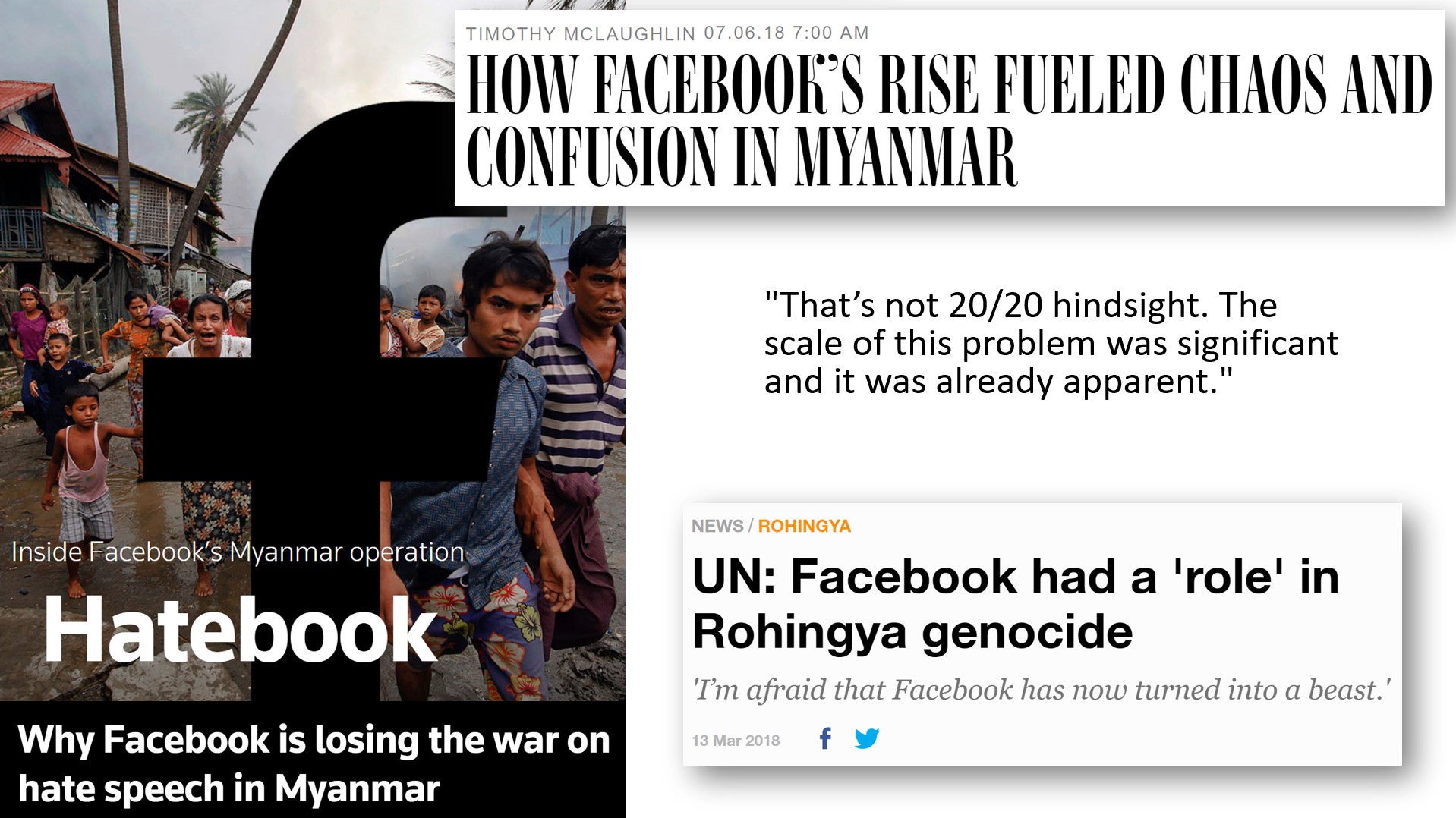
重要的是要明白,种族灭绝并非凭空出现。它是逐渐升级的。从2013年起,人们就警告高管,Facebook在缅甸被如何用来煽动暴力和非人化一个少数民族。在2013年、2014年和2015年,人们发出了警告,但他们没有被倾听。
Facebook在解决这些问题上投入的资源非常少,这一点可以从2015年初他们只有两名会说缅甸语的合同工看出,那年他们只多雇了两人。与缅甸会说缅甸语的用户数量相比,这是一个微不足道的数字。Facebook在这方面投入的资源非常少(对比一下为了避免罚款,Facebook在德国迅速雇佣了一千多名内容审核员的情况)。
这种模式我们一次又一次看到:系统影响最深的人群通常最早发现问题,但他们的话没有人听,也没有有效的途径来发出警报。他们也最了解解决伦理风险所需的干预措施。受影响最大的人群拥有参与和赋权的渠道至关重要。
实用资源
ICML 2020的机器学习参与式方法研讨会非常精彩。研讨会的组织者强调,机器学习系统的设计者对系统拥有远超受影响个体的权力。即使在算法公平性或以人为中心的机器学习领域,伦理工作通常侧重于中心化解决方案,这可能进一步增强系统创建者的权力。研讨会组织者呼吁采用更民主、合作和参与性的方法。
我想与大家分享一些实用资源。圣克拉拉大学的Markkula应用伦理中心在线提供了一系列关于伦理与技术实践的资源,我特别喜欢他们的科技伦理工具包。这是一套您可以在组织内实施的实践方法。例如,工具3是“扩大伦理圈”,这涉及定期预留时间,确保您仔细考虑所有直接受到系统影响的利益相关者,以及将以重大方式间接受到影响的人。这包括询问我们是否只是想当然地认为某些人的技能、经验和价值观,而不是真正咨询过他们。工具包详细说明了关于这一点要问的问题和要注意的事项。

关于这一点,另一个有用的资源是华盛顿大学科技政策实验室的多元声音指南。除了学术论文外,他们还提供了一份实用的操作指南,介绍如何组织那些代表性不足但其意见您需要的群体的小组。他们提供的例子包括前囚犯小组、不开车的人小组以及极低收入人群小组。
数据不是用来堆砌的砖块,不是用来钻取的石油
总之,仅靠可解释性是不够的;我们需要可操作的补救措施和可争议性。公平性是不够的;我们需要正义。受系统影响最深的人群需要参与和赋权的渠道。

这些都是非常困难的问题,但通往解决方案的一些步骤是:
- 确保您有方法快速识别、报告和处理错误
- 提供及时且有意义的申诉途径
- 纳入与经常被忽视的声音的咨询(且不仅仅是象征性的)
- 在设计产品、流程和技术时考虑可争议性
- 招聘、留任和晋升中的多样性(多样性包括国籍和语言)
最后,我想引用我非常喜欢的AI研究员Inioluwa Deborah Raji的一段话:“但数据不是用来堆砌的砖块,不是用来钻取的石油,不是用来开采的黄金,不是用来收割的机会。数据是人类,需要被看见,也许被爱,希望被关怀。”
我的演讲视频版本可在此处观看。
进一步阅读/观看
您可能也感兴趣
- NLP的新时代 | SciPy 2019 | Rachel Thomas:我在SciPy 2019上发表的主题演讲,紧随GPT-2发布之后,内容关于语言模型的技术进展和伦理风险
- 11个关于AI伦理的短视频:我为fast.ai深度学习课程制作的关于机器学习伦理的短视频
- 对指标的依赖是AI面临的一个根本挑战:我与David Uminsky共同撰写的学术论文,关于AI可能过于擅长优化指标以及这可能带来的问题