摘要:最近在针对多项选择题科学考试问题微调一个大型语言模型(LLM)时,我们观察到了一些非常不寻常的训练损失曲线。特别是,模型似乎在只看到数据集中的示例一次后就能够快速记忆它们。这一惊人的壮举与大多数关于神经网络样本效率的先验认知相悖。对这一结果感到好奇,我们进行了一系列实验来验证并更好地理解这一现象。现在还处于早期阶段,但实验支持模型能够快速记住输入的假设。这可能意味着我们必须重新思考我们如何训练和使用大语言模型。
神经网络如何学习
我们通过向神经网络分类器展示输入和输出的示例来训练它们,然后它们学习根据输入预测输出。例如,我们展示狗和猫的图片示例,以及它们的品种,然后它们学习从图像中猜测品种。更精确地说,对于一个可能的品种列表,它们输出对每个品种概率的猜测。如果不确定,它将猜测每个可能的品种概率大致相等;如果高度确定,它将猜测其预测品种的概率接近1.0。
训练过程包括将训练集中的每一张图片连同正确的标签展示给网络。完整过一遍所有输入数据称为一个“周期”(epoch)。我们需要提供大量的训练数据示例,模型才能有效学习。
在训练过程中,神经网络试图降低损失,损失(粗略地说)是衡量模型出错频率的指标,其中高度确定的错误预测受到最大的惩罚,反之亦然。我们在训练集的每个批次后计算损失,并且不时地(通常在每个周期结束时)计算模型没有从中学习的一批输入的损失——这称为“验证集”。以下是我们在训练11个周期时的实际情况:
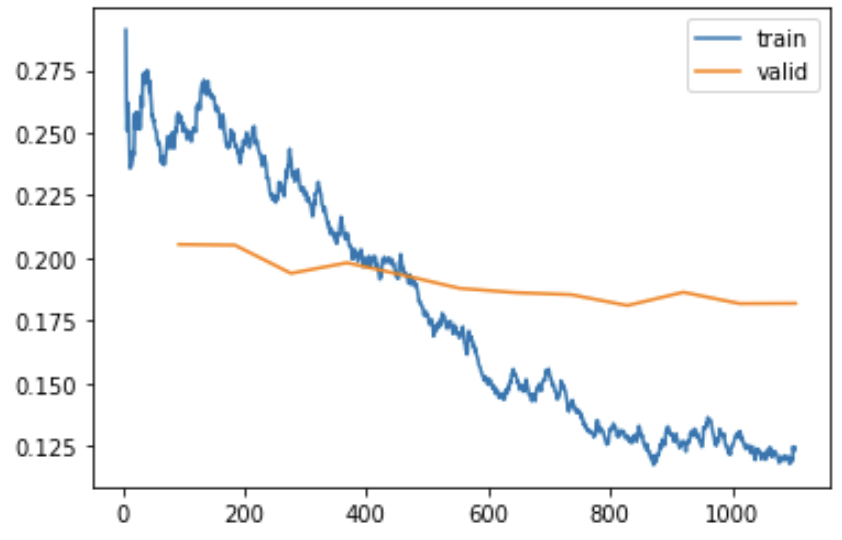
如你所见,训练损失逐渐(且有波动地)相对快速地改善,随着时间推移而减慢,而验证损失改善得更慢(如果训练时间更长,它最终会完全趋于平缓,然后最终变差)。
从图中看不出周期在哪里开始和结束,因为模型需要很多周期才能学会任何特定图像的样子。几十年来,这一直是神经网络的一个基本限制——它们学习任何东西都需要非常长的时间!实际上,这是一个活跃的研究领域,探讨为什么神经网络如此“样本效率低下”,特别是与儿童学习方式相比。
一个非常奇怪的损失曲线
我们最近一直在参与Kaggle LLM科学考试竞赛,该竞赛“挑战参赛者回答由大型语言模型编写的困难科学问题”。例如,这是第一个问题:
以下哪项陈述准确描述了修正牛顿动力学(MOND)对星系团中观察到的“缺失重子质量”差异的影响?
- MOND理论通过假设存在一种称为“模糊暗物质”的新物质形式,从而减少星系团中观察到的缺失重子质量。
- MOND理论将星系团中观察到的缺失重子质量与测得的速度弥散之间的差异从约10倍增加到约20倍。
- MOND理论通过证明星系团中先前被认为是暗物质的缺失重子质量以中微子和轴子的形式存在来解释这一现象。
- MOND理论将星系团中观察到的缺失重子质量与测得的速度弥散之间的差异从约10倍减少到约2倍。
- MOND理论通过提出一种不需要暗物质存在的新引力数学公式,从而消除了星系团中观察到的缺失重子质量。
对于在家参与的读者,正确答案显然是D。
值得庆幸的是,我们无需依靠对修正牛顿动力学的知识来回答这些问题——相反,我们的任务是训练一个模型来回答这些问题。当我们向Kaggle提交模型时,它将根据数千个我们无法看到的“保留”问题进行测试。
我们使用朋友 Radek Osmulski 创建的一个大型问题数据集对模型进行了3个周期的训练,看到了以下最出乎意料的训练损失曲线:
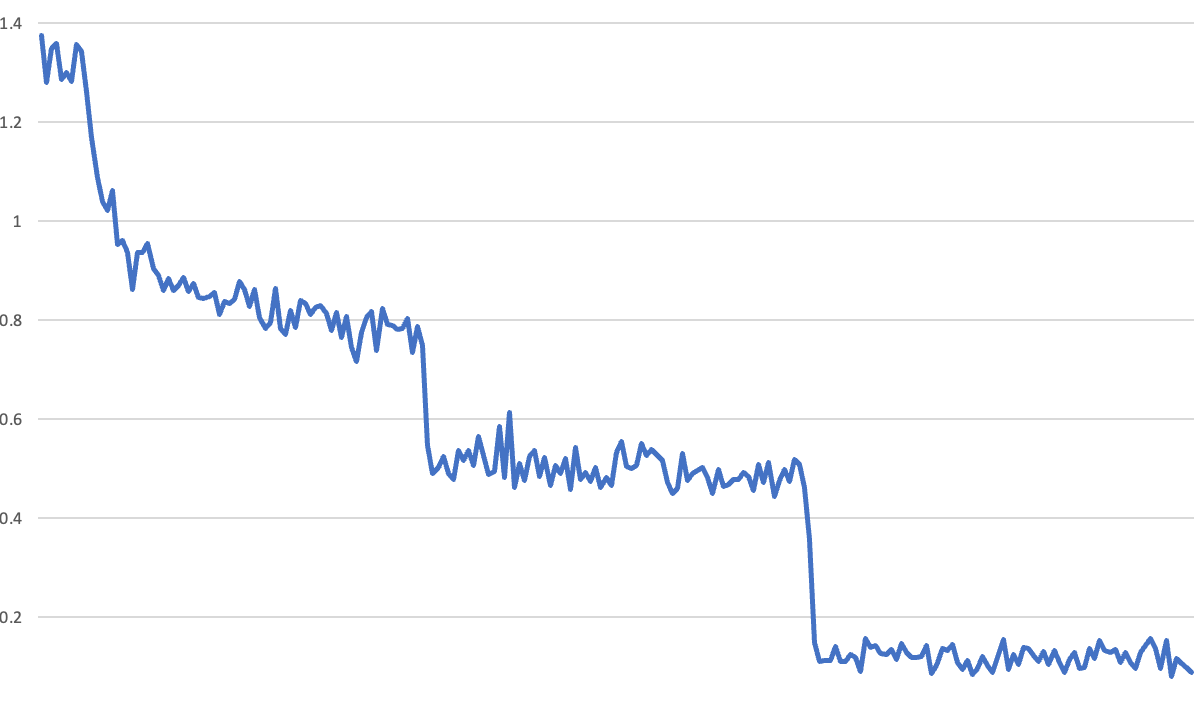
这里的问题是你可以清楚地看到每个周期的结束——损失突然向下跳跃。我们以前见过类似的损失曲线,并且它们总是由于一个 bug。例如,很容易意外地让模型在评估验证集时继续学习——这样在验证之后模型突然看起来好很多。所以我们开始在训练过程中寻找这个 bug。我们使用的是 Hugging Face 的 Trainer,所以我们猜测那里一定有一个 bug。
当我们开始逐步查看代码时,我们也在 Alignment Lab AI Discord 上询问了其他开源开发者是否见过类似的奇怪训练曲线,几乎每个人都说“是”。但所有回应的人也都使用了 Trainer,这似乎支持了我们关于该库存在 bug 的理论。
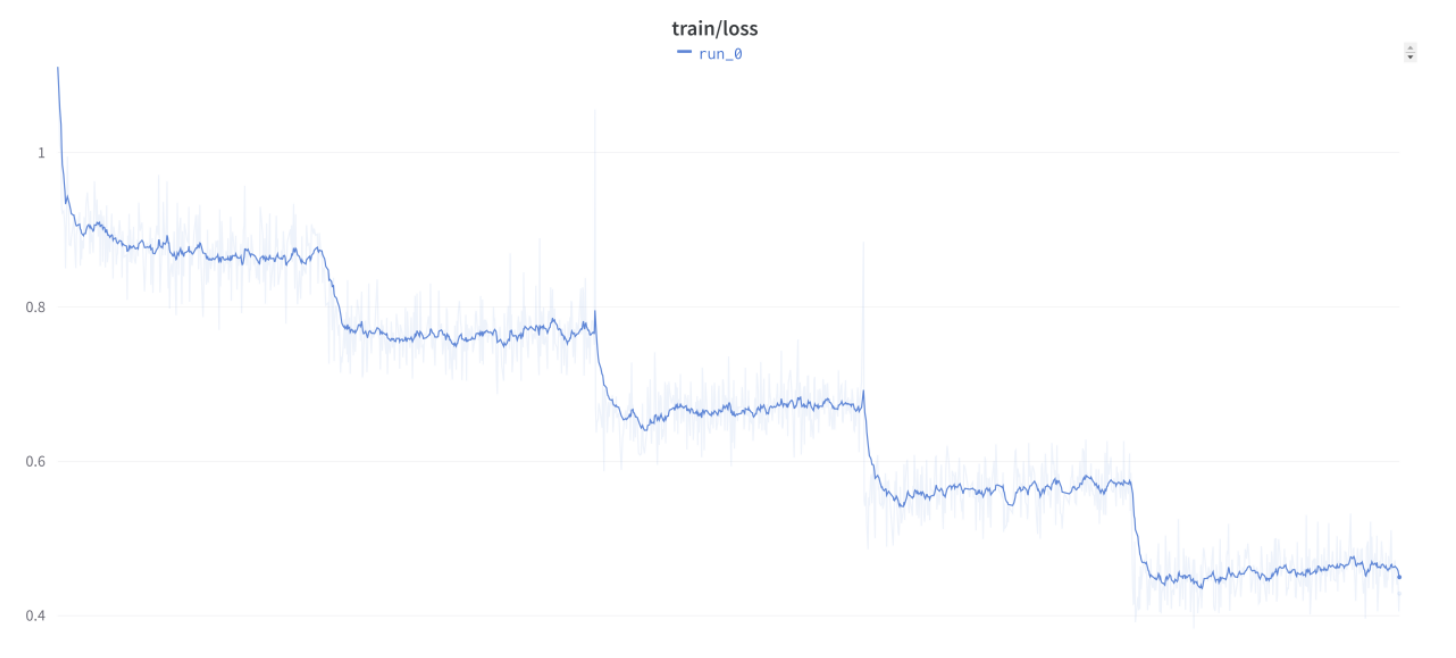
但后来 Discord 上的 @anton 告诉我们,他使用自己的简单自定义训练循环也看到了这条曲线:
……他还向我们展示了这张同样令人极为惊讶的验证损失曲线:
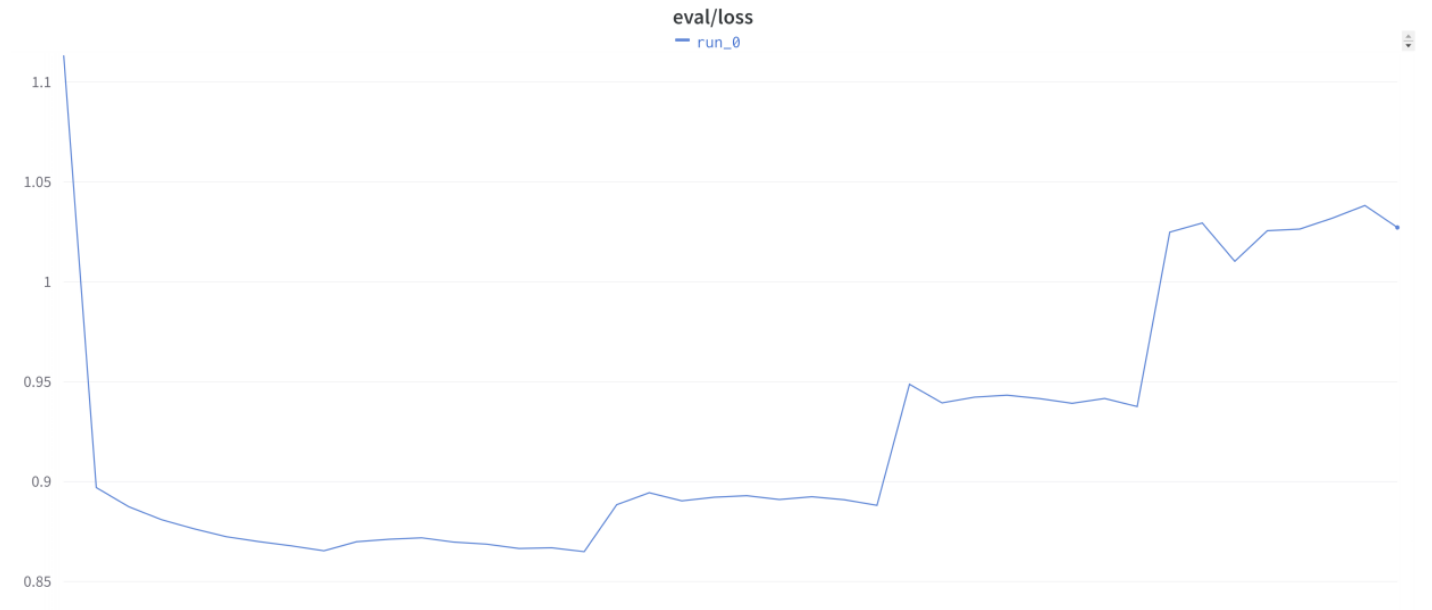
然后我们开始听到越来越多的 Discord 朋友说他们见过类似的奇怪行为,包括在不使用 Trainer 的情况下。我们想知道这是否是我们使用的 LoRA 方法特有的怪癖,但我们听说在进行完全微调时也看到了同样的模式。事实上,在 LLM 微调社区中,这基本上已经是常识了,这就是做这类工作时的常态!……
深入探究
我们一直从开源同事那里听到的假说是,这些训练曲线实际上显示的是过拟合。这最初看来是相当不可能的。这意味着模型仅通过一两个示例就学会了识别输入。如果你回顾我们展示的第一个曲线,你可以看到在第一个周期后损失从0.8下降到0.5,然后在第二个周期后从0.5下降到0.2以下。此外,在第二和第三个周期期间,它根本没有真正学习到任何新东西。因此,除了在第一个周期开始时的初始学习外,几乎所有明显的学习(根据这个理论)都是对训练集的记忆,而且每行只有3个示例!此外,对于每个问题,它只获得微小的信号:它对答案的猜测与真实标签的比较。
我们进行了一个实验——使用以下学习率调度表,对我们的 Kaggle 模型进行了两个周期的训练:
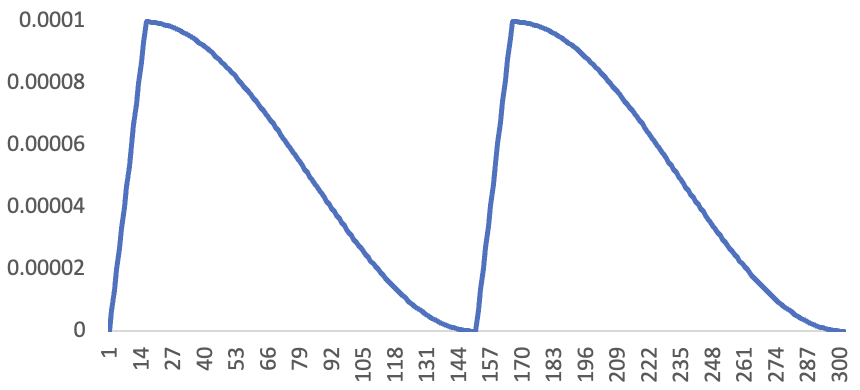
如今这种调度方式不太常见,但它是由 Leslie Smith 创建的一种取得了很大成功的方法,他在2015年的论文《神经网络训练的循环学习率》中对此进行了讨论。
以下是我们看到的结果,看起来很疯狂的训练和验证损失曲线:
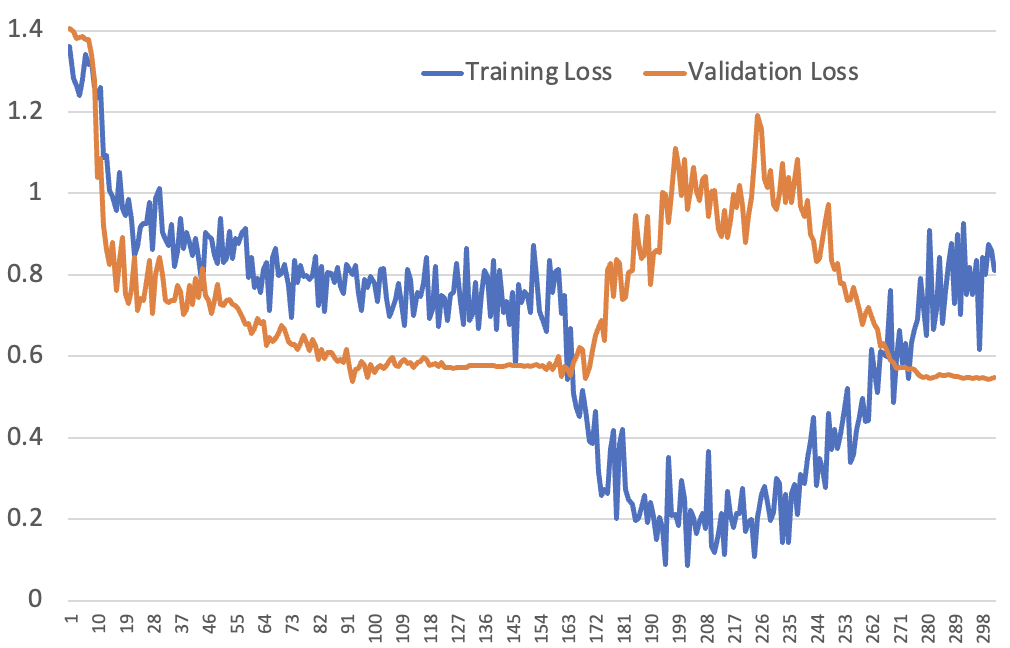
到目前为止,我们唯一能完全解释这张图的是这个假说是正确的:模型正在快速学习识别示例,即使只看到它们一次。让我们依次分析损失曲线的每个部分……
看第一个周期,这看起来像一条非常标准的损失曲线。我们在周期的前10%中进行学习率预热,然后按照余弦调度逐渐降低。一旦学习率达到稳定状态,训练和验证损失迅速下降,然后随着学习率下降和“快速获益”的捕捉而减慢。
第二个周期是有趣的地方。我们在周期开始时没有重新打乱数据集,所以第二个周期的第一批数据是在学习率仍在预热时看到的。这就是为什么我们没有看到像我们在展示的第一个损失曲线中从周期2到周期3那样的即时阶跃变化——这些批次只在学习率较低时被看到,所以它学到的东西不多。
在周期前10%接近尾声时,训练损失骤降,因为在第一个周期看到这些批次时学习率很高,并且模型已经学会了它们的样子。模型很快学会了它可以非常自信地猜测正确答案。
但在此期间,验证损失会增加。这是因为尽管模型变得非常自信,但它在预测方面并没有实际变得更好。它只是简单地记忆了数据集,但没有提高泛化能力。过度自信的预测会导致验证损失变差,因为损失函数会更严重地惩罚更确信的错误。
曲线的末端是事情变得特别有趣的地方。训练损失开始变差——这确实不应该发生!事实上,我们俩都不记得在使用合理的学习率时见过这种情况。
但实际上,这在记忆假说下完全合理:这些是模型在学习率再次下降时看到的批次,因此它无法有效地记忆它们。但模型仍然过度自信,因为它刚刚几乎完全正确地处理了一大堆批次,并且还没有适应它现在正在看到没有机会学得那么好的批次这一事实。
它逐渐重新校准到更合理的置信度水平,但这需要一段时间,因为学习率越来越低。随着它重新校准,验证损失再次下降。
在我们的下一个实验中,我们尝试了对3个周期进行1cycle训练,而不是CLR——也就是说,我们在训练开始时对10%的批次进行了一次学习率预热,然后按照余弦调度在剩余批次中衰减学习率。之前,我们对每个周期都进行了单独的预热和衰减循环。此外,我们增加了 LoRA rank,导致学习速度变慢。以下是结果损失曲线:
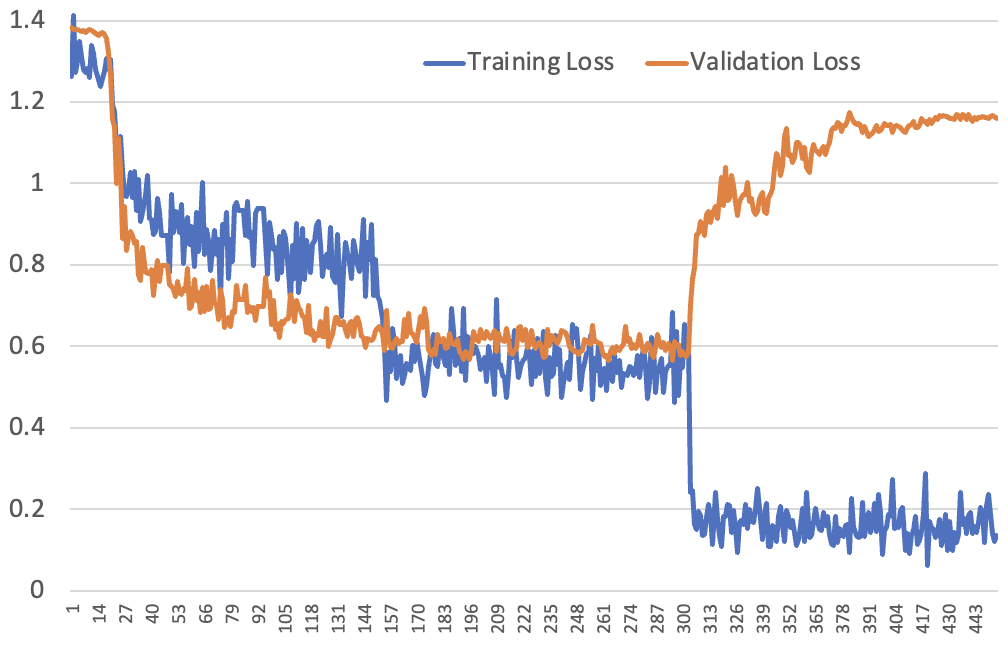
曲线的形状大体符合我们基于先前讨论的预期,除了一点:验证损失在第二个周期没有跳升——直到第三个周期我们才看到那个跳升。然而之前,在第二个周期时训练损失大约在0.2,这只有在模型做出高度自信的预测时才可能发生。在 1cycle 的例子中,直到第三个周期模型才做出如此自信的预测,而我们直到那时才看到验证损失的跳升。
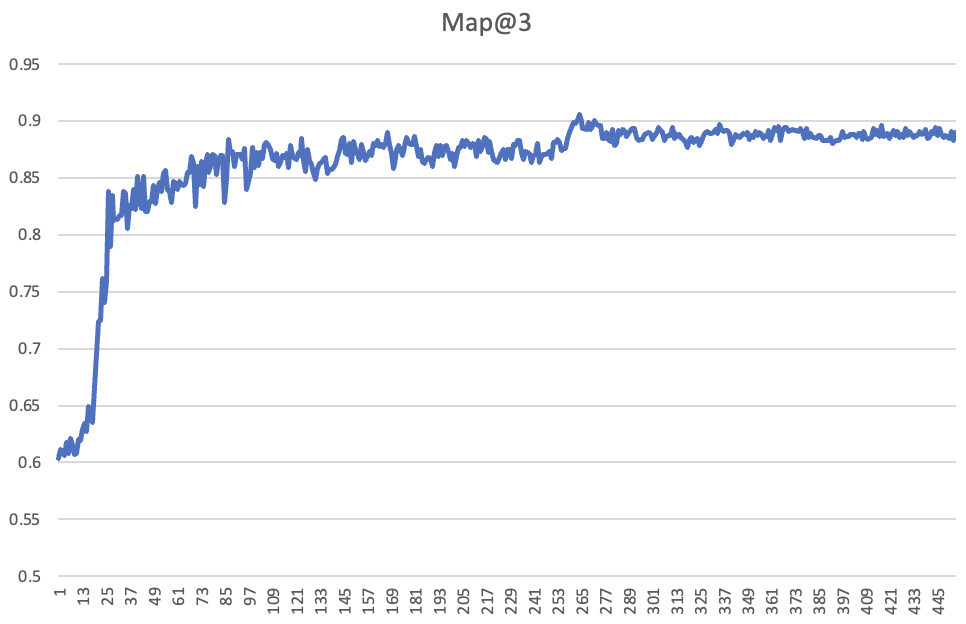
需要注意的是,验证损失变差并不意味着我们在实践中出现了过拟合。我们通常关心的是准确率,并且模型过于自信也没关系。在 Kaggle 竞赛中,排行榜使用的评估指标是前3平均精度 (MAP@3),这是模型做出的前3个多项选择预测的准确率。以下是上一张图所示的 1cycle 训练运行中每批次的验证准确率——如你所见,它一直在提高,即使验证损失在最后一个周期变差了。
如果您有兴趣深入了解,请查看这份报告,其中 Johno 分享了一些额外示例的日志,以及一个笔记本,供那些想亲自查看此效果的人使用。
记忆假说如何可能是真的?
没有一条基本定律规定神经网络不能从单个示例中学会识别输入。这只是研究人员和实践者在实践中普遍发现的情况。需要很多示例是因为我们试图使用随机梯度下降(SGD)来导航的损失曲面过于崎岖不平,无法一次跳跃很远的距离。然而,我们确实知道,有些东西可以使损失曲面更平滑,例如使用残差连接,如经典的《可视化神经网络的损失地形》论文(Li 等人,2018)所示。
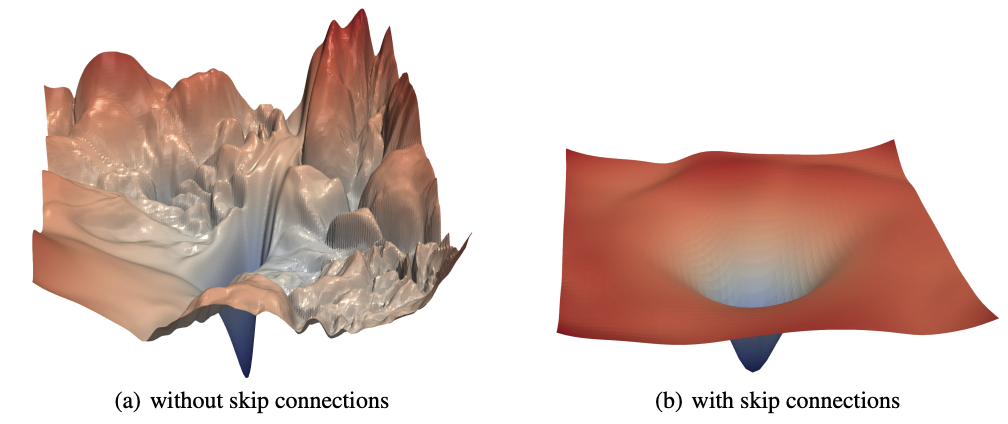
很有可能,预训练的大型语言模型在接近最小损失的区域具有极其平滑的损失曲面,并且开源社区中的许多微调工作都发生在这个区域。这是基于对微调通用语言模型原始开发的基本前提。这些模型最初由我们中的一位(Jeremy)和 Sebastian Ruder 在2018年的ULMFiT 论文中进行了记录。Jeremy 最初构建 ULMFiT 算法的原因是因为,任何能够很好地完成语言建模(即预测句子的下一个词)的模型,似乎都必须在内部构建一个丰富的抽象和能力层次结构。此外,Jeremy 相信,只需少量微调,这个层次结构就可以很容易地适应于解决需要类似能力的其他任务。ULMFiT 论文首次证明了事实确实如此。
今天的大型语言模型比 ULMFiT 中研究的模型大了几个数量级,它们一定拥有更丰富的抽象层次结构。因此,微调其中一个模型,例如,回答关于科学的多项选择题,很大程度上可以利用模型中已有的能力和知识。这只是以正确的方式呈现正确的部分的问题。这不应该需要大量权重进行调整。
基于此,预训练的语言模型加上一个小的随机分类头,可能处于权重空间中损失曲面平滑清晰地指向良好权重配置方向的区域,这或许不足为奇。而且,当我们使用 Adam 优化器时(就像我们做的),拥有一个一致且平滑的梯度会导致有效的动态学习率不断上升,使得步长可以变得非常大。
接下来怎么办?
拥有一个学习非常快的模型听起来很棒——但实际上,这意味着很多关于如何训练模型的基本思想可能会被颠覆!当模型训练非常慢时,我们可以长时间地训练它们,使用各种各样的数据,进行多个周期,并且我们可以期望我们的模型会从我们提供的数据中逐渐提取出可泛化的信息。
但是当模型学习如此之快时,灾难性遗忘问题可能会突然变得更加突出。例如,如果一个模型看到十个非常常见关系的例子,然后看到一个不太常见的反例,它很可能会记住这个反例,而不是仅仅稍微降低对原始十个例子的记忆权重。
现在也可能出现的情况是,数据增强对于避免过拟合的作用减弱了。由于大型语言模型在提取所给信息表示方面非常有效,通过释义和反向翻译来混合数据可能不会产生太大影响。模型实际上无论哪种方式都会获得相同的信息。
也许我们可以通过大幅增加使用诸如 dropout(这已经在 LoRA 等微调技术中有所使用)或 随机深度(这似乎尚未在自然语言处理中得到显著应用)等技术来缓解这些挑战。
或者,也许我们只需要注意在整个训练过程中使用丰富混合的数据集,这样我们的模型就不会有机会遗忘。例如,Llama Code 确实遭受了灾难性遗忘(当它在代码方面变得更好时,在其他方面却变得更糟),但它仅用10%的非代码数据进行了微调。也许通过接近50/50的混合比例,可以在不失去现有能力的情况下,同样擅长编码。
如果您提出了任何替代假设,并能够验证它们,或者如果您发现任何实证证据表明记忆假说是错误的,请务必告知我们!我们也渴望了解该领域的其他工作(如果我们未能在此引用任何先前的工作,敬请谅解),以及关于我们应如何(如果需要的话)根据这些观察调整训练和使用这些模型的任何想法。我们将关注这条推特线程下的回复,因此如果您有任何想法或问题,请在此回复。