本文最初发布于 rachel.fast.ai,Rachel 在此撰写了她作为 AI 研究员重返校园学习免疫学的经历。
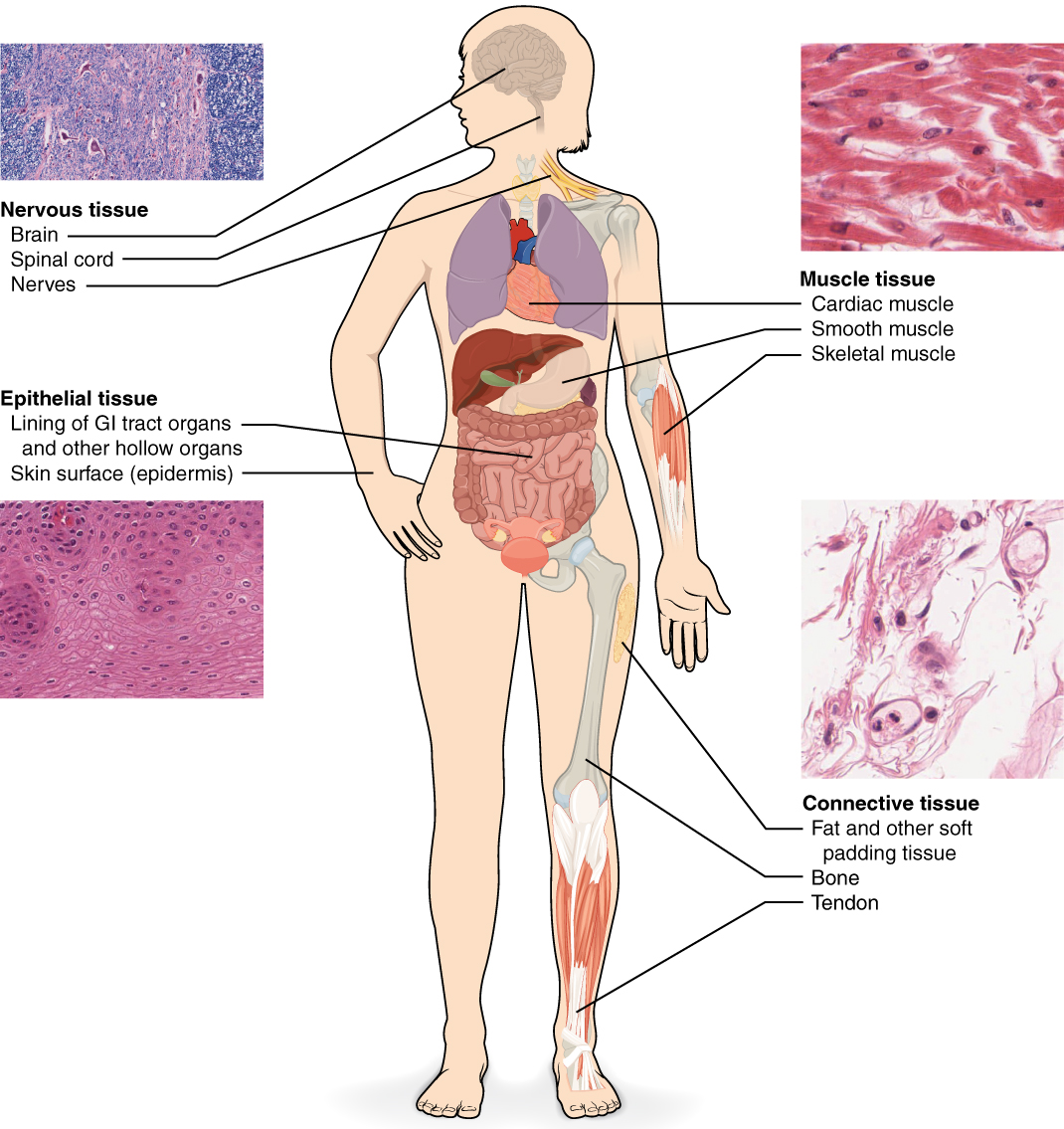
下面的淡紫色图像显示的是 乳腺组织。医生们可能希望利用这些图像回答许多问题:他们可能想知道是否存在肿瘤。如果存在肿瘤,医生会想对肿瘤进行分期,预测患者对治疗的反应可能性,并检测肿瘤是否已从其他器官扩散。
所有这些问题现在人们都在用机器学习来解决。它们属于 计算病理学 领域,常缩写为 CPath。在过去一年里,有两个 CPath AI 模型发布并取得了最先进的结果。在这里,我将介绍这个领域、这些模型的功能以及未来的一些主要挑战。

CPath 基础模型
关于如何构建更准确的 CPath 模型有一个强大的想法。与其在一个单一类型的组织和单一任务(例如,识别乳腺组织中的癌症)上训练模型,不如在来自许多不同器官(乳腺、淋巴结、肺、前列腺、心脏等)的组织图像上训练模型,并在多个不同任务上训练模型(识别癌症、确定癌症的分期和亚型、细胞分割和预测治疗结果)。从一个数据集或一个任务中学到的模式很可能泛化到其他任务。
这类模型被称为 CPath 基础模型。一般来说,基础模型是一种机器学习模型,它在一个足够多样化的大型数据集上进行训练,然后可以适应一系列下游任务。这个想法在语言模型领域被普遍使用,例如 Chat-GPT 和 Claude.ai。语言基础模型在多种语言任务上进行训练,旨在泛化到不同的文本语料库(例如维基百科、Reddit 帖子、学术论文、在线对话、新闻文章等)。训练用于识别各种不同图片的 ImageNet 模型通常作为图像的基础模型。基础模型在语言和更普遍图像领域的成功是我们可以期待病理学基础模型也同样有用的一个关键原因。
2024年发布了两个值得注意的 CPath 基础模型:Prov-GigaPath 和 UNI。这两个模型在数十个病理学任务上都取得了最先进的性能(尽管它们之间没有直接比较)。另一篇 相关论文(来自 Kaiko.ai)研究了数据集大小和模型大小对 CPath 模型性能的影响。
学习词汇
医学充满了术语和专业词汇。病理学是指研究疾病的学科。它是一个广阔的领域,可以包括从解剖尸体到分析血液样本的一切。计算病理学的一个重点是分析和解释全玻片图像(WSIs),在某些情况下结合患者的伴随元数据。全玻片图像是指完整的显微镜载玻片,尽管在许多情况下,感兴趣的区域(例如特定的癌细胞或发炎细胞)可能要小得多,仅占据载玻片的一部分。
机器学习(ML)是人工智能(AI)的一个子领域,涉及从过去的数据中学习,并且在病理学中正越来越多地取得巨大成功。大多数计算病理学 ML 模型的重点是组织图像,也就是显微镜载玻片上的图像。这也是本文的重点。
如此多的任务!
CPath 模型可以在许多不同的基准上进行测试。这些基准涉及大量数据集:与身体不同部位相关,具有不同大小和不同用途。它们还涉及多种任务,包括二分类、图像分割和结果预测。Prov-GigaPath 在其评估的 26 个任务中的 25 个上取得了最先进的性能,UNI 在 34 个不同任务上取得了最先进的性能。在这里,我将仅举其中 3 个任务的例子。
任务:前列腺癌细胞分级
在20世纪60年代,病理学家 Donald Gleason 博士提出了一种分级量表,用于对从正常细胞发展为前列腺癌的细胞进行评级。格里森分级系统(Gleason Grading system)至今仍被广泛使用,被认为是预测前列腺癌患者预后的有力指标。一个主要的医学图像会议 (MICCAI) 在2022年 举办了一场竞赛,鼓励研究人员创建算法,在给定前列腺组织图像的情况下确定格里森分级。
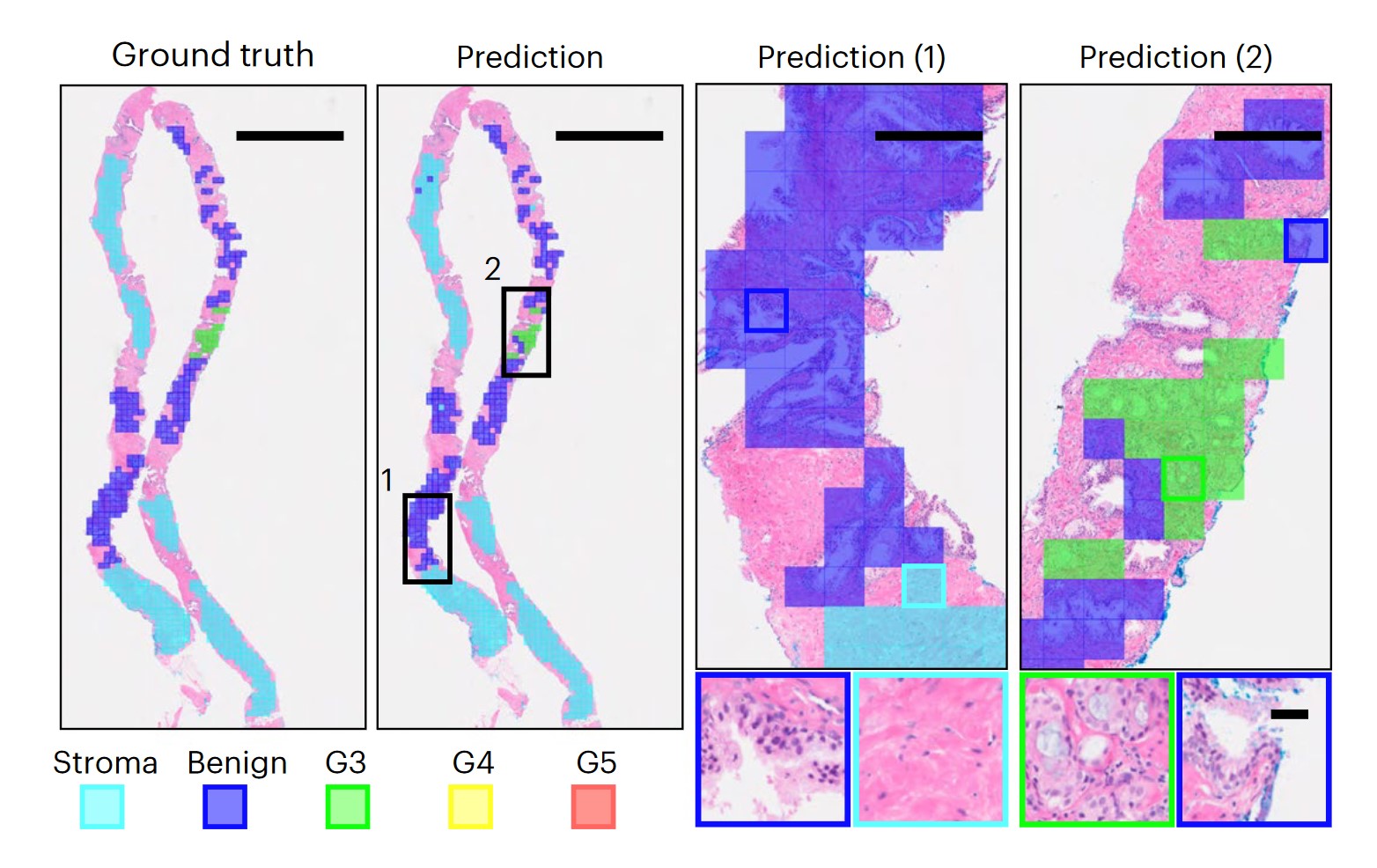
前列腺组织以粉色显示,并根据其在格里森量表上的分级,将切片块着色。
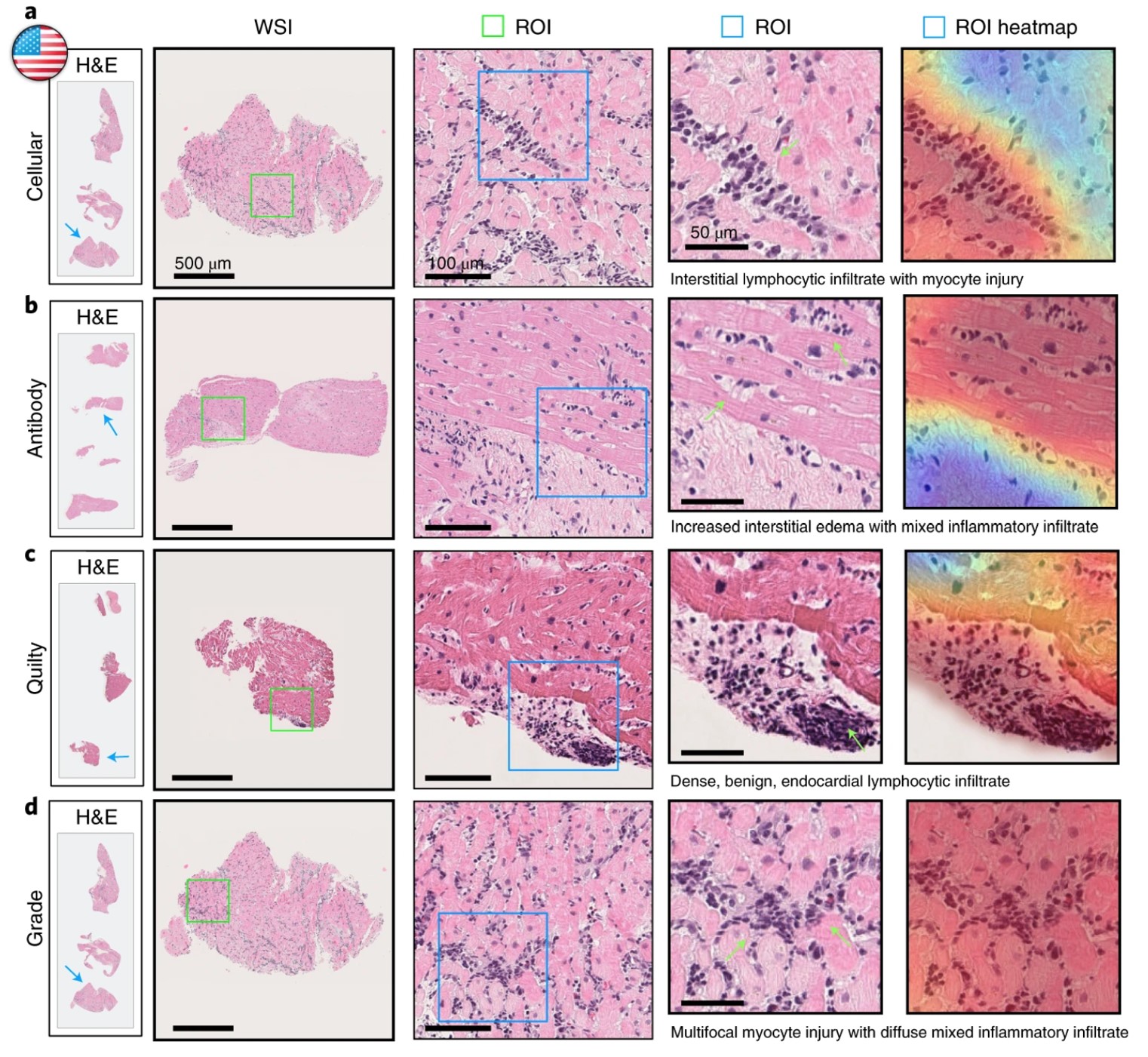
任务:识别心脏移植后的早期排斥迹象
对于接受心脏移植的患者来说,排斥反应是主要的死亡原因。由于早期排斥反应可能没有症状,患者在移植后 1-2 年内接受频繁活检是标准做法。这些活检被称为心内膜心肌活检(EMB),因为它们从心脏(cardial)肌肉(myo)的内膜(endo)中取下一小块组织样本。准确解释这些活检的结果是一个关键问题。低估排斥的可能性可能导致危险的治疗延误,而高估则可能导致不必要的担忧和不必要的随访或治疗。经验丰富的病理学家对取样组织的评估比许多其他任务(如癌症诊断)具有更高的变异性。深度学习正被用于解决这一任务,应用在诸如 心脏排斥评估神经网络估计器 (CRANE) 和 CPath 基础模型 UNI 等模型中。
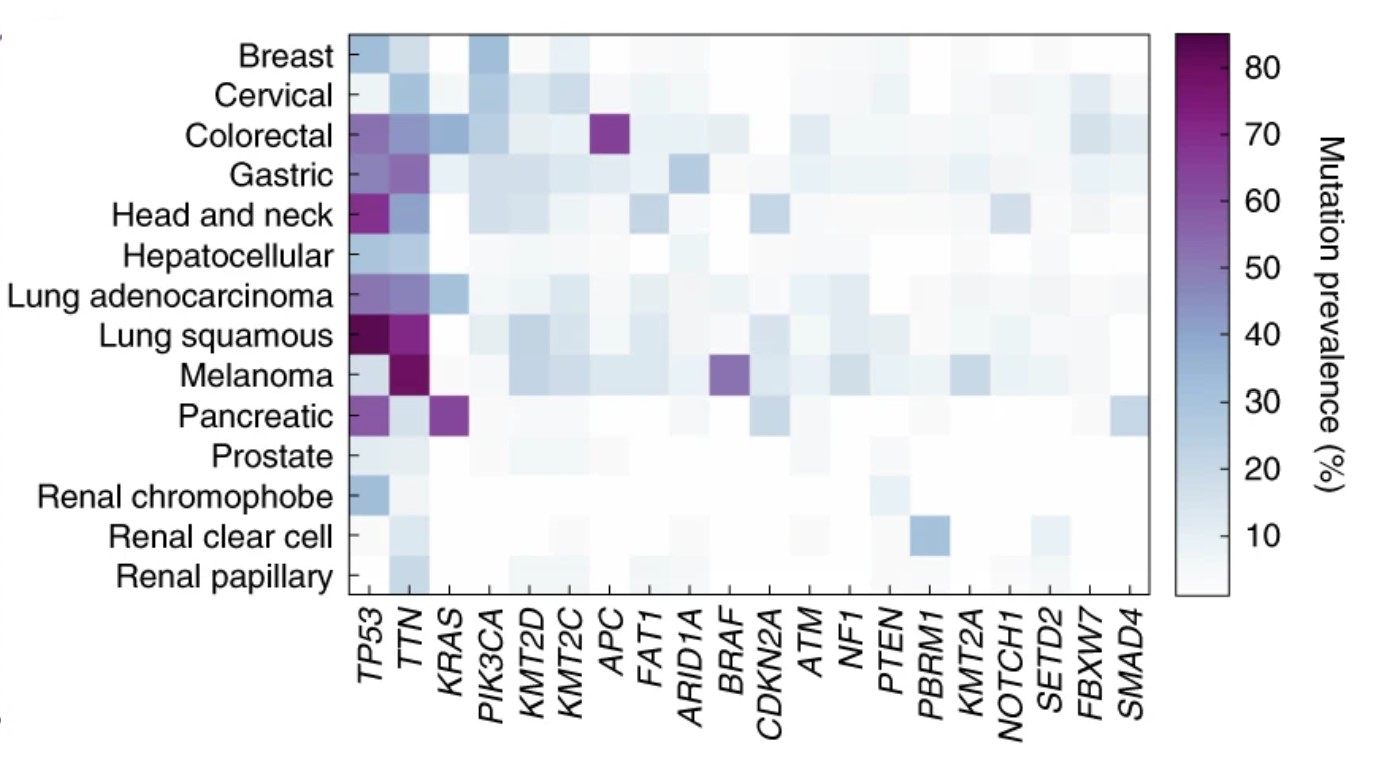
任务:癌症中的基因突变
对于肿瘤中的几种常见基因突变,存在 已知靶向这些突变的特定药物。这在临床治疗中具有直接应用。由于基因突变可以改变细胞的形态和功能,因此可以合理地预期,这些信息可以从癌细胞的图像中推断出来。已经构建了深度学习模型,用于从组织切片中识别基因突变。使用计算方法的优点在于,随着越来越多的相关基因突变和分子生物标志物被发现,它可以进行扩展。已经为此构建了 针对特定任务的模型,这也是基础模型可以测试的任务之一。
我们需要更多数据
CPath 基础模型领域的一个关键挑战是收集足够的训练数据。癌症基因组图谱 (TCGA) 是美国国家癌症研究所于2006年发起的一项宏大项目。在长达12年的时间里,共采集了11,000多名患者的样本,涵盖33种不同的癌症类型,并且所有数据都已公开。尽管这是一个丰富且有用的数据集,但我们审阅的所有3篇论文都得出结论,TCGA 不足以用于构建有效的基础模型。除了数据量有限外,TCGA 的多样性也有限,主要包含来自癌症原发部位的切片,而不包括转移癌或不同类型的组织。
Kaiko.ai 的研究人员 测试了模型大小和训练数据集大小对性能扩展的影响。虽然他们发现模型大小超出一定点后扩展的必要性有限,但他们发现更大的数据集持续带来性能提升。他们得出结论,TCGA 可能不够大,并分享了构建更大训练集的计划,目前正与欧洲各地的癌症中心合作,为其模型创建数据集。
另外两个 CPath 基础模型的研究人员也得出了关于数据集大小的相同结论,并收集了海量数据集来训练他们的模型。这需要与医疗中心合作。Prov-GigaPath 是由微软研究院和 Providence Genomics 创建的模型,使用了来自 28 个癌症中心(隶属于 Providence Healthcare 公司)的 30,000 名患者的数据。UNI 是由哈佛大学、麻省理工学院和 Broad Institute 的一个团队创建的 cPath 模型,涉及构建 Mass-100K 数据集:该数据集包含来自麻省总医院、布莱根妇女医院和基因型组织表达(GTEx)联盟的、涵盖 20 种组织类型的 100,000 多张全玻片图像。
这些合作以及训练数据集的精心整理目前是构建 CPath 基础模型的关键组成部分。精心整理数据集本身也带来了许多挑战。整合来自不同来源的数据(这些来源通常使用不同的玻片采样和制备协议)可能会引入显著的偏差。
不同的尺度
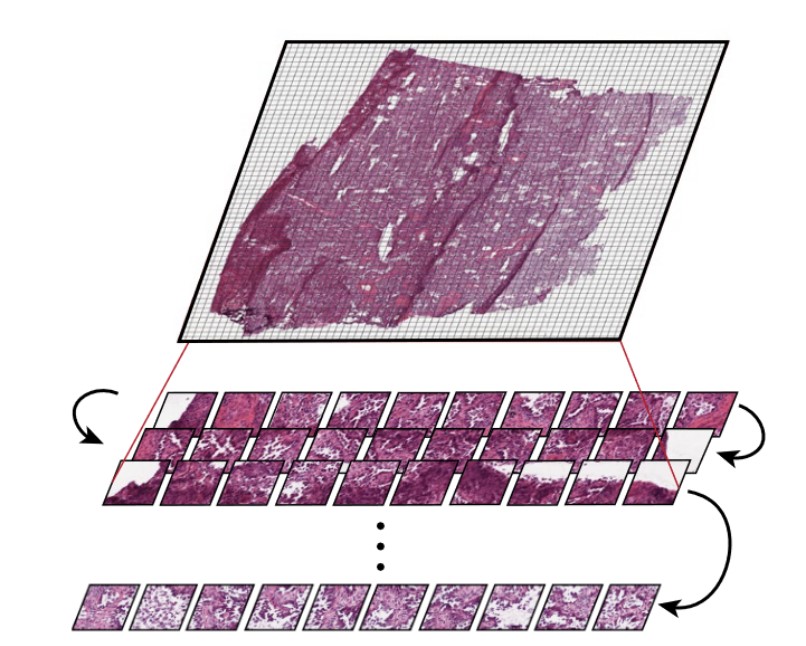
CPath 基础模型面临着捕捉局部模式(玻片内小块区域显示的模式)和跨越整个玻片的全局模式的困难。一个玻片内包含许多小块区域。
一些模型,例如 分层图像金字塔 Transformer(来自 UNI 的几位相同作者),使用分层方法来处理这些多重尺度。
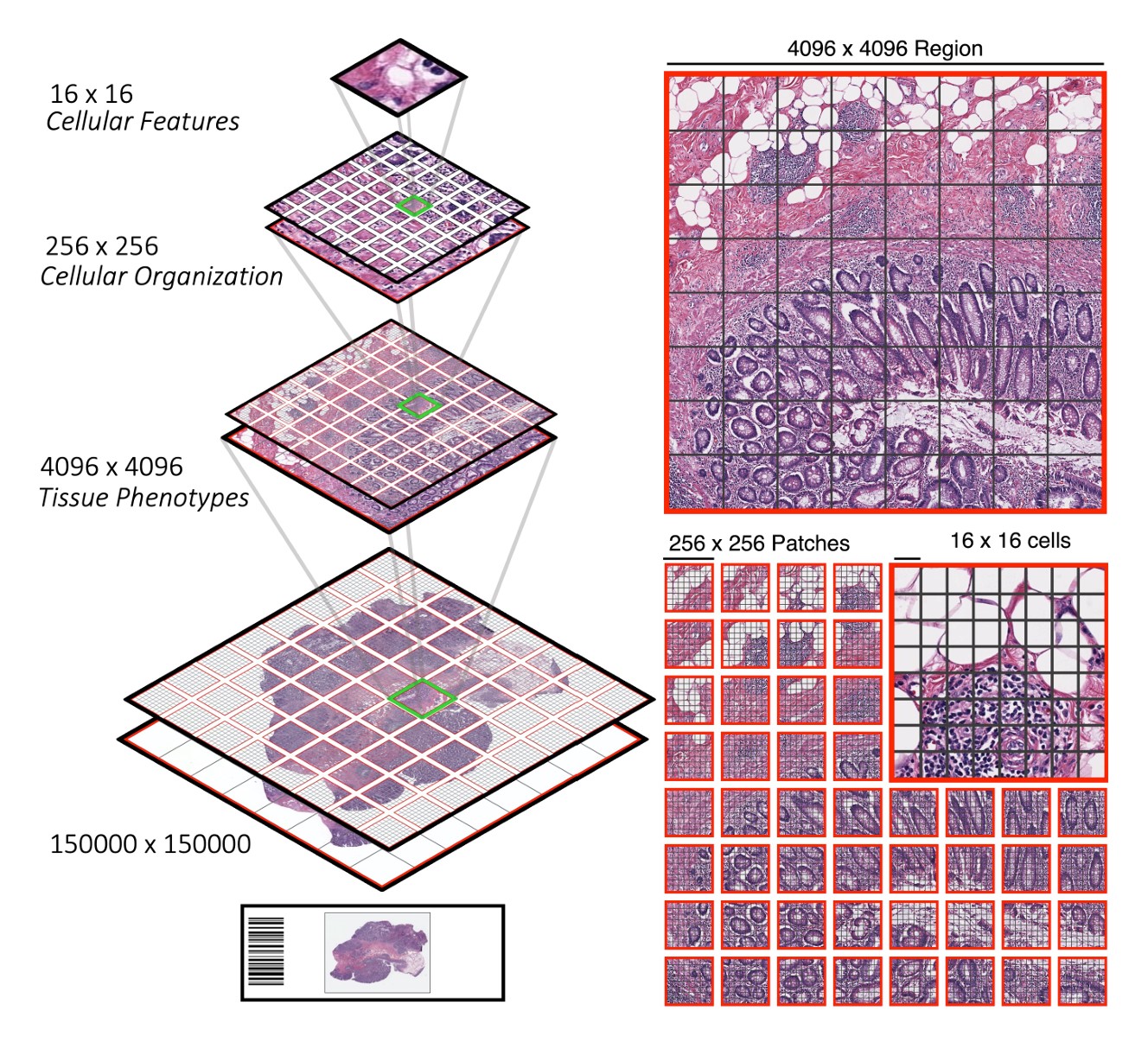
其他模型,例如 Prov-GigaPath,将小块区域视为 token,将小块区域和整个玻片一起编码作为模型输入。Prov-GigaPath 同时使用玻片编码器和小块区域编码器来考虑这两种不同的尺度。
在病理临床中,诊断和治疗决策通常在患者层面做出,而 CPath 模型则经常高度专注于感兴趣区域。在病理学中兼顾多个相关尺度(小块区域、全玻片和患者层面)是 CPath 模型需要平衡的一个考量。
展望未来
CPath 领域仍处于早期阶段,存在许多发展机会,包括持续需要大型和多样化数据集、进一步优化模型训练的方法、之前关注较少的任务,以及将模型整合到临床工作中的困难。正如 kaiko.ai 论文的作者 所写,“我们正处于开发真正基础的病理学基础模型的开端。”这些模型在数十个基准上取得了最先进的结果,这是一个充满希望的迹象,但它们何时以及如何用于临床设置仍有待观察。